{kind=link}

Tokenization performs a elementary position within the efficiency and scalability of Giant Language Fashions (LLMs). Regardless of being a vital element, its affect on mannequin coaching and effectivity stays underexplored. Whereas bigger vocabularies can compress sequences and scale back computational prices, current approaches tie enter and output vocabularies collectively, creating trade-offs the place scaling advantages bigger fashions however harms smaller ones. This paper introduces a framework referred to as Over-Tokenized Transformers that reimagines vocabulary design by decoupling enter and output tokenization, unlocking new pathways for mannequin effectivity and efficiency.
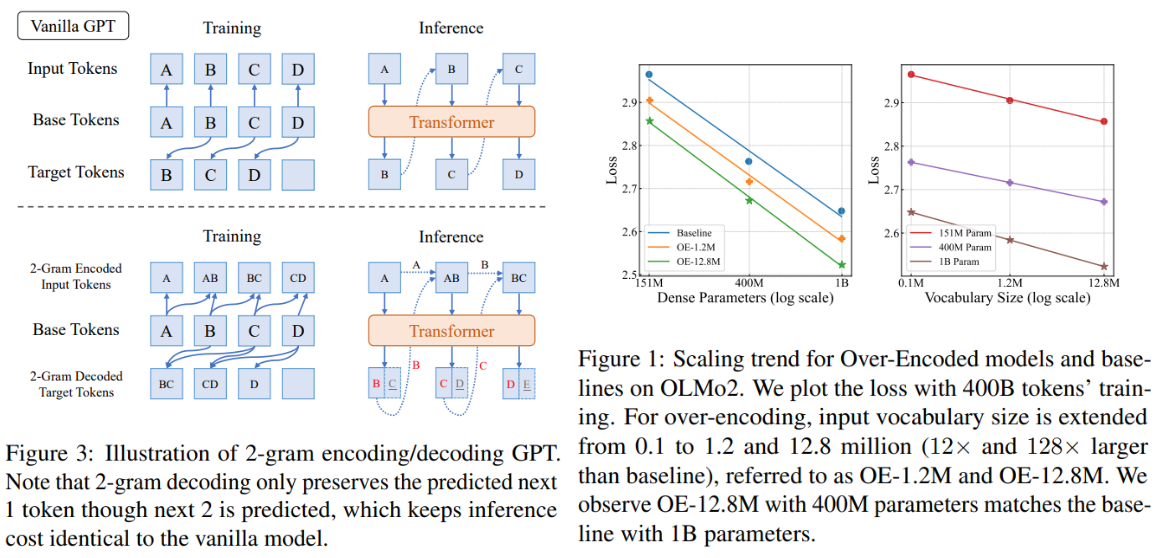
Conventional tokenization strategies use equivalent vocabularies for enter processing and output prediction. Whereas bigger vocabularies permit fashions to course of longer n-gram tokens (e.g., multi-character sequences), they drive smaller fashions to deal with overly granular output predictions, growing underfitting dangers. For example, a 3-gram tokenizer reduces sequence size by 66% however requires predicting three characters collectively—a activity manageable for giant fashions however overwhelming for smaller ones. Earlier work like multi-token prediction (MTP) tried to handle this by predicting future tokens in parallel, however these strategies nonetheless entangled enter/output granularity and struggled with smaller architectures.
The analysis crew recognized a vital perception by means of artificial experiments with context-free grammars: enter and output vocabularies affect fashions in a different way. Bigger enter vocabularies persistently improved all mannequin sizes by enriching context representations by means of multi-gram embeddings. Conversely, bigger output vocabularies launched fine-grained prediction duties that solely benefited sufficiently massive fashions. This dichotomy motivated their Over-Tokenized framework, which separates enter encoding (Over-Encoding) and output decoding (Over-Decoding) vocabularies.
Over-Encoding (OE) scales enter vocabularies exponentially utilizing hierarchical n-gram embeddings. As an alternative of a single token ID, every enter token is represented because the sum of 1-, 2-, and 3-gram embeddings. For instance, the phrase “cat” would possibly decompose into embeddings for “c,” “ca,” and “cat,” permitting the mannequin to seize multi-scale contextual cues. To keep away from impractical reminiscence prices from massive n-gram tables (e.g., 100k³ entries), the crew used parameter-efficient strategies:
- Modulo-based token hashing: Maps n-gram tokens to a fixed-size embedding desk utilizing modular arithmetic, enabling dynamic vocabulary enlargement with out storing all potential mixtures.
- Embedding decomposition: Splits high-dimensional embeddings into smaller, stacked matrices, lowering reminiscence entry prices whereas preserving representational capability.
Over-Decoding (OD) approximates bigger output vocabularies by predicting a number of future tokens sequentially, a refinement of earlier MTP strategies. For example, as a substitute of predicting one token at a time, OD trains the mannequin to foretell the following two tokens conditioned on the primary prediction. Crucially, OD is selectively utilized—solely bigger fashions profit from this granular supervision, whereas smaller ones retain single-token decoding to keep away from underfitting.
The researchers carried out experiments on OLMo and OLMoE architectures and demonstrated three key findings:
- Log-Linear Scaling: Coaching loss decreased linearly as enter vocabulary measurement grew exponentially (Determine 1). A 400M parameter mannequin with a 12.8M-entry enter vocabulary matched the efficiency of a 1B-parameter baseline, reaching 2.5× efficient scaling at equal computational value.
- Convergence Acceleration: Over-Encoding decreased coaching steps wanted for convergence by 3–5× throughout duties like MMLU and PIQA, suggesting richer enter representations speed up studying.
- Sparse Parameter Effectivity: Regardless of utilizing 128× bigger enter vocabularies, reminiscence and computation overheads elevated by <5% on account of sparse embedding entry and optimized sharding methods.
On evaluations, the framework demonstrated constant efficiency enhancements throughout numerous mannequin varieties. For dense fashions, a 151M Over-Encoded (OE) mannequin achieved a 14% discount in perplexity in comparison with its baseline. Equally, in sparse Combination-of-Consultants (MoE) fashions, the OLMoE-1.3B with OE decreased validation loss by 0.12 factors, though the beneficial properties had been much less pronounced as the advantages of sparse consultants diluted the affect of embedding enhancements. Past artificial experiments, real-world evaluations on large-scale datasets additional validated these findings. Over-Encoded fashions persistently improved efficiency throughout a number of benchmarks, together with MMLU-Var, Hellaswag, ARC-Problem, ARC-Simple, and PIQA. Notably, the framework accelerated convergence, reaching a 5.7× speedup in coaching loss discount. Moreover, downstream evaluations confirmed vital acceleration, with OE delivering speedups of three.2× on MMLU-Var, 3.0× on Hellaswag, 2.6× on ARC-Problem, 3.1× on ARC-Simple, and three.9× on PIQA, highlighting its effectivity and effectiveness throughout various duties.
In conclusion, this work redefines tokenization as a scalable dimension in language mannequin design. By decoupling enter and output vocabularies, Over-Tokenized Transformers break conventional trade-offs, enabling smaller fashions to profit from compressed enter sequences with out grappling with overly complicated prediction duties. The log-linear relationship between enter vocabulary measurement and efficiency suggests embedding parameters signify a brand new axis for scaling legal guidelines, complementing current work on mannequin depth and width. Virtually, the framework provides a low-cost improve path for current architectures—integrating Over-Encoding requires minimal code modifications however yields speedy effectivity beneficial properties. Future analysis may discover hybrid tokenization methods or dynamic vocabulary adaptation, additional solidifying tokenization’s position within the subsequent era of environment friendly, high-performing LLMs.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 70k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Supply Multi-Agent Framework to Consider Complicated Conversational AI System (Promoted)
Vineet Kumar is a consulting intern at MarktechPost. He’s presently pursuing his BS from the Indian Institute of Know-how(IIT), Kanpur. He’s a Machine Studying fanatic. He’s captivated with analysis and the newest developments in Deep Studying, Pc Imaginative and prescient, and associated fields.