
Growing Graphical Person Interface (GUI) Brokers faces two key challenges that hinder their effectiveness. First, present brokers lack sturdy reasoning capabilities, relying totally on single-step operations and failing to include reflective studying mechanisms. This often results in errors being repeated within the execution of complicated, multi-step duties. Most present methods rely very a lot on textual annotations representing GUI knowledge, corresponding to accessibility timber. These result in two forms of penalties: info loss and computational inefficiency; however additionally they trigger inconsistencies amongst platforms and scale back their flexibility in precise deployment eventualities.
The fashionable strategies for GUI automation are multimodal massive language fashions used along with imaginative and prescient encoders for understanding and interplay with GUI settings. Efforts corresponding to ILuvUI, CogAgent, and Ferret-UI-anyres have superior the sphere by enhancing GUI understanding, using high-resolution imaginative and prescient encoders, and using resolution-agnostic strategies. Nonetheless, these strategies exhibit notable drawbacks, together with excessive computational prices, restricted reliance on visible knowledge over textual representations, and insufficient reasoning capabilities. The methodological constraints impose appreciable constraints on their skill to carry out real-time duties and the complexity of executing complicated sequences. This severely restricts their skill to dynamically adapt and proper errors throughout operational processes due to the dearth of a sturdy mechanism for hierarchical and reflective reasoning.
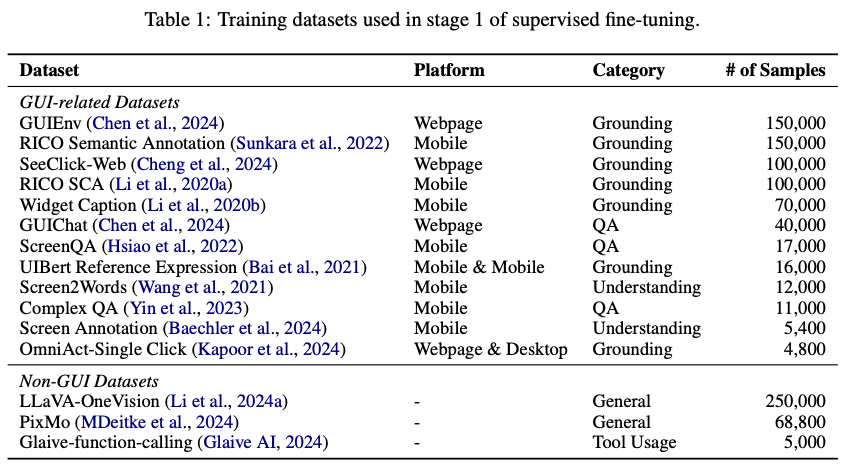
Researchers from Zhejiang College, Dalian College of Expertise, Reallm Labs, ByteDance Inc., and The Hong Kong Polytechnic College introduce InfiGUIAgent, a novel multimodal graphical consumer interface agent that addresses these limitations. The methodology is constructed upon the delicate inherent reasoning capabilities via a dual-phase supervised fine-tuning framework to have the ability to adapt and be efficient. The coaching within the first section focuses on creating the bottom capabilities by utilizing various datasets that may enhance understanding of graphical consumer interfaces, grounding, and process adaptability. The datasets used, corresponding to Screen2Words, GUIEnv, and RICO SCA, cowl duties corresponding to semantic interpretation, consumer interplay modeling, and question-answering-based studying, which makes the agent geared up with complete purposeful information.
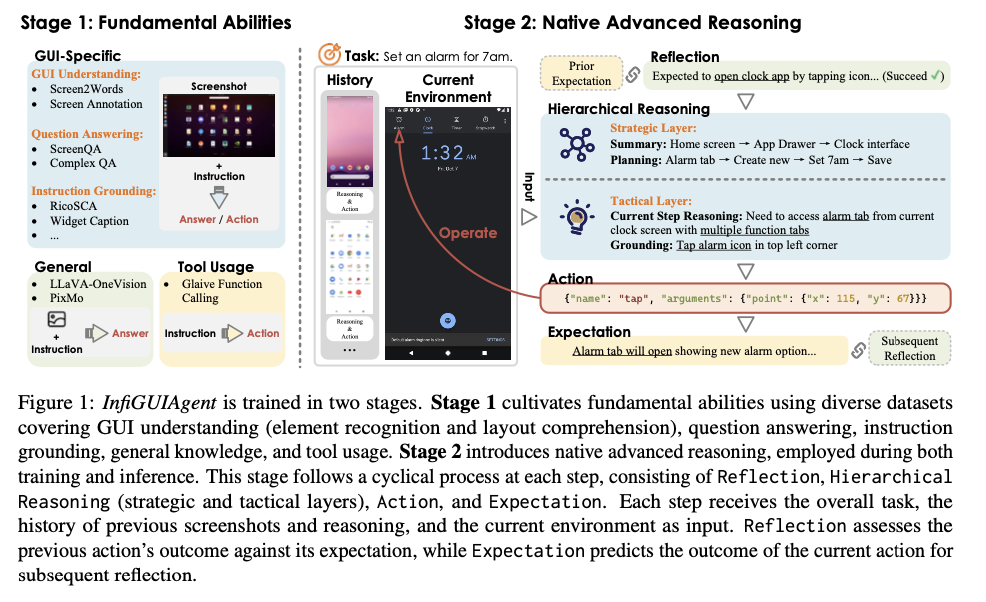
Within the subsequent section, superior reasoning capabilities are integrated via synthesized trajectory info, thus supporting hierarchical and expectation-reflection reasoning processes. The hierarchical reasoning framework comprises a bifurcated structure: a strategic part targeted on process decomposition and a tactical part on correct motion choice. Expectation-reflection reasoning permits the agent to regulate and self-correct via the evaluation of what was anticipated versus what occurred, thus bettering efficiency in several and dynamic contexts. This two-stage framework allows the system to natively deal with multi-step duties with out textual augmentations, therefore permitting for larger robustness and computational effectivity.
InfiGUIAgent was applied by fine-tuning Qwen2-VL-2B utilizing ZeRO0 know-how for environment friendly useful resource administration throughout GPUs. A reference-augmented annotation format was used to standardize and enhance the standard of the dataset in order that GUI parts might be exactly spatially referenced. Curating the datasets will increase GUI comprehension, grounding, and QA capabilities to carry out duties corresponding to semantic interpretation and modeling of interplay. The synthesized knowledge was then used for reasoning to make sure that all process protection was coated via trajectory-based annotations just like real-world interactions with the GUI. Such modularity in motion area design lets the agent reply dynamically to a number of platforms, which provides it larger flexibility and applicability.
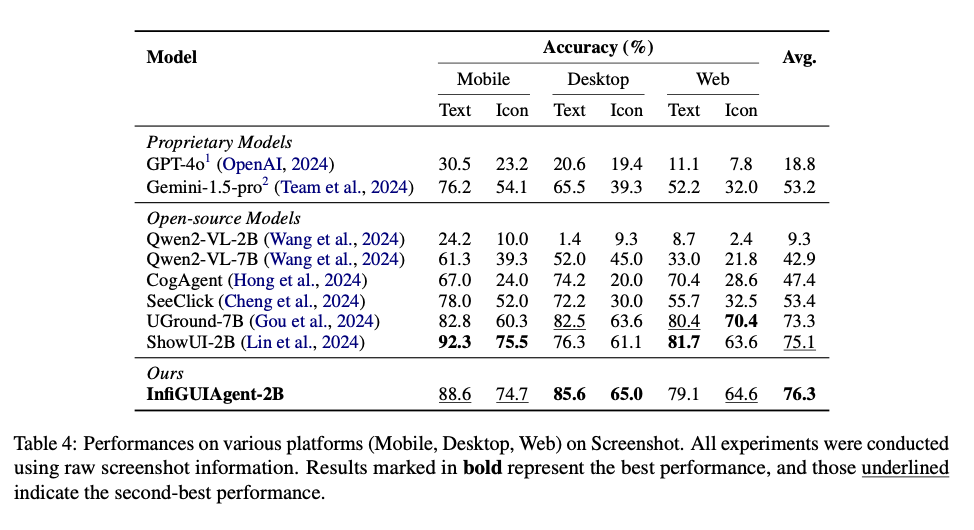
InfiGUIAgent did exceptionally properly in benchmark exams, far surpassing the state-of-the-art fashions each in accuracy and adaptableness. It managed to realize 76.3% accuracy on the ScreenSpot benchmark, exhibiting the next skill to floor GUI throughout cell, desktop, and net platforms. For dynamic environments corresponding to AndroidWorld, the agent was in a position to have a hit price of 0.09, which is larger than different related fashions with even larger parameter counts. The outcomes verify that the system can proficiently perform complicated, multistep duties with precision and adaptableness whereas underlining the effectiveness of its hierarchical and reflective reasoning fashions.
InfiGUIAgent represents a breakthrough within the realm of GUI automation and solves key the explanation why present instruments endure from essential limitations in reasoning and adaptableness. With out requiring any textual augmentations, this state-of-the-art efficiency is derived by integrating mechanisms for hierarchical process decomposition and reflective studying right into a multimodal framework. The brand new benchmarking supplied right here kinds a gap for creating the next-generation GUI brokers seamlessly embeddable in actual functions for environment friendly and sturdy process execution.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 65k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Enhance LLM Accuracy with Artificial Information and Analysis Intelligence–Be part of this webinar to realize actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding knowledge privateness.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.