{kind=link}
 Method for Enhancing the Pattern High quality of Diffusion Generative Fashions")
Diffusion fashions are carefully linked to imitation studying as a result of they generate samples by progressively refining random noise into significant knowledge. This course of is guided by behavioral cloning, a typical imitation studying method the place the mannequin learns to repeat an skilled’s actions step-by-step. For diffusion fashions, the predefined course of transforms noise right into a remaining pattern, and following this course of ensures high-quality ends in numerous duties. Nonetheless, behavioral cloning additionally causes gradual era velocity. This occurs as a result of the mannequin is skilled to comply with an in depth path with many small steps, typically requiring tons of or 1000’s of calculations. Nonetheless, these steps are computationally costly when it comes to time and require numerous computation, and taking fewer steps to generate reduces the standard of the mannequin.
Present strategies optimize the sampling course of with out altering the mannequin, reminiscent of tuning noise schedules, enhancing differential equation solvers, and utilizing non–Markovian strategies. Others improve the standard of the pattern by coaching neural networks for short-run sampling. Distillation methods present promise however normally carry out beneath instructor fashions. Nonetheless, adversarial or reinforcement studying strategies could surpass them. RL updates the diffusion fashions based mostly on reward indicators utilizing coverage gradients or completely different worth capabilities.
To unravel this, researchers from the Korea Institute for Superior Examine, Seoul Nationwide College, College of Seoul, Hanyang College, and Saige Analysis proposed two developments in diffusion fashions. The primary method, known as Diffusion by Most Entropy Inverse Reinforcement Studying (DxMI), mixed two strategies: diffusion and Vitality-Based mostly Fashions (EBM). On this technique, EBM used rewards to measure how good the outcomes have been. The objective was to regulate the reward and entropy (uncertainty) within the diffusion mannequin to make coaching extra secure and be certain that each fashions carried out effectively with the information. The second development, Diffusion by Dynamic Programming (DxDP), launched a reinforcement studying algorithm that simplified entropy estimation by optimizing an higher sure of the target and eradicated the necessity for back-propagation via time by framing the duty as an optimum management drawback, making use of dynamic programming for quicker and extra environment friendly convergence.

The experiments demonstrated DxMI’s effectiveness in coaching diffusion and energy-based fashions (EBMs) for duties like picture era and anomaly detection. For 2D artificial knowledge, DxMI improved pattern high quality and vitality operate accuracy with a correct entropy regularization parameter. It was demonstrated that pre-training with DDPM is beneficial however pointless for DxMI to operate. DxMI fine-tuned fashions reminiscent of DDPM and EDM with fewer era steps for picture era, which have been aggressive in high quality. In anomaly detection, the vitality operate of DxMI carried out higher in detecting and localizing anomalies on the MVTec-AD dataset. Entropy maximization improved efficiency by selling exploration and rising mannequin range.
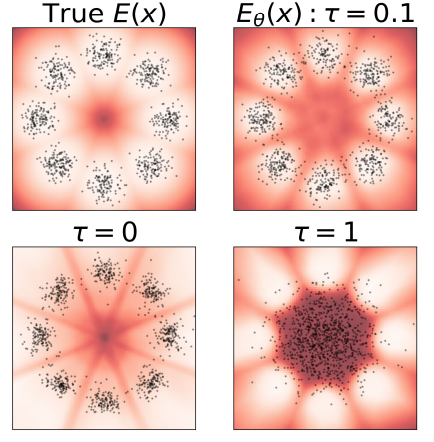
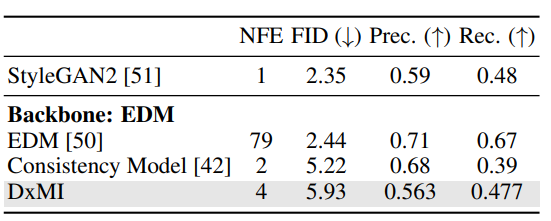
In abstract, the proposed technique drastically advances the effectivity and high quality of diffusion generative fashions by utilizing the DxMI method. It solves the problems of earlier strategies, reminiscent of gradual era speeds and degraded pattern high quality. Nonetheless, it’s not immediately appropriate for coaching single-step mills, however a diffusion mannequin fine-tuned by DxMI might be transformed into one. DxMI lacks the pliability to make use of completely different era steps throughout testing. This technique can be utilized for upcoming analysis on this area and function a baseline, making a big distinction!
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 60k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and resolve challenges.