{kind=link}

Graph Convolutional Networks (GCNs) have develop into integral in analyzing advanced graph-structured information. These networks seize the relationships between nodes and their attributes, making them indispensable in domains like social community evaluation, biology, and chemistry. By leveraging graph buildings, GCNs allow node classification and hyperlink prediction duties, fostering developments in scientific and industrial functions.
Massive-scale graph coaching presents vital challenges, notably in sustaining effectivity and scalability. The irregular reminiscence entry patterns brought on by graph sparsity and the intensive communication required for distributed coaching make it troublesome to realize optimum efficiency. Furthermore, partitioning graphs into subgraphs for distributed computation creates imbalanced workloads and elevated communication overhead, additional complicating the coaching course of. Addressing these challenges is essential for enabling the coaching of GCNs on huge datasets.
Current strategies for GCN coaching embrace mini-batch and full-batch approaches. Mini-batch coaching reduces reminiscence utilization by sampling smaller subgraphs, permitting computations to suit inside restricted sources. Nevertheless, this methodology usually sacrifices accuracy because it must retain the entire construction of the graph. Whereas preserving the graph’s construction, full-batch coaching faces scalability points resulting from elevated reminiscence and communication calls for. Most present frameworks are optimized for GPU platforms, with a restricted deal with growing environment friendly options for CPU-based techniques.
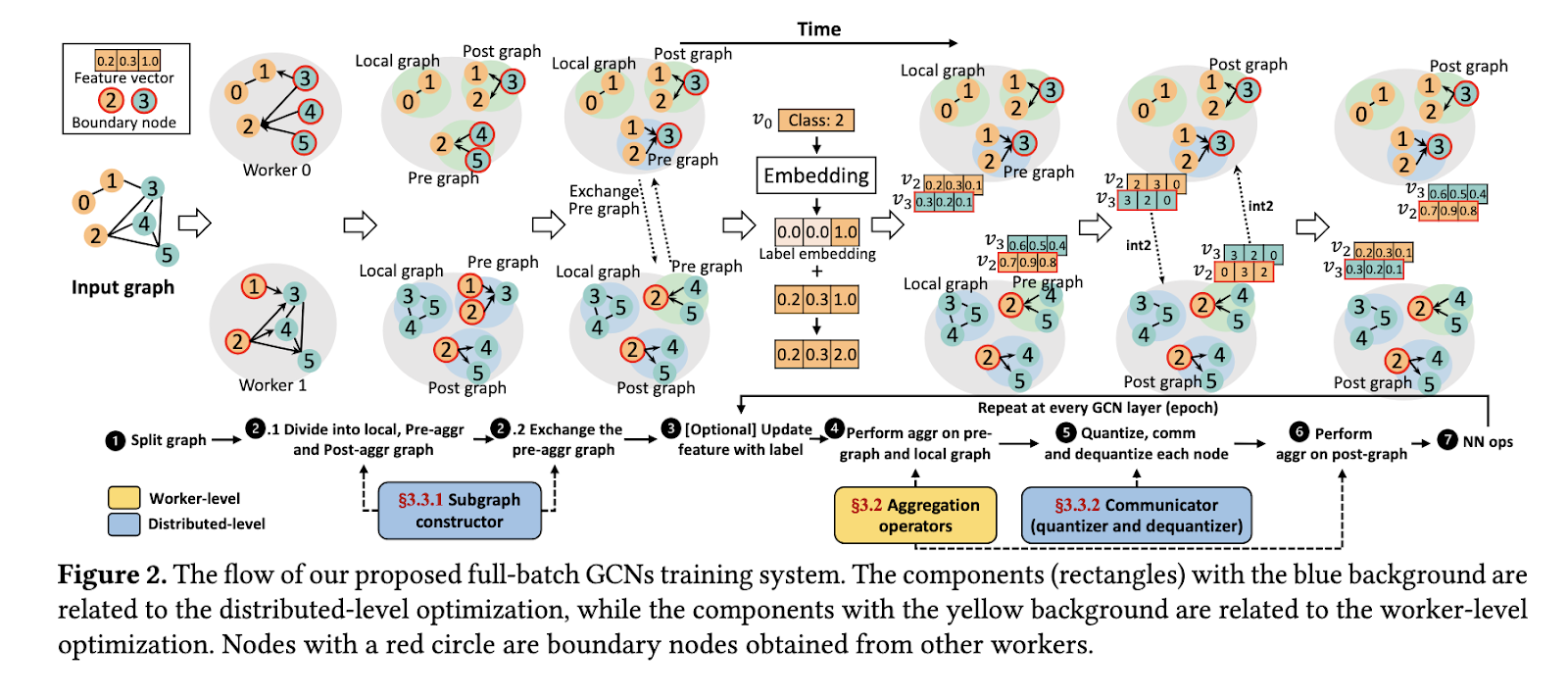
The analysis staff, together with collaborators from the Tokyo Institute of Know-how, RIKEN, the Nationwide Institute of Superior Industrial Science and Know-how, and Lawrence Livermore Nationwide Laboratory, have launched a novel framework known as SuperGCN. This method is tailor-made for CPU-powered supercomputers, addressing scalability and effectivity challenges in GCN coaching. The framework bridges the hole in distributed graph studying by specializing in optimized graph-related operations and communication discount strategies.
SuperGCN leverages a number of modern strategies to reinforce its efficiency. The framework employs optimized CPU-specific implementations of graph operators, guaranteeing environment friendly reminiscence utilization and balanced workloads throughout threads. The researchers proposed a hybrid aggregation technique that makes use of the minimal vertex cowl algorithm to categorize edges into pre- and post-aggregation units, lowering redundant communications. Moreover, the framework incorporates Int2 quantization to compress messages throughout communication, considerably reducing information switch volumes with out compromising accuracy. Label propagation is used alongside quantization to mitigate the consequences of decreased precision, guaranteeing convergence and sustaining excessive mannequin accuracy.
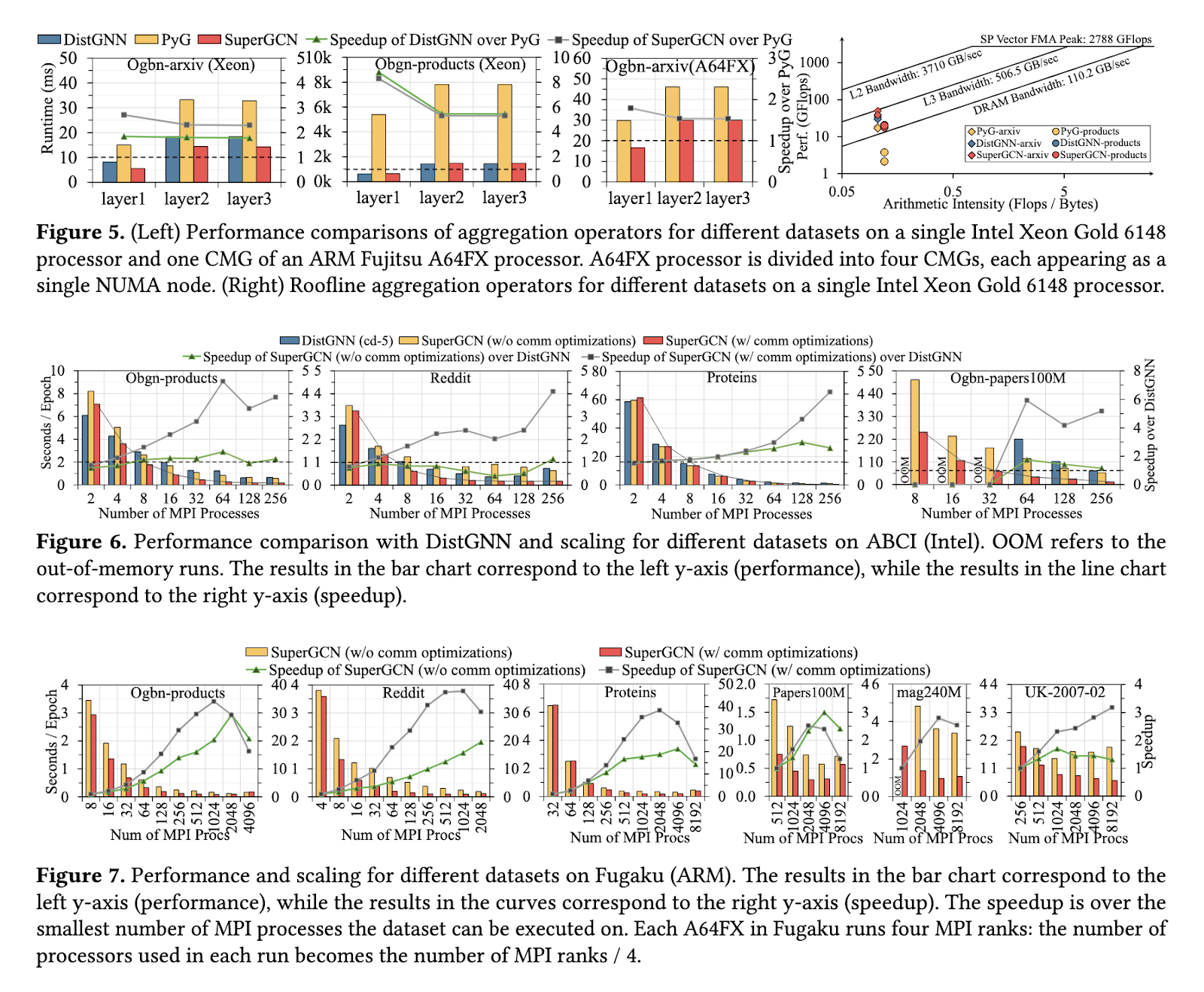
The efficiency of SuperGCN was evaluated on datasets akin to Ogbn-products, Reddit, and the large-scale Ogbn-papers100M, demonstrating outstanding enhancements over current strategies. The framework achieved as much as a sixfold speedup in comparison with Intel’s DistGNN on Xeon-based techniques, with efficiency scaling linearly because the variety of processors elevated. On ARM-based supercomputers like Fugaku, SuperGCN scaled to over 8,000 processors, showcasing unmatched scalability for CPU platforms. The framework achieved processing speeds similar to GPU-powered techniques, requiring considerably much less vitality and value. On Ogbn-papers100M, SuperGCN attained an accuracy of 65.82% with label propagation enabled, outperforming different CPU-based strategies.
By introducing SuperGCN, the researchers addressed crucial bottlenecks in distributed GCN coaching. Their work demonstrates that environment friendly, scalable options are achievable on CPU-powered platforms, offering an economical different to GPU-based techniques. This development marks a major step in enabling large-scale graph processing whereas preserving computational and environmental sustainability.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.