{kind=link}

Massive Language Fashions (LLMs) intention to align with human preferences, guaranteeing dependable and reliable decision-making. Nevertheless, these fashions purchase biases, logical leaps, and hallucinations, rendering them invalid and innocent for important duties involving logical considering. Logical consistency issues make it inconceivable to develop logically constant LLMs. Additionally they use temporal reasoning, optimization, and automatic methods, leading to much less dependable conclusions.
Present strategies for aligning Massive Language Fashions (LLMs) with human preferences depend on supervised coaching with instruction-following knowledge and reinforcement studying from human suggestions. Nevertheless, these strategies endure from issues resembling hallucination, bias, and logical inconsistency, thereby undermining the validity of LLMs. Most enhancements to LLM consistency have thus been made on easy factual information or easy entailment between only a few statements whereas neglecting different, extra intricate decision-making eventualities or duties involving a couple of merchandise. This hole limits their capability to supply coherent and reliable reasoning in real-world purposes the place consistency is crucial.
To guage logical consistency in giant language fashions (LLMs), researchers from the College of Cambridge and Monash College proposed a common framework to quantify the logical consistency by assessing three key properties: transitivity, commutativity, and negation invariance. Transitivity ensured that if a mannequin decided that one merchandise was most popular over a second and the second over a 3rd, it additionally concluded that the primary merchandise was chosen over the third. Commutativity ensured that the mannequin’s judgments remained the identical whatever the order during which the objects had been in contrast.
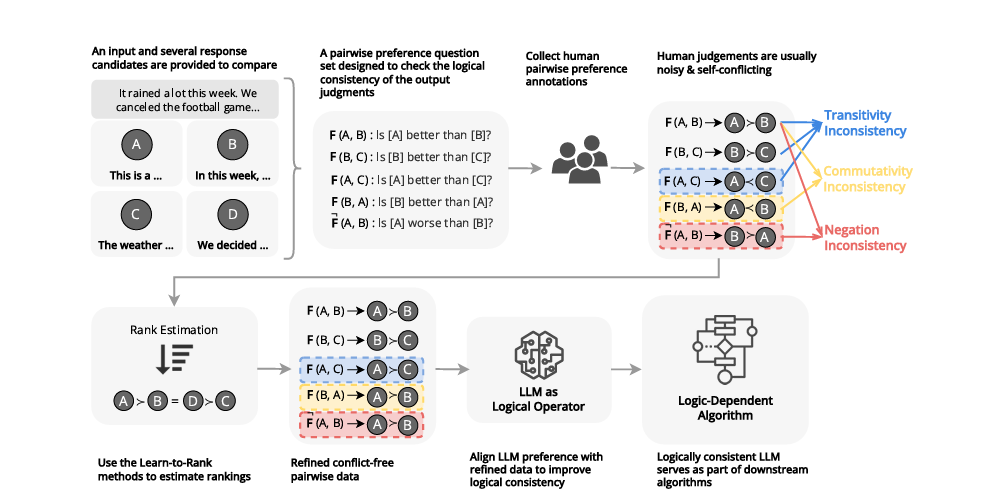
On the identical time, negation invariance was checked for consistency in dealing with relational negations. These properties fashioned the inspiration for dependable reasoning in fashions. The researchers formalized the analysis course of by treating an LLM as an operator perform FFF that in contrast pairs of things and assigned relational choices. Logical consistency was measured utilizing metrics like stran(Ok)s_{tran}(Ok)stran(Ok) for transitivity and scomms_{comm}scomm for commutativity. Stran (Ok)s_{tran}(Ok)stran(Ok) quantified transitivity by sampling subsets of things and detecting cycles within the relation graph. On the identical time, scomms_{comm}scomm evaluated whether or not the mannequin’s judgments remained steady when the order of things in comparisons was reversed. Each metrics ranged from 0 to 1, with increased values indicating higher efficiency.
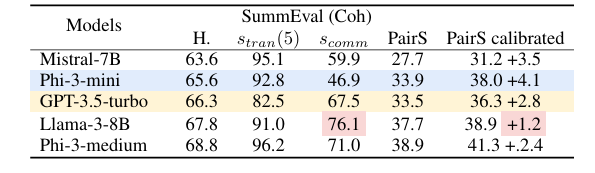
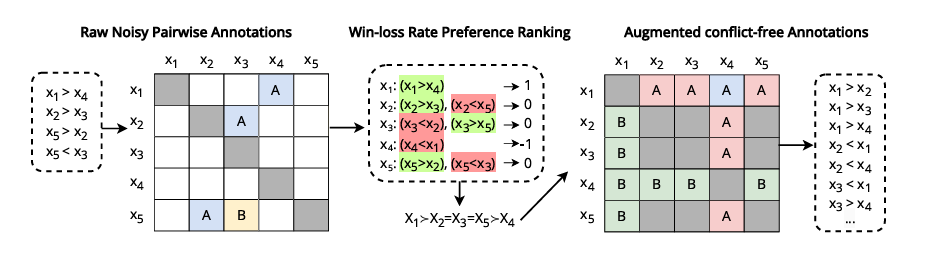
Researchers utilized these metrics to numerous LLMs, revealing vulnerabilities to biases like permutation and positional bias. To deal with this, they launched an information refinement and augmentation method utilizing rank aggregation strategies to estimate partial or ordered desire rankings from noisy or sparse pairwise comparisons. This improved logical consistency with out compromising alignment with human preferences and emphasised the important function of logical consistency in enhancing logic-dependent algorithm efficiency.
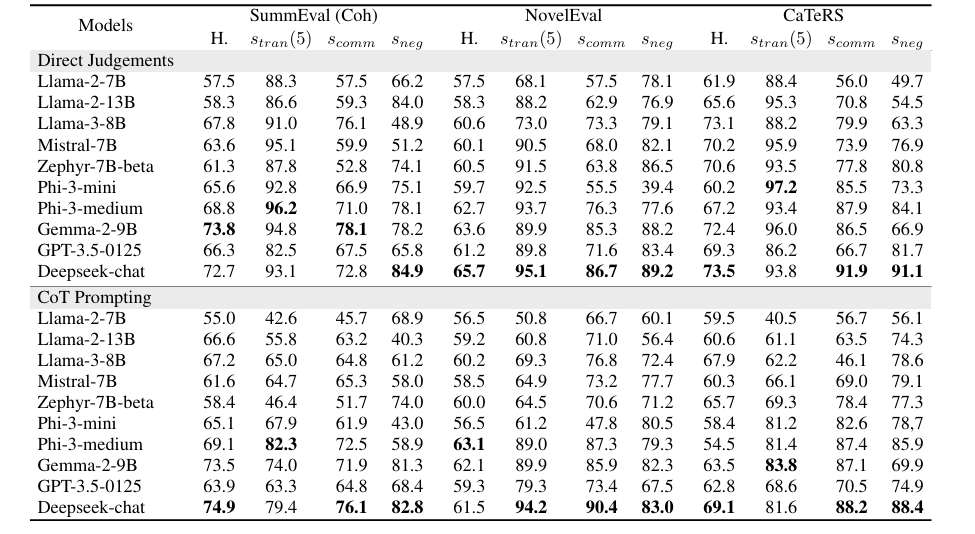
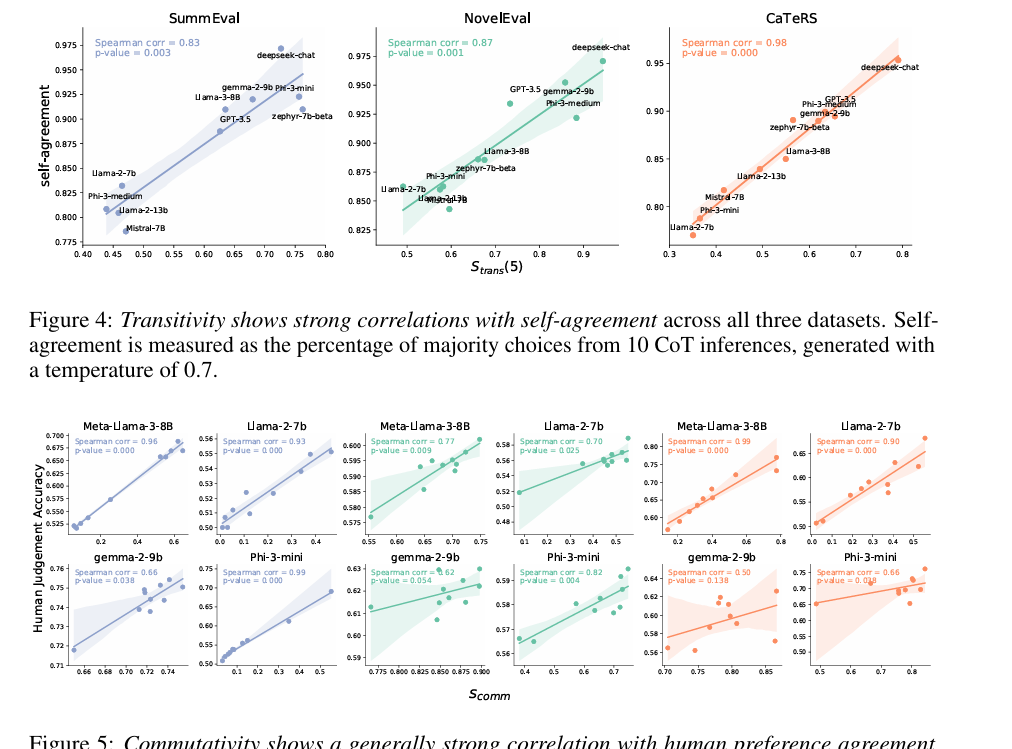
Researchers examined three duties to judge logical consistency in LLMs: abstractive summarization, doc reranking, and temporal occasion ordering utilizing datasets like SummEval, NovelEval, and CaTeRS. They assessed transitivity, commutativity, negation invariance, and human and self-agreement. Outcomes confirmed that newer fashions like Deepseek-chat, Phi-3-medium, and Gemma-2-9B had increased logical consistency, although this didn’t correlate strongly with human settlement accuracy. The CaTeRS dataset confirmed stronger consistency, specializing in temporal and causal relations. Chain-of-thought prompting had blended outcomes, generally decreasing transitivity as a result of added reasoning tokens. Self-agreement was associated to transitivity; this exhibits that constant reasoning is prime for logical consistency, and fashions resembling Phi-3-medium and Gemma-2-9B have equal reliability for every activity, emphasizing the need for cleaner coaching knowledge.
In the long run, researchers confirmed the significance of logical consistency in enhancing the reliability of enormous language fashions. They offered a technique for measuring the important thing elements of consistency and defined a data-cleaning course of that reduces the variety of defaults whereas nonetheless being pertinent to people. This framework can additional be used as a tenet for subsequent analysis in enhancing the consistency of LLMs and for persevering with efforts to implement LLMs into decision-making methods for enhanced effectiveness and productiveness.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Enhance LLM Accuracy with Artificial Information and Analysis Intelligence–Be a part of this webinar to achieve actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding knowledge privateness.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and clear up challenges.