
Giant Language Fashions (LLMs) have demonstrated exceptional capabilities in complicated reasoning duties, significantly in mathematical problem-solving and coding purposes. Analysis has proven a powerful correlation between the size of reasoning chains and improved accuracy in problem-solving outcomes. Nonetheless, they face vital challenges: whereas prolonged reasoning processes improve problem-solving capabilities, they typically result in inefficient options. Fashions are likely to generate unnecessarily prolonged reasoning chains even for easy questions that could possibly be solved extra immediately. This one-size-fits-all method to reasoning size creates computational inefficiency and reduces the sensible utility of those methods in real-world purposes.
Varied methodologies have emerged to reinforce LLMs’ reasoning capabilities, with Chain-of-Thought (CoT) being a foundational method that improves problem-solving by breaking down reasoning into discrete steps. Constructing upon CoT, researchers have developed extra complicated strategies comparable to prolonged CoT with extra steps, self-reflection mechanisms, multi-turn reasoning, and multi-agent debate methods. Latest developments have targeted on scaling up reasoning size, as demonstrated by fashions like OpenAI-o1 and DeepSeek-R1. Nonetheless, they generate intensive reasoning chains whatever the drawback’s complexity. This inefficient method will increase computational prices and bigger carbon footprints.
Researchers from Meta AI and The College of Illinois Chicago have proposed an modern method to handle the inefficiencies in LLM reasoning by growing a system that robotically adjusts reasoning hint lengths based mostly on question complexity. Whereas earlier heuristic strategies have tried to enhance token effectivity for higher accuracy with diminished overhead, this new analysis takes a reinforcement studying (RL) perspective. As a substitute of explicitly modeling response lengths or balancing intrinsic and extrinsic rewards, the researchers have developed a grouping methodology, that entails categorizing responses into distinct teams based mostly on their traits, making a complete framework to cowl your complete response area whereas sustaining effectivity.
The proposed methodology employs a sequence-level notation system that simplifies the complicated transition chances and intermediate rewards by treating every response as an entire unit. The structure divides responses into two major teams, one for regular-length Chain-of-Thought responses and the opposite for prolonged responses, every with distinct inference prices. The system operates by means of a bi-level optimization framework, the place useful resource allocation constraints are outlined inside a convex polytope that limits the density mass of every group. Furthermore, the algorithm makes use of an iterative method, fixing the upper-level drawback by means of gradient updates whereas immediately addressing the lower-level optimization at every iteration.
The experimental outcomes exhibit vital efficiency enhancements throughout totally different implementations of the proposed methodology. The supervised fine-tuning (SFT) constructions, SVSFT and ASV-SFT-1, obtain enhanced move@1 metrics, although at the price of elevated inference necessities. Extra notably, the ASV-IuB-q+ formulation with parameters set at 50% and 75% present exceptional effectivity enhancements, decreasing prices by 4.14% at 2.16 instances and 5.74% at 4.32 instances respectively, matching the efficiency of SCoRe, a number one RL-based self-correction technique. The findings additionally reveal a noteworthy limitation of prompting-based and SFT-based strategies in each absolute enchancment and effectivity metrics, suggesting that self-correction capabilities emerge extra successfully by means of RL.
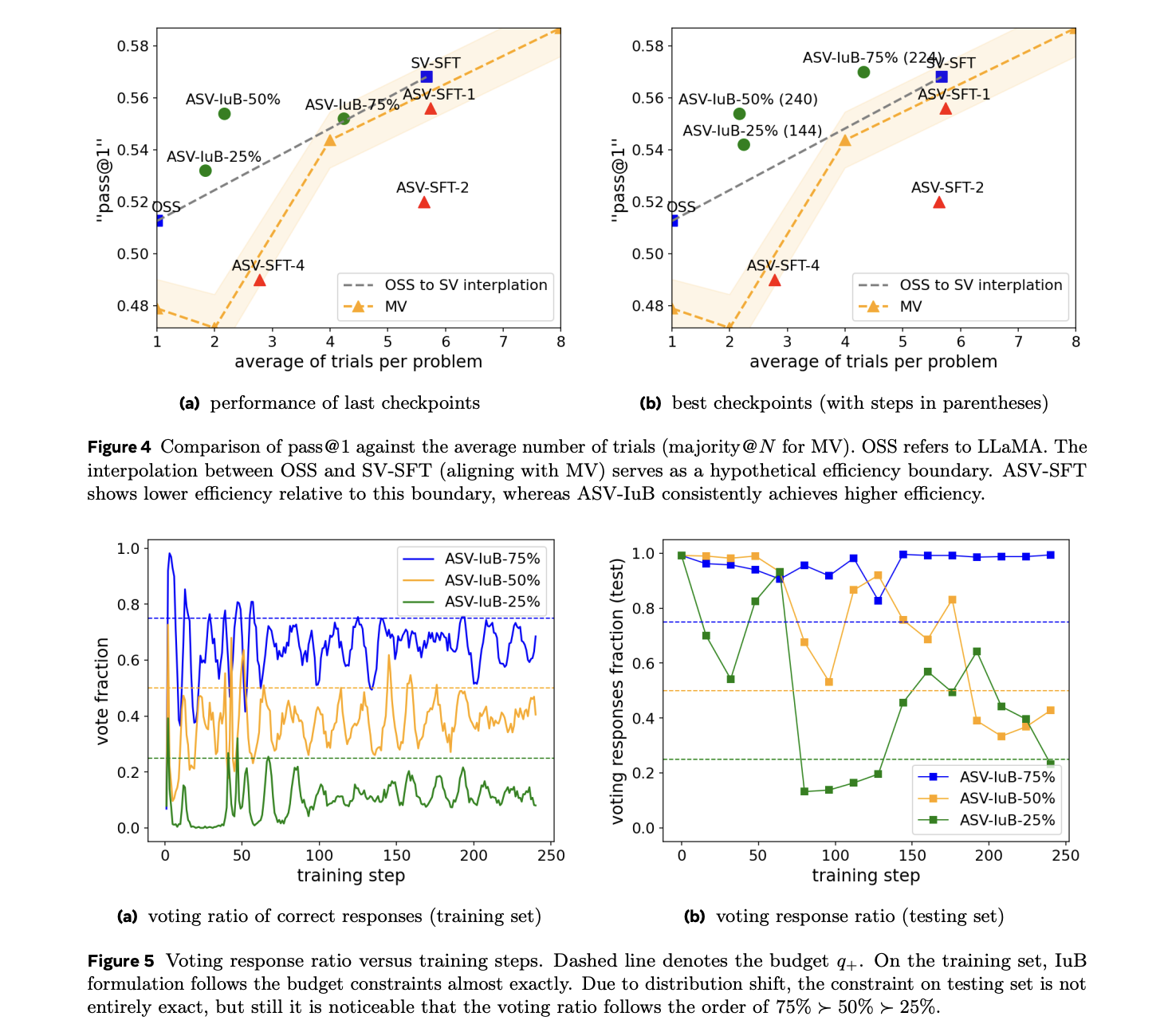
In conclusion, researchers launched a technique to beat the inefficiencies in LLM reasoning. Furthermore, they launched IBPO, a constrained coverage optimization framework that implements a weighted Supervised Effective-Tuning replace mechanism. This method determines optimum weights by means of an integer linear programming resolution, in every iteration, constructed upon the CGPO framework. Whereas the system reveals efficient constraint adherence and dynamic inference finances allocation in mathematical reasoning duties, computational useful resource limitations may be addressed by means of pattern accumulation throughout a number of steps. Future analysis instructions embrace increasing the framework’s applicability throughout totally different LLM purposes and scaling up experimental implementations to check its full potential in numerous contexts.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.