 Framework Leveraging Video Content material for Enhanced Question Responses")
Video-based applied sciences have develop into important instruments for data retrieval and understanding complicated ideas. Movies mix visible, temporal, and contextual information, offering a multimodal illustration that surpasses static photos and textual content. With the growing reputation of video-sharing platforms and the huge repository of academic and informational movies obtainable on-line, leveraging movies as information sources provides unprecedented alternatives to reply queries that require detailed context, spatial understanding, and course of demonstration.
Retrieval-augmented era programs, which mix retrieval and response era, typically neglect the complete potential of video information. These programs usually depend on textual data or often embody static photos to help question responses. Nonetheless, they fail to seize the richness of movies, which embody visible dynamics and multimodal cues important for complicated duties. Typical strategies both predefine query-relevant movies with out retrieval or convert movies into textual codecs, shedding crucial data like visible context and temporal dynamics. This inadequacy hinders offering exact and informative solutions for real-world, multimodal queries.

Present methodologies have explored textual or image-based retrieval however haven’t absolutely utilized video information. In conventional RAG programs, video content material is represented as subtitles or captions, focusing solely on textual elements or lowered to preselected frames for focused evaluation. Each approaches restrict the multimodal richness of movies. Furthermore, the absence of methods to dynamically retrieve and incorporate query-relevant movies additional restricts the effectiveness of those programs. The dearth of complete video integration leaves an untapped alternative to boost the retrieval-augmented era paradigm.
Analysis groups from OkaiST and DeepAuto.ai proposed a novel framework known as VideoRAG to deal with the challenges related to utilizing video information in retrieval-augmented era programs. VideoRAG dynamically retrieves query-relevant movies from a big corpus and incorporates visible and textual data into the era course of. It leverages the capabilities of superior Massive Video Language Fashions (LVLMs) for seamless integration of multimodal information. The method represents a major enchancment over earlier strategies by making certain the retrieved movies are contextually aligned with consumer queries and sustaining the temporal richness of the video content material.
The proposed methodology entails two predominant phases: retrieval and era. It then identifies movies by their comparable visible and textual elements regarding the question throughout retrieval. VideoRAG applies automated speech recognition to generate the auxiliary textual information for a video that’s not obtainable with subtitles. This stage ensures that the response era from all movies will get significant contributions from every video. The related retrieved movies are additional fed into the era module of the framework, the place multimodal information like frames, subtitles, and question textual content are built-in. These inputs are processed holistically in LVLMs, enabling them to provide lengthy, wealthy, correct, and contextually apt responses. The main target of VideoRAG on visual-textual factor combos makes it potential to symbolize intricacies in complicated processes and interactions that can’t be described utilizing static modalities.
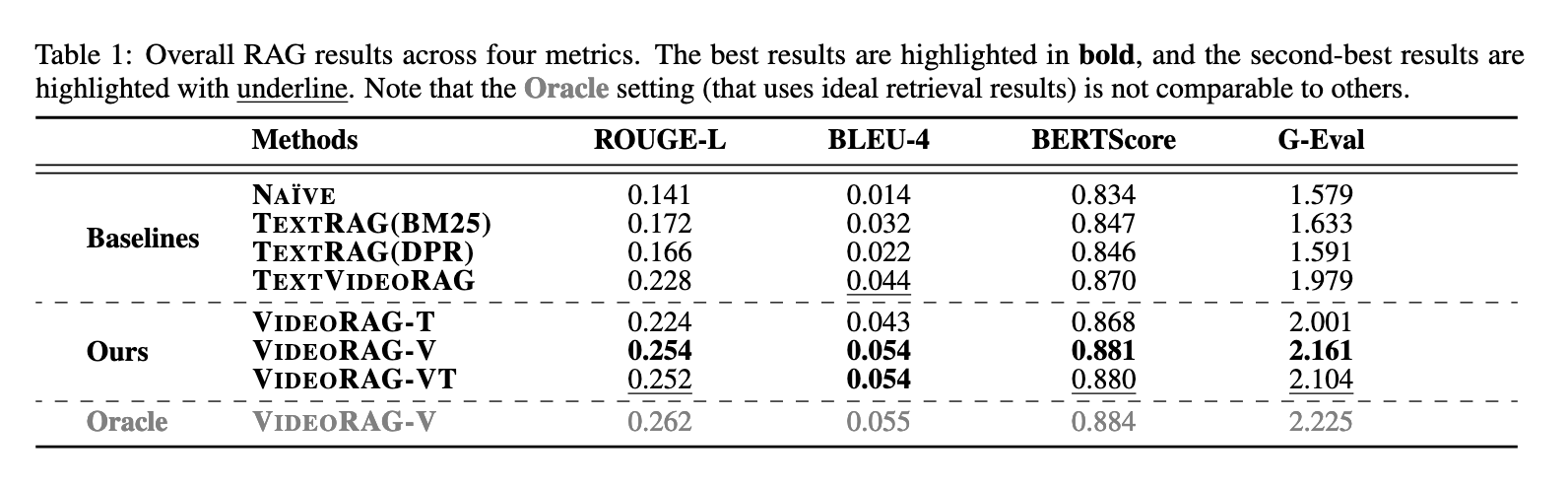
VideoRAG was extensively experimented with on datasets like WikiHowQA and HowTo100M. These datasets embody a broad spectrum of queries and video content material. Particularly, the method revealed a greater response high quality, based on varied metrics, like ROUGE-L, BLEU-4, and BERTScore. So, relating to the VideoRAG technique, the rating was 0.254 based on ROUGE-L, whereas for text-based strategies, RAG reported 0.228 as the utmost rating. It’s additionally demonstrated the identical with the BLEU-4, the n-gram overlap: for VideoRAG; that is 0.054; for the text-based one, it was solely 0.044. The framework variant, which used each video frames and transcripts, additional improved efficiency, attaining a BERTScore of 0.881, in comparison with 0.870 for the baseline strategies. These outcomes spotlight the significance of multimodal integration in bettering response accuracy and underscore the transformative potential of VideoRAG.

The authors confirmed that VideoRAG’s means to mix visible and textual components dynamically results in extra contextually wealthy and exact responses. In comparison with conventional RAG programs that rely solely on textual or static picture information, VideoRAG excels in situations requiring detailed spatial and temporal understanding. Together with auxiliary textual content era for movies with out subtitles additional ensures constant efficiency throughout various datasets. By enabling retrieval and era based mostly on a video corpus, the framework addresses the constraints of present strategies and units a benchmark for future multimodal retrieval-augmented programs.
In a nutshell, VideoRAG represents an enormous step ahead in retrieval-augmented era programs as a result of it leverages video content material to boost response high quality. This mannequin combines state-of-the-art retrieval methods with the ability of LVLMs to ship context-rich, correct solutions. Methodologically, it efficiently addresses the deficiencies of the present programs, thereby offering a strong framework for incorporating video information into information era pipelines. With its superior efficiency over varied metrics and datasets, VideoRAG establishes itself as a novel method for together with movies in retrieval-augmented era programs.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 65k+ ML SubReddit.
🚨 Beneficial Open-Supply AI Platform: ‘Parlant is a framework that transforms how AI brokers make choices in customer-facing situations.’ (Promoted)
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.