{kind=link}

Giant Language Fashions (LLMs) have develop into more and more important in synthetic intelligence, notably in duties requiring no prior particular coaching information, referred to as Zero-Shot Studying. These fashions are evaluated on their capability to carry out novel duties and the way effectively they generate outputs in a structured format, equivalent to JSON. Structured outputs are crucial for creating Compound AI Programs involving a number of LLM inferences or interactions with exterior instruments. This analysis investigates the potential of LLMs to comply with particular formatting directions for JSON outputs, a vital requirement for integrating these fashions into advanced AI methods.
A major problem in using LLMs in superior AI methods is guaranteeing that their outputs conform to predefined codecs, important for seamless integration into multi-component methods. When outputs fail to fulfill these strict formatting necessities, it may possibly trigger vital disruptions within the total operation of the system. This downside is especially pronounced when LLMs use different instruments or fashions, necessitating exact and constant output codecs. The analysis addresses this subject by evaluating the LLMs’ capability to generate JSON outputs that adhere to particular format directions.
Present approaches to make sure the correctness of structured outputs embrace strategies like structured decoding, such because the DOMINO algorithm. These strategies are designed to enhance the reliability of JSON output era by implementing stricter constraints throughout the era course of. Nonetheless, these strategies can introduce extra complexity, doubtlessly lowering the pace of inference and complicating the combination of those fashions into current methods. Furthermore, the reliance on structured decoding can intrude with the advantages of immediate optimization and the inherent data encoded inside LLMs, making it difficult to stability accuracy and effectivity.
The analysis staff from Weaviate launched a novel benchmark referred to as StructuredRAG, which consists of six completely different duties designed to evaluate the power of LLMs to generate structured outputs like JSON. The benchmark evaluated two state-of-the-art fashions: Gemini 1.5 Professional and Llama 3 8B-instruct, main LLMs within the area. The researchers employed two distinct prompting methods—f-String and Comply with the Format (FF)—to measure the fashions’ proficiency in following response format directions. These methods had been chosen to discover completely different approaches to prompting, aiming to determine which technique yields higher leads to structured output era.
The researchers performed 24 experiments of their methodology, every designed to check the fashions’ capability to comply with the desired JSON format directions. The experiments coated a variety of output complexities, from easy string values to extra intricate composite objects that embrace a number of information varieties. The success of the fashions was measured by their capability to supply outputs that could possibly be precisely parsed into the requested JSON format. The examine additionally launched OPRO immediate optimization, a method to enhance JSON response formatting with out counting on structured decoding strategies. This strategy focuses on refining the prompts to boost the chance of producing appropriately formatted outputs.
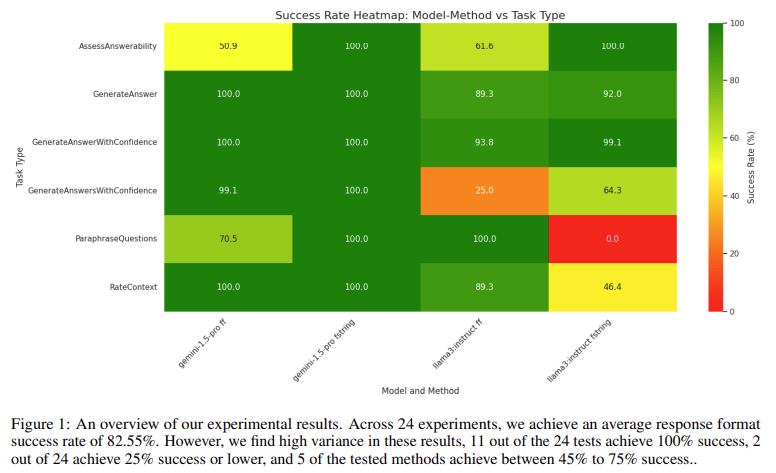
The outcomes of the experiments confirmed that the fashions achieved a mean success charge of 82.55% throughout all duties, with notable variations in efficiency primarily based on the complexity of the duties. Of the 24 duties, 11 achieved a 100% success charge, whereas two had 25% or decrease success charges. Notably, the Gemini 1.5 Professional mannequin outperformed the Llama 3 8B-instruct mannequin, with a mean success charge of 93.4% in comparison with 71.7%. The analysis highlighted that whereas each fashions carried out effectively on easier duties, they struggled with extra advanced outputs, notably these involving lists or composite objects. As an illustration, the Llama 3 8B-instruct mannequin achieved a 0% success charge on a process requiring the output of a listing of strings within the ParaphraseQuestions take a look at and solely a 25% success charge on the GenerateAnswersWithConfidences process when utilizing FF prompting.
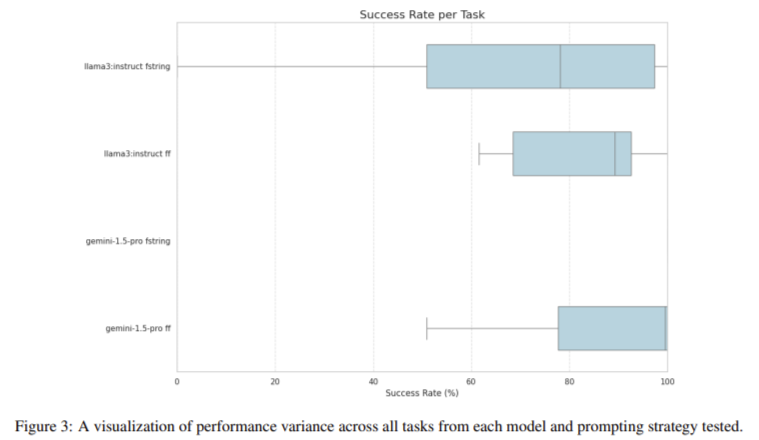
The findings from this examine underscore the numerous variability in LLMs’ capability to generate structured outputs, particularly in more difficult situations. The introduction of the StructuredRAG benchmark offers a beneficial software for evaluating and enhancing the efficiency of LLMs in producing JSON outputs. The examine means that additional analysis is required to discover superior methods, equivalent to ensembling, retry mechanisms, and immediate optimization, to boost the reliability and consistency of structured output era. The researchers additionally indicated that exploring these superior strategies may considerably enhance LLMs’ capability to generate appropriately formatted outputs with out utilizing structured decoding strategies.

In conclusion, this analysis offers insights into the challenges and potential options for enhancing LLMs’ structured output era capabilities. By introducing the StructuredRAG benchmark and evaluating two main LLMs, the examine highlights the significance of immediate optimization and the necessity for additional developments on this space. The outcomes reveal that whereas present LLMs can obtain excessive success charges in sure duties, there may be nonetheless appreciable room for enchancment, notably in producing extra advanced structured outputs.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.