{kind=link}

Language mannequin routing is a rising area centered on optimizing the utilization of huge language fashions (LLMs) for numerous duties. With capabilities spanning textual content technology, summarization, and reasoning, these fashions are more and more utilized to diverse enter information. The power to dynamically route particular duties to probably the most appropriate mannequin has turn out to be a vital problem, aiming to stability effectivity with accuracy in dealing with these multifaceted duties.
One main problem in deploying LLMs is choosing probably the most appropriate mannequin for a given enter process. Whereas quite a few pre-trained LLMs can be found, their efficiency can range considerably primarily based on the duty. Figuring out which mannequin to make use of for a selected enter historically entails counting on labeled datasets or human annotations. These resource-intensive strategies pose vital obstacles to scaling and generalization, significantly in functions requiring real-time choices or a variety of capabilities.
Current approaches for routing duties to LLMs usually contain auxiliary coaching or heuristic-based choice. These strategies typically depend upon labeled datasets to rank or predict the best-performing mannequin for a given enter. Whereas efficient to a point, these methods are restricted by the supply of high-quality annotated information and the computational prices of coaching auxiliary fashions. Consequently, the broader applicability of those strategies stays constrained.
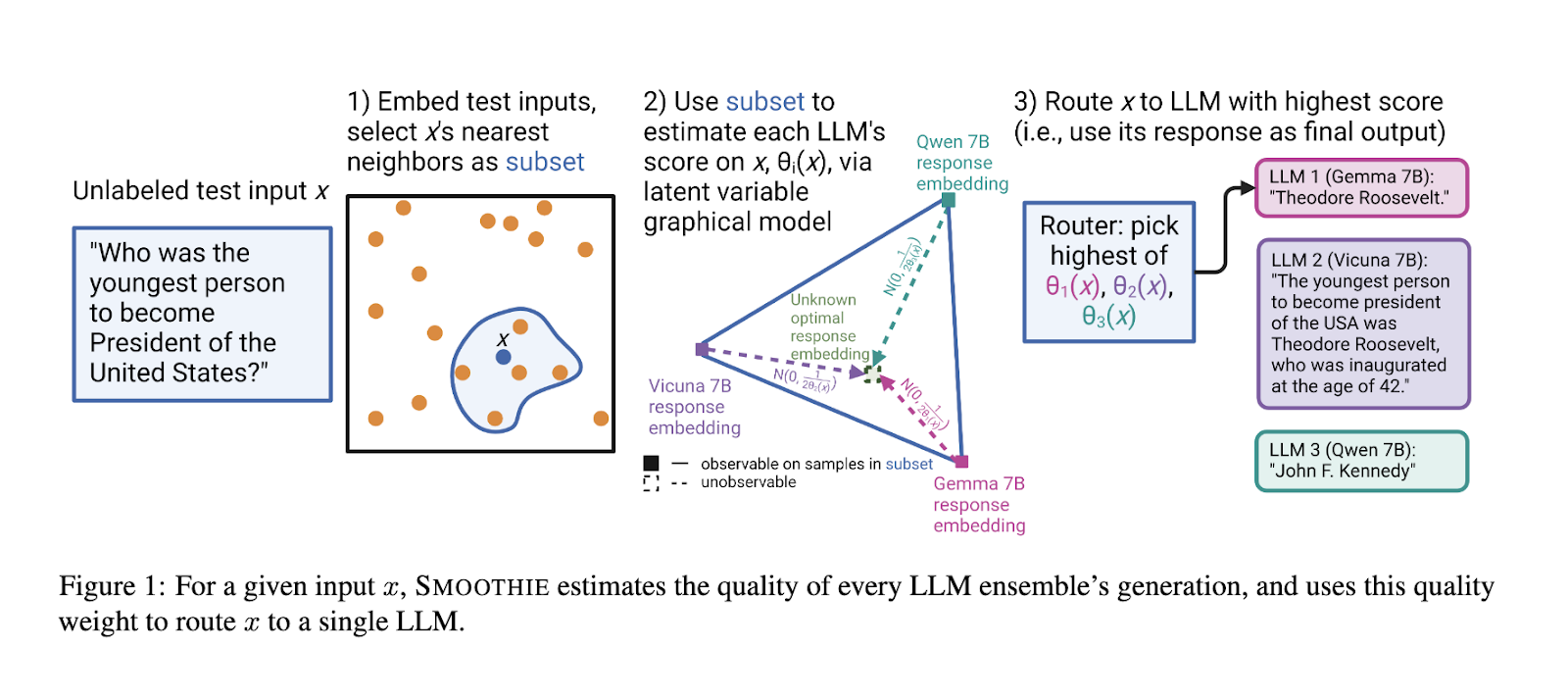
Researchers from Stanford College have launched SMOOTHIE, an progressive unsupervised language mannequin routing strategy designed to beat the constraints of labeled information. SMOOTHIE leverages rules from weak supervision, using a latent variable graphical mannequin to guage the outputs of a number of LLMs. By estimating sample-specific high quality scores, the strategy routes every enter to the LLM more than likely to provide optimum outcomes. This strategy gives a novel answer by eliminating the dependency on labeled datasets, considerably decreasing useful resource necessities.
SMOOTHIE consists of two main variations: SMOOTHIE-GLOBAL and SMOOTHIE-LOCAL. SMOOTHIE-GLOBAL derives high quality estimates for all check information, making a broad mannequin efficiency analysis. Conversely, SMOOTHIE-LOCAL refines this course of by specializing in the closest neighbors of a pattern within the embedding area, enhancing precision in routing. The methodology employs embedding representations of observable outputs and latent variables to mannequin variations between generated outputs and hypothetical true outputs. These variations are represented as a multivariate Gaussian, permitting the researchers to derive closed-form estimators for high quality scores. The tactic additionally incorporates kernel smoothing in SMOOTHIE-LOCAL to additional tailor high quality estimates to particular person samples, guaranteeing that routing choices are dynamically optimized.
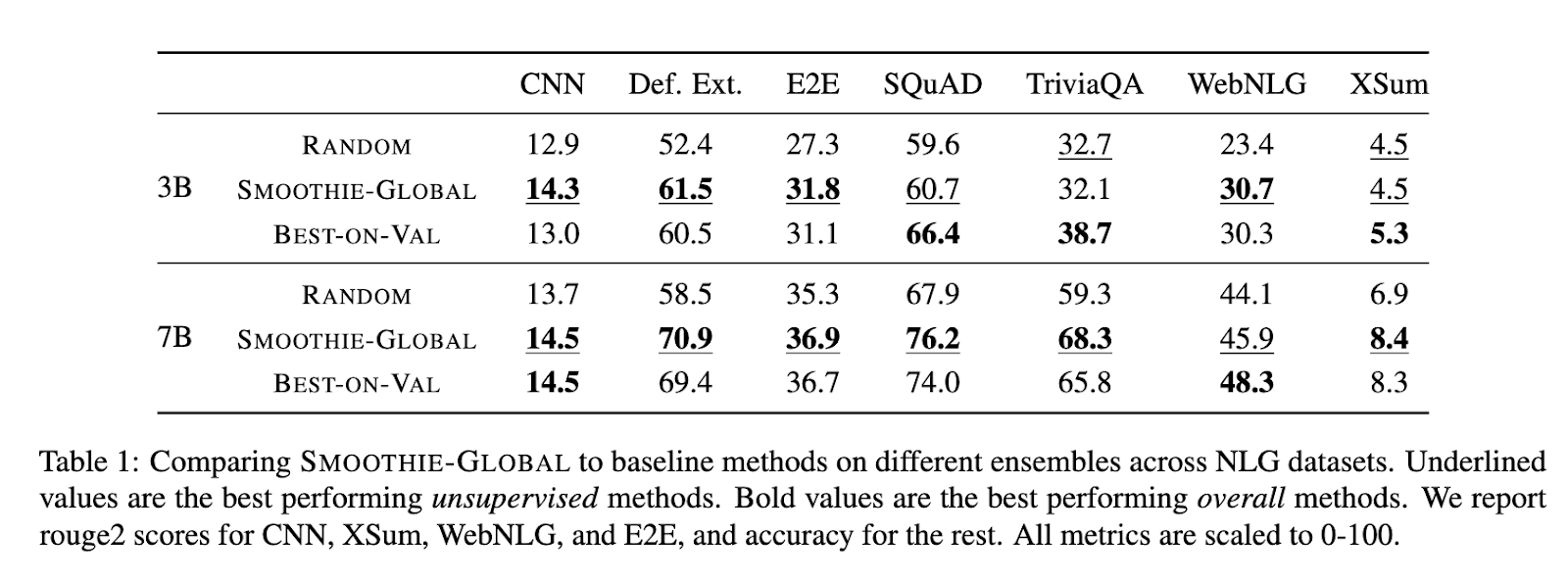
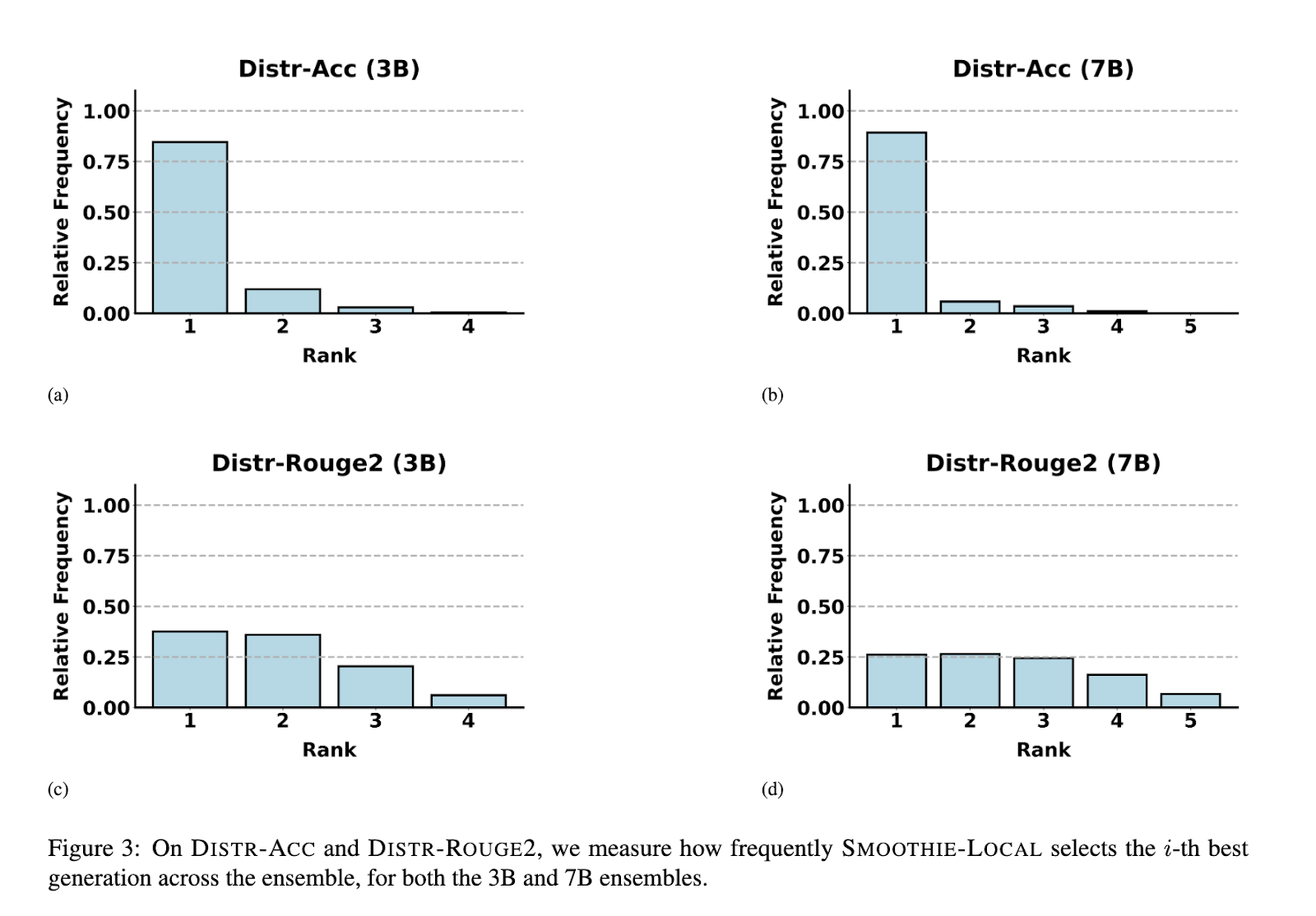
The efficiency of SMOOTHIE was evaluated extensively throughout a number of datasets and settings. SMOOTHIE-GLOBAL demonstrated its functionality to determine the best-performing mannequin in 9 out of 14 duties. For example, on datasets corresponding to AlpacaEval, SMOOTHIE-GLOBAL improved win charges by as much as 15 share factors in comparison with random-selection baselines and by 8 factors on SQuAD. The LOCAL variant additional excelled, outperforming international and supervised routing strategies in multi-task eventualities. In mixed-task datasets, SMOOTHIE-LOCAL improved process accuracy by as much as 10 factors over baseline strategies. Moreover, it achieved robust correlations between estimated and precise mannequin high quality, with a rank correlation coefficient of 0.72 on pure language technology duties and 0.94 on MixInstruct. SMOOTHIE’s native routing enabled smaller fashions to outperform bigger counterparts in a number of configurations, highlighting its effectiveness in resource-efficient eventualities.
The outcomes underscore SMOOTHIE’s potential to rework LLM routing by addressing the reliance on labeled information and auxiliary coaching. Combining weak supervision strategies with progressive high quality estimation fashions permits strong and environment friendly routing choices in multi-capability environments. The analysis presents a scalable and sensible answer for enhancing LLM efficiency, paving the best way for broader adoption in real-world functions the place process variety and accuracy are paramount.
This analysis signifies a pivotal development within the area of language mannequin routing. Addressing challenges in task-specific LLM choice with an unsupervised strategy opens avenues for bettering the deployment of LLMs throughout numerous functions. The introduction of SMOOTHIE streamlines the method and ensures a big enhancement in output high quality, demonstrating the rising potential of weak supervision in synthetic intelligence.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.