{kind=link}

Board video games have lengthy been pivotal in shaping AI, serving as structured environments for testing decision-making and technique. Video games like chess and Join 4, with their distinct guidelines and ranging ranges of complexity, have enabled AI methods to be taught dynamic problem-solving. The structured nature of those video games challenges AI to anticipate strikes, take into account opponents’ methods, and execute plans successfully.
Giant language fashions (LLMs) want assist in multi-step reasoning and planning. Their incapability to simulate sequences of actions and consider long-term outcomes hinders their software in situations requiring superior planning. This limitation is clear in video games, the place predicting future states and weighing the results of actions are essential. Addressing these deficiencies is crucial for real-world purposes demanding subtle decision-making. Conventional strategies for planning in AI, particularly in gaming contexts, rely closely on exterior engines and algorithms like Monte Carlo Tree Search (MCTS). These methods simulate potential recreation states and consider actions primarily based on predefined guidelines, typically requiring massive computational assets. Whereas efficient in attaining robust outcomes, these strategies rely on domain-specific instruments to trace authorized strikes and assess outcomes, limiting their flexibility and scalability. This dependency highlights the necessity for fashions that combine planning and reasoning with out exterior help.
Researchers at Google DeepMind, Google, and ETH Zürich launched the Multi-Motion-Worth (MAV) mannequin, a game-changing innovation in AI planning. The MAV mannequin leverages a Transformer-based structure skilled on huge datasets of textual recreation states to behave as a standalone decision-making system. Not like conventional methods, MAV performs state monitoring, predicts authorized strikes, and evaluates actions with out exterior recreation engines. Skilled on over 3.1 billion positions from video games like chess, Chess960, Hex, and Join 4, the MAV mannequin processes 54.3 billion motion values to tell its selections. This intensive pre-training minimizes errors, reminiscent of hallucinations, and ensures correct state predictions.
The MAV mannequin is a complete device able to dealing with world modeling, coverage era, and motion analysis. It processes recreation states utilizing a tokenized format, enabling exact monitoring of board dynamics. Key improvements embrace inner search mechanisms permitting the mannequin to discover choice timber autonomously, simulating and backtracking potential strikes. For instance, the MAV mannequin in chess makes use of 64 predefined worth buckets to categorise win possibilities, making certain exact evaluations. These options allow the MAV system to carry out complicated calculations and refine its methods in actual time, attaining unparalleled effectivity and accuracy.
In chess, the MAV mannequin achieved an Elo score of 2923, surpassing earlier AI methods like Stockfish L10. Its means to function on a transfer rely search price range much like human grandmasters highlights its effectivity. The mannequin additionally excelled in Chess960, leveraging its coaching on 1.2 billion positions to outpace conventional methods. In Join 4, MAV confirmed constant enhancements, with exterior search strategies enhancing decision-making by over 244 Elo factors. The MAV mannequin demonstrated potential even in Hex, the place state-tracking capabilities had been restricted.

Key takeaways from this analysis embrace:
- Complete Integration: MAV combines world modeling, coverage analysis, and motion prediction right into a single system, eliminating reliance on exterior engines.
- Improved Planning Effectivity: Inside and exterior search mechanisms considerably improve the mannequin’s means to purpose about future actions. With restricted computational assets, it achieves as much as 300 Elo level positive aspects in chess.
- Excessive Precision: The mannequin boasts near-perfect accuracy in state predictions. It achieves 99.9% precision and recall for authorized strikes in chess.
- Versatility Throughout Video games: MAV’s coaching on numerous datasets permits robust efficiency in a number of video games, with Chess960 and Join 4 showcasing adaptability and strategic depth.
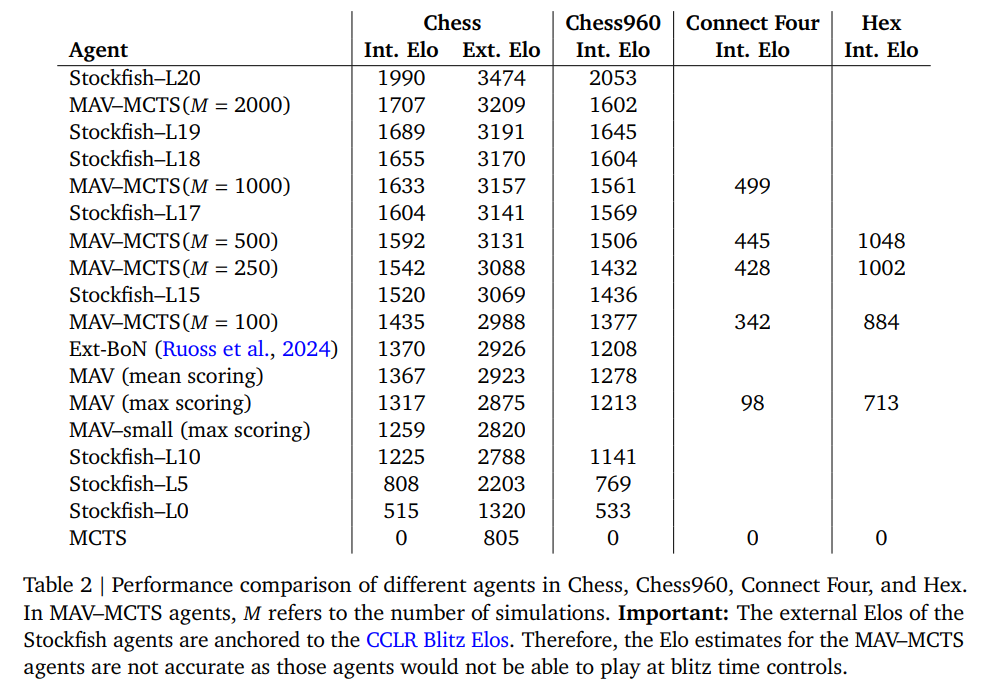
In conclusion, with over 3.1 billion coaching positions and 54.3 billion motion values, the MAV mannequin achieves distinctive efficiency throughout video games. It attains an Elo score of 2923 in chess, rivaling Grandmaster-level energy, whereas requiring solely 1000 simulations, far fewer than conventional methods like AlphaZero’s 10k. In Join 4, it improves decision-making by over 244 Elo factors by exterior search mechanisms. These outcomes emphasize MAV’s means to generalize throughout video games, preserve 99.9% transfer legality precision, and function effectively on human-comparable search budgets.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Remodel proofs-of-concept into production-ready AI purposes and brokers’ (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.