{kind=link}

Giant Language Fashions (LLMs) have demonstrated outstanding potential in performing complicated duties by constructing clever brokers. As people more and more have interaction with the digital world, these fashions function digital embodied interfaces for a variety of each day actions. The rising subject of GUI automation goals to develop clever brokers that may considerably streamline human workflows based mostly on person intentions. This technological development represents a pivotal second in human-computer interplay, the place refined language fashions can interpret and execute complicated digital duties with rising precision and effectivity.
Early makes an attempt at GUI automation targeted on language-based brokers that relied on closed-source, API-based Giant Language Fashions like GPT-4. These preliminary approaches primarily utilized text-rich metadata reminiscent of HTML inputs and accessibility timber to carry out navigation and associated duties. Nevertheless, this text-only methodology reveals important limitations in real-world functions, the place customers predominantly work together with interfaces visually by way of screenshots, usually with out entry to underlying structural data. The basic problem lies in bridging the hole between computational notion and human-like interplay with graphical person interfaces, necessitating a extra nuanced method to digital navigation and job execution.
Coaching multi-modal fashions for GUI visible brokers encounter important challenges throughout a number of dimensions of computational design. Visible modeling presents substantial obstacles, notably with high-resolution UI screenshots that generate prolonged token sequences and create long-context processing problems. Most present fashions battle to optimize such high-resolution knowledge effectively, leading to appreciable computational inefficiencies. Additionally, the complexity of managing interleaved vision-language-action interactions provides one other layer of complexity, with actions various dramatically throughout totally different system platforms and requiring refined modeling strategies to precisely interpret and execute navigation processes successfully.
Researchers from Present Lab, the Nationwide College of Singapore and Microsoft introduce ShowUI, a singular vision-language-action mannequin designed to handle key challenges in GUI automation. The mannequin incorporates three progressive strategies: UI-Guided Visible Token Choice, which reduces computational prices by remodeling screenshots into related graphs and intelligently figuring out redundant relationships; Interleaved Imaginative and prescient-Language-Motion Streaming, enabling versatile administration of visual-action histories and multi-turn query-action sequences; and a sturdy method to creating small-scale, high-quality GUI instruction-following datasets by way of meticulous knowledge curation and strategic resampling to mitigate knowledge sort imbalances. These developments intention to considerably improve the effectivity and effectiveness of GUI visible brokers.
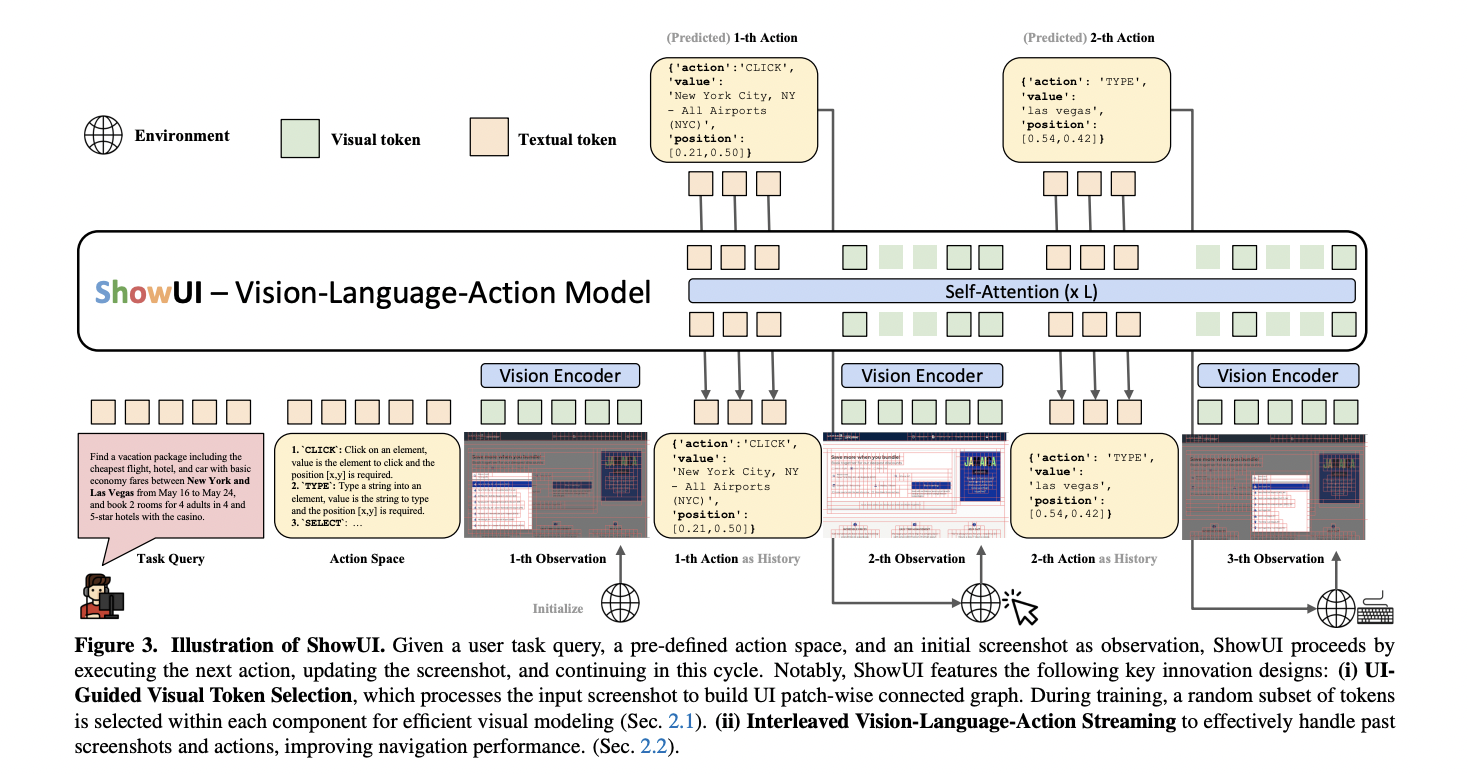
UI-guided visible Token Choice technique addresses computational challenges inherent in processing high-resolution screenshots. By recognizing the elemental variations between pure photos and person interfaces, the tactic develops an progressive method to token discount. Using the RGB colour house, researchers assemble a UI related graph that identifies and teams visually redundant patches whereas preserving functionally essential components like icons and textual content. The approach adaptively manages visible token complexity, demonstrating outstanding effectivity by lowering token sequences from 1296 to as few as 291 in sparse areas like Google search pages, whereas sustaining extra granular illustration in text-rich environments like Overleaf screenshots.
Interleaved Imaginative and prescient-Language-Motion (VLA) Streaming method addresses complicated GUI navigation challenges. By structuring actions in a standardized JSON format, the mannequin can handle numerous device-specific motion variations and novel interplay eventualities. The tactic introduces a versatile framework that allows motion prediction throughout totally different platforms by offering a complete ‘README’ system immediate that guides the mannequin’s understanding of motion areas. This method permits for dynamic motion execution by way of a function-calling mechanism, successfully standardizing interactions throughout net and cellular interfaces whereas sustaining the flexibility to deal with distinctive device-specific necessities.
GUI Tutorial Tuning method rigorously curates coaching knowledge from numerous sources, addressing essential challenges in dataset assortment and illustration. By analyzing varied GUI datasets, the group developed a nuanced methodology for knowledge choice and augmentation. For web-based interfaces, they collected 22K screenshots, focusing solely on visually wealthy components like buttons and checkboxes, strategically filtering out static textual content. For desktop environments, the researchers employed progressive reverse engineering strategies, utilizing GPT-4o to rework restricted authentic annotations into wealthy, multi-dimensional queries spanning look, spatial relationships, and person intentions, successfully increasing the dataset’s complexity and utility.


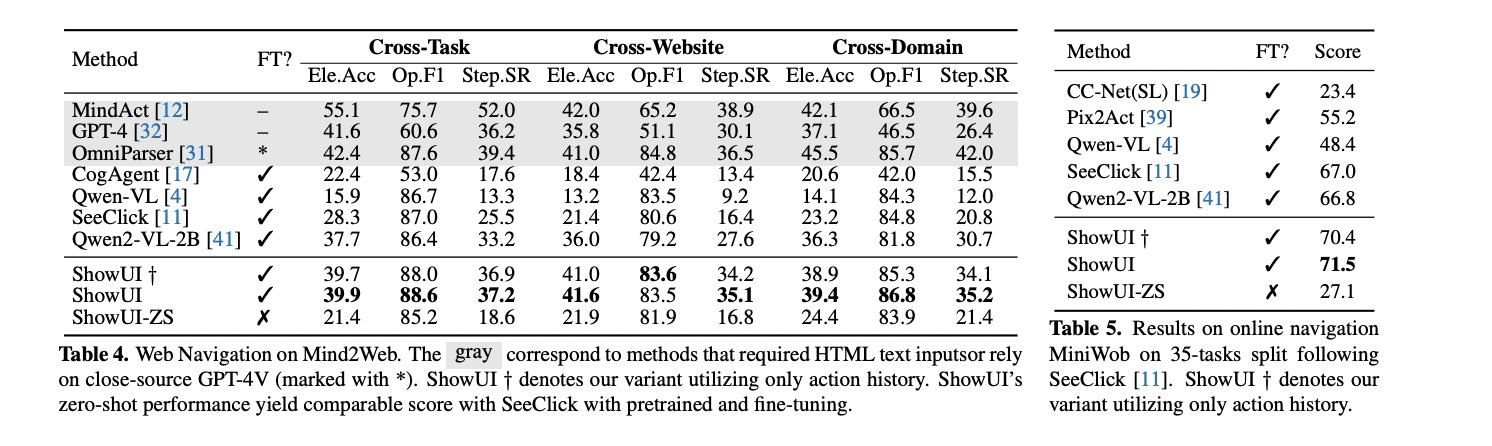
The experimental analysis of ShowUI throughout numerous navigation duties reveals essential insights into the mannequin’s efficiency and potential enhancements. Experiments carried out on cellular platforms like AITW demonstrated that incorporating visible historical past considerably enhances navigation accuracy, with ShowUI reaching a 1.7% accuracy acquire. The zero-shot navigation capabilities realized from GUIAct confirmed promising transferability, outperforming strategies counting on closed-source APIs or HTML data. Notably, the efficiency diverse throughout totally different domains, with net navigation duties presenting distinctive challenges that highlighted the significance of visible notion and area range in coaching knowledge.
ShowUI represents a major development in vision-language-action fashions for GUI interactions. The researchers developed progressive options to handle essential challenges in UI visible modeling and motion processing. By introducing UI-Guided Visible Token Choice, the mannequin effectively processes high-resolution screenshots, dramatically lowering computational overhead. The Interleaved Imaginative and prescient-Language-Motion Streaming framework allows refined administration of complicated cross-modal interactions, permitting for extra nuanced and context-aware navigation. By means of meticulous knowledge curation and a high-quality instruction-following dataset, ShowUI demonstrates outstanding efficiency, notably spectacular given its light-weight mannequin measurement. These achievements sign a promising path towards growing GUI visible brokers that may work together with digital interfaces in methods extra intently resembling human notion and decision-making.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 55k+ ML SubReddit.
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.