{kind=link}

Giant Language Fashions (LLMs) have grow to be more and more reliant on Reinforcement Studying from Human Suggestions (RLHF) for fine-tuning throughout varied functions, together with code era, mathematical reasoning, and dialogue help. Nevertheless, a major problem has emerged within the type of diminished output range when utilizing RLHF. Analysis has recognized a important trade-off between alignment high quality and output range in RLHF-trained fashions. When these fashions align extremely with desired aims, they present restricted output variability. This limitation poses considerations for artistic open-ended duties equivalent to story era, information synthesis, and red-teaming, the place numerous outputs are important for efficient efficiency.
Present approaches to LLM alignment have targeted on enhancing instruction following, security, and reliability via RLHF, however these enhancements usually come at the price of output range. Numerous strategies have been developed to deal with this problem, together with using f-divergence with DPO/PPO algorithms, which try to steadiness range and alignment. Different approaches combine analysis metrics like SelfBLEU and Sentence-BERT into RL fine-tuning to spice up range, notably for red-teaming duties. Furthermore, some researchers have explored curiosity-driven reinforcement studying strategies, starting from count-based approaches to prediction error-based methods. Regardless of these efforts, the elemental trade-off between alignment high quality and output range stays a major problem.
Researchers from Baidu have proposed a novel framework known as Curiosity-driven Reinforcement Studying from Human Suggestions (CD-RLHF) to deal with the diversity-alignment trade-off in language fashions. This method incorporates curiosity as an intrinsic reward mechanism in the course of the RLHF coaching stage, working alongside conventional extrinsic rewards from the reward mannequin. CD-RLHF makes use of ahead dynamics to compute prediction errors of state representations, which helps estimate curiosity ranges. A key characteristic of this method is that continuously visited states steadily grow to be much less attention-grabbing to the mannequin. This twin reward system goals to keep up excessive alignment high quality whereas selling numerous outputs via diverse token decisions at every resolution level.
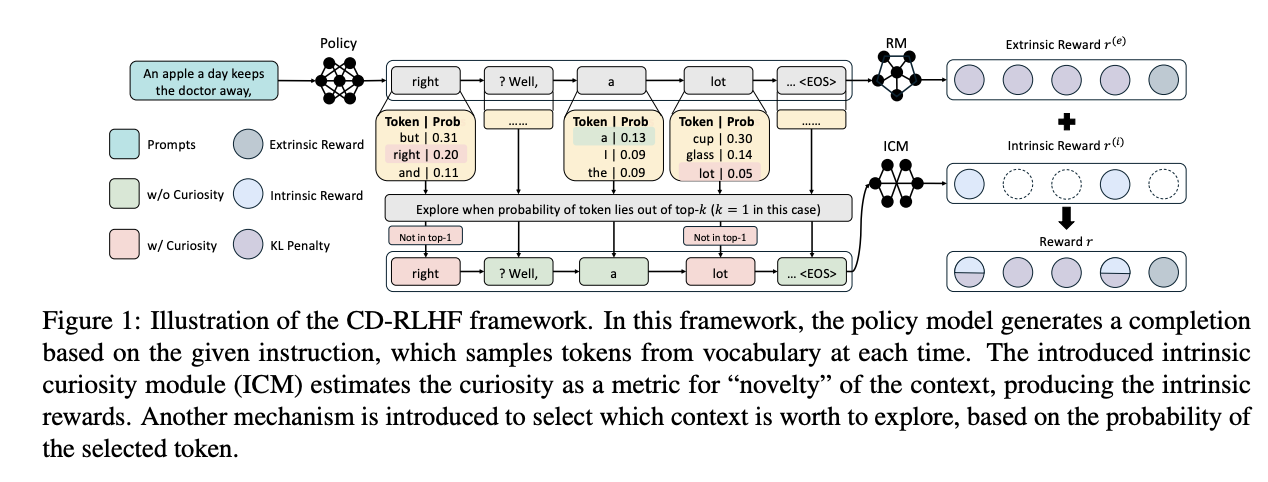
The implementation and analysis of CD-RLHF encompasses a number of elements and datasets. The structure was examined on two main datasets: TL;DR for textual content summarization, containing 93k human-annotated desire pairs, and UltraFeedback for instruction following, with 61.1k coaching pairs. The framework was carried out utilizing varied base fashions together with Gemma-2B, Gemma-7B, Llama-3.2-1B, and Llama-3.2-3B, all educated inside the DeepSpeed-Chat framework. The coaching information was distributed throughout SFT, RM, and PPO phases in a 20/40/40 ratio. For comparability, baseline strategies together with vanilla RLHF and Despatched-Rewards are carried out, which use SelfBLEU and Sentence-BERT scores as extra rewards throughout coaching.
The experimental outcomes show CD-RLHF’s superior efficiency throughout a number of analysis metrics and fashions. Within the TL;DR summarization job, CD-RLHF achieves important enhancements in output range displaying positive factors of 16.66% and 6.22% on Gemma-2B and Gemma-7B respectively in comparison with the RLHF baseline. For the UltraFeedback instruction-following job, the tactic exhibits much more spectacular outcomes, with range enhancements starting from 7.35% to 14.29% throughout totally different fashions whereas sustaining sturdy alignment high quality. Exterior validation via GPT-4 analysis confirmed CD-RLHF reaching win charges of as much as 58% in opposition to the PPO baseline on TL;DR and a median of 62% on UltraFeedback.
In conclusion, researchers launched CD-RLHF which represents a major development in addressing the diversity-alignment trade-off in language mannequin coaching. The framework combines curiosity-driven exploration with conventional extrinsic rewards to reinforce output range whereas sustaining alignment high quality, as proven via in depth testing on TL;DR summarization and UltraFeedback instruction-following duties. Regardless of these achievements, a number of challenges stay, together with the necessity to steadiness totally different reward scales and the persistent hole between the output range of SFT, and RLHF-trained fashions. Whereas CD-RLHF mitigates the trade-off between range and alignment, additional analysis is required to totally bridge this hole and obtain optimum efficiency throughout each metrics.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 70k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Supply Multi-Agent Framework to Consider Advanced Conversational AI System (Promoted)

Sajjad Ansari is a last yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.