{kind=link}

Hey there, everybody, and welcome to the most recent installment of “Hank shares his AI journey.” 🙂 Synthetic Intelligence (AI) continues to be all the fashion, and getting back from Cisco Reside in San Diego, I used to be excited to dive into the world of agentic AI.
With bulletins like Cisco’s personal agentic AI resolution, AI Canvas, in addition to discussions with companions and different engineers about this subsequent section of AI potentialities, my curiosity was piqued: What does this all imply for us community engineers? Furthermore, how can we begin to experiment and find out about agentic AI?
I started my exploration of the subject of agentic AI, studying and watching a variety of content material to achieve a deeper understanding of the topic. I gained’t delve into an in depth definition on this weblog, however listed here are the fundamentals of how I give it some thought:
Agentic AI is a imaginative and prescient for a world the place AI doesn’t simply reply questions we ask, however it begins to work extra independently. Pushed by the objectives we set, and using entry to instruments and methods we offer, an agentic AI resolution can monitor the present state of the community and take actions to make sure our community operates precisely as meant.
Sounds fairly darn futuristic, proper? Let’s dive into the technical points of the way it works—roll up your sleeves, get into the lab, and let’s be taught some new issues.
What are AI “instruments?”
The very first thing I needed to discover and higher perceive was the idea of “instruments” inside this agentic framework. As it’s possible you’ll recall, the LLM (massive language mannequin) that powers AI methods is basically an algorithm educated on huge quantities of knowledge. An LLM can “perceive” your questions and directions. On its personal, nonetheless, the LLM is restricted to the information it was educated on. It could actually’t even search the online for present film showtimes with out some “device” permitting it to carry out an online search.
From the very early days of the GenAI buzz, builders have been constructing and including “instruments” into AI purposes. Initially, the creation of those instruments was advert hoc and different relying on the developer, LLM, programming language, and the device’s objective. However lately, a brand new framework for constructing AI instruments has gotten a whole lot of pleasure and is beginning to develop into a brand new “customary” for device improvement.
This framework is called the Mannequin Context Protocol (MCP). Initially developed by Anthropic, the corporate behind Claude, any developer to make use of MCP to construct instruments, referred to as “MCP Servers,” and any AI platform can act as an “MCP Shopper” to make use of these instruments. It’s important to do not forget that we’re nonetheless within the very early days of AI and AgenticAI; nonetheless, presently, MCP seems to be the strategy for device constructing. So I figured I’d dig in and determine how MCP works by constructing my very own very primary NetAI Agent.
I’m removed from the primary networking engineer to need to dive into this area, so I began by studying a few very useful weblog posts by my buddy Kareem Iskander, Head of Technical Advocacy in Study with Cisco.
These gave me a jumpstart on the important thing matters, and Kareem was useful sufficient to offer some instance code for creating an MCP server. I used to be able to discover extra alone.
Creating an area NetAI playground lab
There isn’t a scarcity of AI instruments and platforms at this time. There’s ChatGPT, Claude, Mistral, Gemini, and so many extra. Certainly, I make the most of lots of them recurrently for varied AI duties. Nonetheless, for experimenting with agentic AI and AI instruments, I needed one thing that was 100% native and didn’t depend on a cloud-connected service.
A main purpose for this want was that I needed to make sure all of my AI interactions remained fully on my laptop and inside my community. I knew I’d be experimenting in a wholly new space of improvement. I used to be additionally going to ship information about “my community” to the LLM for processing. And whereas I’ll be utilizing non-production lab methods for all of the testing, I nonetheless didn’t like the concept of leveraging cloud-based AI methods. I’d really feel freer to be taught and make errors if I knew the chance was low. Sure, low… Nothing is totally risk-free.
Fortunately, this wasn’t the primary time I thought-about native LLM work, and I had a few potential choices able to go. The primary is Ollama, a robust open-source engine for working LLMs domestically, or no less than by yourself server. The second is LMStudio, and whereas not itself open supply, it has an open supply basis, and it’s free to make use of for each private and “at work” experimentation with AI fashions. After I learn a current weblog by LMStudio about MCP help now being included, I made a decision to provide it a attempt for my experimentation.

LMStudio is a shopper for working LLMs, however it isn’t an LLM itself. It gives entry to a lot of LLMs obtainable for obtain and working. With so many LLM choices obtainable, it may be overwhelming once you get began. The important thing issues for this weblog submit and demonstration are that you simply want a mannequin that has been educated for “device use.” Not all fashions are. And moreover, not all “tool-using” fashions truly work with instruments. For this demonstration, I’m utilizing the google/gemma-2-9b mannequin. It’s an “open mannequin” constructed utilizing the identical analysis and tooling behind Gemini.
The following factor I wanted for my experimentation was an preliminary thought for a device to construct. After some thought, I made a decision a superb “hiya world” for my new NetAI challenge can be a method for AI to ship and course of “present instructions” from a community system. I selected pyATS to be my NetDevOps library of alternative for this challenge. Along with being a library that I’m very conversant in, it has the advantage of computerized output processing into JSON via the library of parsers included in pyATS. I may additionally, inside simply a few minutes, generate a primary Python operate to ship a present command to a community system and return the output as a place to begin.
Right here’s that code:
def send_show_command(
command: str,
device_name: str,
username: str,
password: str,
ip_address: str,
ssh_port: int = 22,
network_os: Non-compulsory[str] = "ios",
) -> Non-compulsory[Dict[str, Any]]:
# Construction a dictionary for the system configuration that may be loaded by PyATS
device_dict = {
"units": {
device_name: {
"os": network_os,
"credentials": {
"default": {"username": username, "password": password}
},
"connections": {
"ssh": {"protocol": "ssh", "ip": ip_address, "port": ssh_port}
},
}
}
}
testbed = load(device_dict)
system = testbed.units[device_name]
system.join()
output = system.parse(command)
system.disconnect()
return output
Between Kareem’s weblog posts and the getting-started information for FastMCP 2.0, I realized it was frighteningly simple to transform my operate into an MCP Server/Instrument. I simply wanted so as to add 5 traces of code.
from fastmcp import FastMCP
mcp = FastMCP("NetAI Hey World")
@mcp.device()
def send_show_command()
.
.
if __name__ == "__main__":
mcp.run()
Effectively.. it was ALMOST that simple. I did should make a number of changes to the above fundamentals to get it to run efficiently. You possibly can see the full working copy of the code in my newly created NetAI-Studying challenge on GitHub.
As for these few changes, the adjustments I made had been:
- A pleasant, detailed docstring for the operate behind the device. MCP purchasers use the small print from the docstring to know how and why to make use of the device.
- After some experimentation, I opted to make use of “http” transport for the MCP server quite than the default and extra frequent “STDIO.” The explanation I went this fashion was to arrange for the subsequent section of my experimentation, when my pyATS MCP server would seemingly run throughout the community lab surroundings itself, quite than on my laptop computer. STDIO requires the MCP Shopper and Server to run on the identical host system.
So I fired up the MCP Server, hoping that there wouldn’t be any errors. (Okay, to be trustworthy, it took a few iterations in improvement to get it working with out errors… however I’m doing this weblog submit “cooking present model,” the place the boring work alongside the best way is hidden. 😉
python netai-mcp-hello-world.py ╭─ FastMCP 2.0 ──────────────────────────────────────────────────────────────╮ │ │ │ _ __ ___ ______ __ __ _____________ ____ ____ │ │ _ __ ___ / ____/___ ______/ /_/ |/ / ____/ __ |___ / __ │ │ _ __ ___ / /_ / __ `/ ___/ __/ /|_/ / / / /_/ / ___/ / / / / / │ │ _ __ ___ / __/ / /_/ (__ ) /_/ / / / /___/ ____/ / __/_/ /_/ / │ │ _ __ ___ /_/ __,_/____/__/_/ /_/____/_/ /_____(_)____/ │ │ │ │ │ │ │ │ 🖥️ Server title: FastMCP │ │ 📦 Transport: Streamable-HTTP │ │ 🔗 Server URL: http://127.0.0.1:8002/mcp/ │ │ │ │ 📚 Docs: https://gofastmcp.com │ │ 🚀 Deploy: https://fastmcp.cloud │ │ │ │ 🏎️ FastMCP model: 2.10.5 │ │ 🤝 MCP model: 1.11.0 │ │ │ ╰────────────────────────────────────────────────────────────────────────────╯ [07/18/25 14:03:53] INFO Beginning MCP server 'FastMCP' with transport 'http' on http://127.0.0.1:8002/mcp/server.py:1448 INFO: Began server course of [63417] INFO: Ready for utility startup. INFO: Utility startup full. INFO: Uvicorn working on http://127.0.0.1:8002 (Press CTRL+C to give up)
The following step was to configure LMStudio to behave because the MCP Shopper and connect with the server to have entry to the brand new “send_show_command” device. Whereas not “standardized, “most MCP Purchasers use a really frequent JSON configuration to outline the servers. LMStudio is certainly one of these purchasers.

Wait… if you happen to’re questioning, ‘Wright here’s the community, Hank? What system are you sending the ‘present instructions’ to?’ No worries, my inquisitive good friend: I created a quite simple Cisco Modeling Labs (CML) topology with a few IOL units configured for direct SSH entry utilizing the PATty function.

Let’s see it in motion!
Okay, I’m certain you’re able to see it in motion. I do know I certain was as I used to be constructing it. So let’s do it!
To begin, I instructed the LLM on how to hook up with my community units within the preliminary message.

I did this as a result of the pyATS device wants the deal with and credential data for the units. Sooner or later I’d like to take a look at the MCP servers for various supply of reality choices like NetBox and Vault so it could “look them up” as wanted. However for now, we’ll begin easy.
First query: Let’s ask about software program model information.
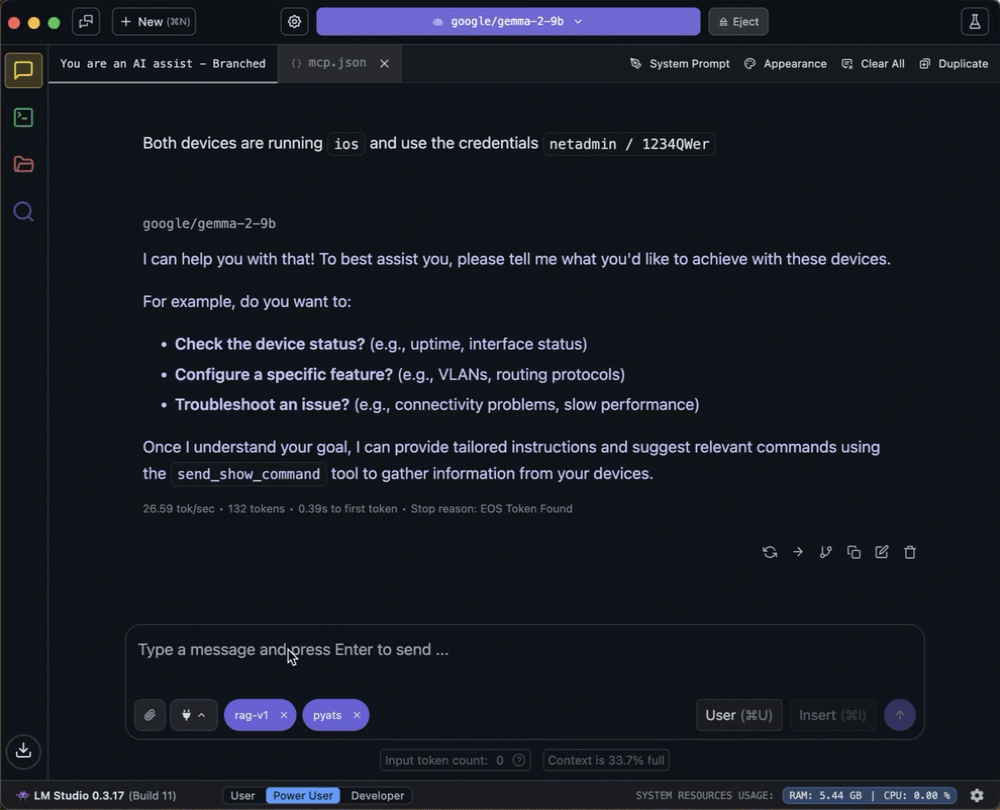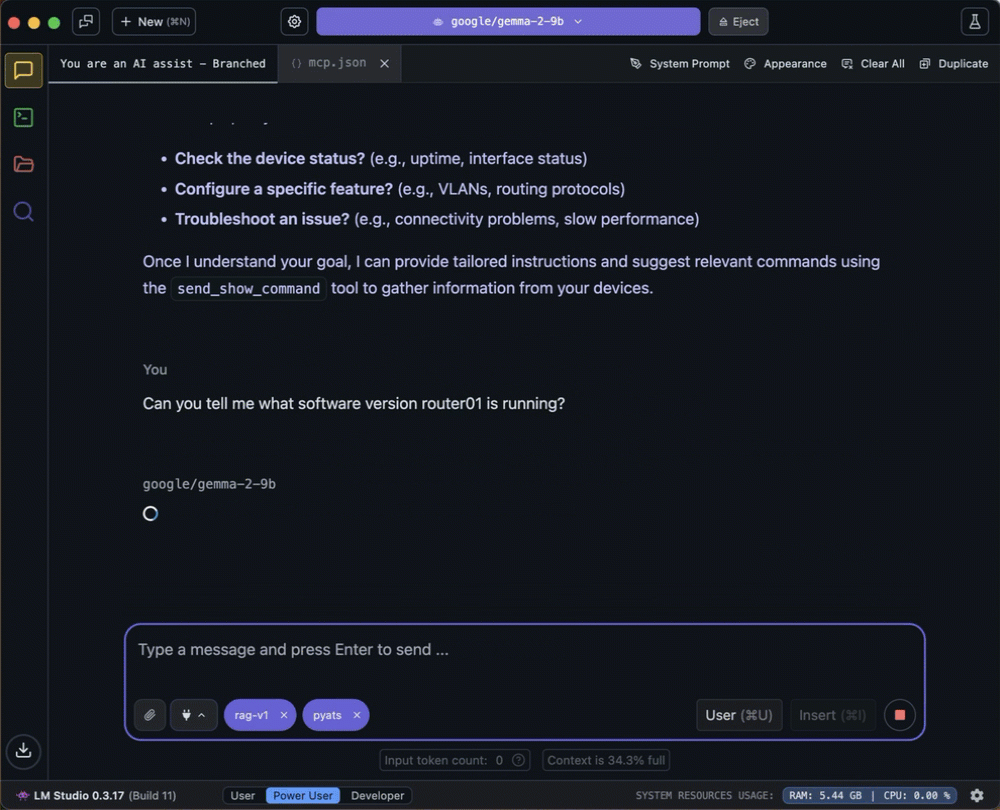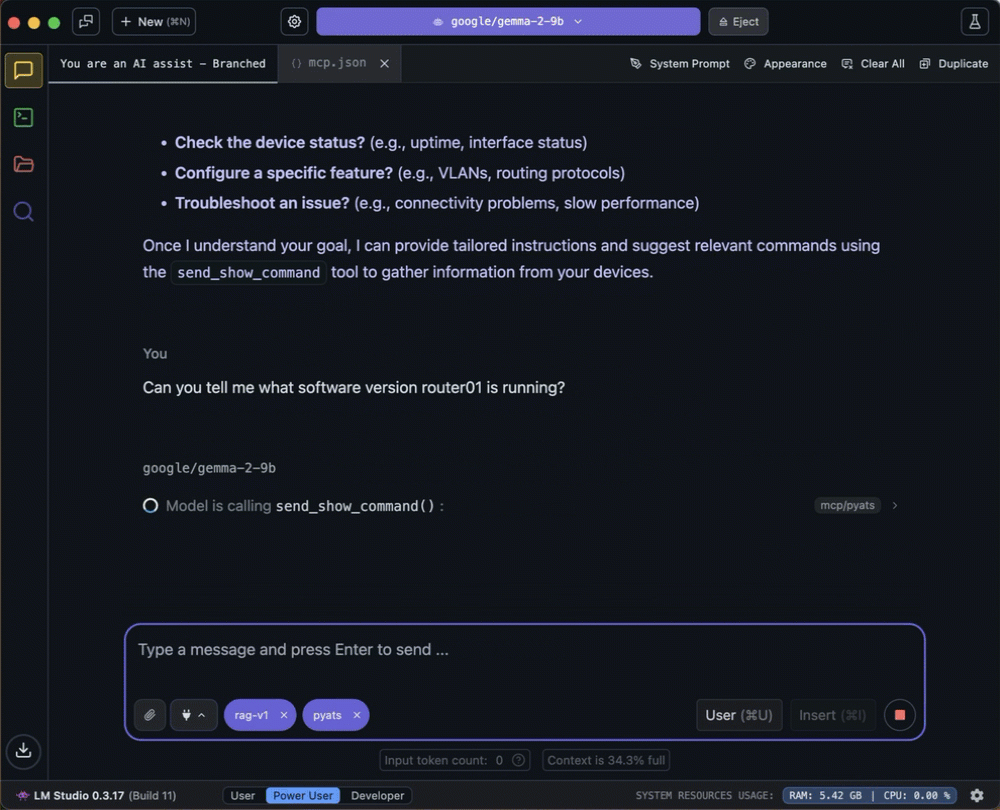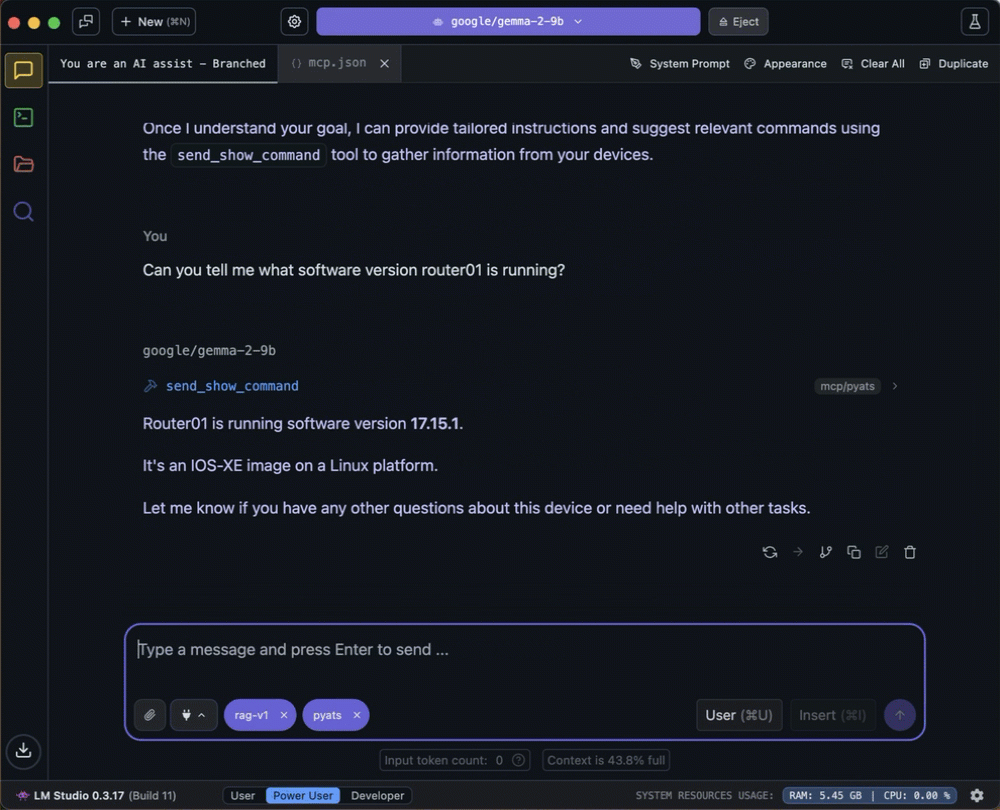
You possibly can see the small print of the device name by diving into the enter/output display.

That is fairly cool, however what precisely is going on right here? Let’s stroll via the steps concerned.
- The LLM shopper begins and queries the configured MCP servers to find the instruments obtainable.
- I ship a “immediate” to the LLM to contemplate.
- The LLM processes my prompts. It “considers” the completely different instruments obtainable and in the event that they is perhaps related as a part of constructing a response to the immediate.
- The LLM determines that the “send_show_command” device is related to the immediate and builds a correct payload to name the device.
- The LLM invokes the device with the correct arguments from the immediate.
- The MCP server processes the referred to as request from the LLM and returns the consequence.
- The LLM takes the returned outcomes, together with the unique immediate/query as the brand new enter to make use of to generate the response.
- The LLM generates and returns a response to the question.
This isn’t all that completely different from what you may do if you happen to had been requested the identical query.
- You’d take into account the query, “What software program model is router01 working?”
- You’d take into consideration the other ways you might get the knowledge wanted to reply the query. Your “instruments,” so to talk.
- You’d determine on a device and use it to collect the knowledge you wanted. Most likely SSH to the router and run “present model.”
- You’d assessment the returned output from the command.
- You’d then reply to whoever requested you the query with the correct reply.
Hopefully, this helps demystify a bit of about how these “AI Brokers” work underneath the hood.
How about yet one more instance? Maybe one thing a bit extra complicated than merely “present model.” Let’s see if the NetAI agent can assist establish which swap port the host is related to by describing the essential course of concerned.
Right here’s the query—sorry, immediate, that I undergo the LLM:

What we should always discover about this immediate is that it’ll require the LLM to ship and course of present instructions from two completely different community units. Identical to with the primary instance, I do NOT inform the LLM which command to run. I solely ask for the knowledge I would like. There isn’t a “device” that is aware of the IOS instructions. That data is a part of the LLM’s coaching information.
Let’s see the way it does with this immediate:

And take a look at that, it was in a position to deal with the multi-step process to reply my query. The LLM even defined what instructions it was going to run, and the way it was going to make use of the output. And if you happen to scroll again as much as the CML community diagram, you’ll see that it accurately identifies interface Ethernet0/2 because the swap port to which the host was related.
So what’s subsequent, Hank?
Hopefully, you discovered this exploration of agentic AI device creation and experimentation as attention-grabbing as I’ve. And possibly you’re beginning to see the chances to your personal day by day use. In case you’d prefer to attempt a few of this out by yourself, you could find every little thing you want on my netai-learning GitHub challenge.
- The mcp-pyats code for the MCP Server. You’ll discover each the straightforward “hiya world” instance and a extra developed work-in-progress device that I’m including further options to. Be at liberty to make use of both.
- The CML topology I used for this weblog submit. Although any community that’s SSH reachable will work.
- The mcp-server-config.json file that you would be able to reference for configuring LMStudio
- A “System Immediate Library” the place I’ve included the System Prompts for each a primary “Mr. Packets” community assistant and the agentic AI device. These aren’t required for experimenting with NetAI use instances, however System Prompts will be helpful to make sure the outcomes you’re after with LLM.
A few “gotchas” I needed to share that I encountered throughout this studying course of, which I hope may prevent a while:
First, not all LLMs that declare to be “educated for device use” will work with MCP servers and instruments. Or no less than those I’ve been constructing and testing. Particularly, I struggled with Llama 3.1 and Phi 4. Each appeared to point they had been “device customers,” however they did not name my instruments. At first, I believed this was because of my code, however as soon as I switched to Gemma 2, they labored instantly. (I additionally examined with Qwen3 and had good outcomes.)
Second, when you add the MCP Server to LMStudio’s “mcp.json” configuration file, LMStudio initiates a connection and maintains an energetic session. Which means if you happen to cease and restart the MCP server code, the session is damaged, providing you with an error in LMStudio in your subsequent immediate submission. To repair this problem, you’ll must both shut and restart LMStudio or edit the “mcp.json” file to delete the server, reserve it, after which re-add it. (There’s a bug filed with LMStudio on this downside. Hopefully, they’ll repair it in an upcoming launch, however for now, it does make improvement a bit annoying.)
As for me, I’ll proceed exploring the idea of NetAI and the way AI brokers and instruments could make our lives as community engineers extra productive. I’ll be again right here with my subsequent weblog as soon as I’ve one thing new and attention-grabbing to share.
Within the meantime, how are you experimenting with agentic AI? Are you excited concerning the potential? Any options for an LLM that works nicely with community engineering data? Let me know within the feedback under. Speak to you all quickly!
Join Cisco U. | Be part of the Cisco Studying Community at this time without spending a dime.
Study with Cisco
X | Threads | Fb | LinkedIn | Instagram | YouTube
Use #CiscoU and #CiscoCert to affix the dialog.
Share: