{kind=link}

Giant language fashions (LLMs) have remodeled the panorama of pure language processing, changing into indispensable instruments throughout industries similar to healthcare, training, and know-how. These fashions carry out complicated duties, together with language translation, sentiment evaluation, and code technology. Nonetheless, their exponential progress in scale and adoption has launched vital computational challenges. Every activity typically requires fine-tuned variations of those fashions, resulting in excessive reminiscence and vitality calls for. Effectively managing the inference course of in environments with concurrent queries for numerous duties is essential for sustaining their usability in manufacturing programs.
Inference clusters serving LLMs face basic problems with workload heterogeneity and reminiscence inefficiencies. Present programs encounter excessive latency because of frequent adapter loading and scheduling inefficiencies. Adapter-based fine-tuning strategies, similar to Low-Rank Adaptation (LoRA), allow fashions to focus on duties by modifying smaller parts of the bottom mannequin parameters. Whereas LoRA considerably reduces reminiscence necessities, it introduces new challenges. These embody elevated rivalry on reminiscence bandwidth throughout adapter masses and delays from head-of-line blocking when requests of various complexities are processed sequentially. These inefficiencies restrict the scalability and responsiveness of inference clusters underneath heavy workloads.

Present options try to deal with these challenges however have to catch up in essential areas. For example, strategies like S-LoRA retailer base mannequin parameters in GPU reminiscence and cargo adapters on-demand from host reminiscence. This strategy results in efficiency penalties because of adapter fetch instances, significantly in high-load eventualities the place PCIe hyperlink bandwidth turns into a bottleneck. Scheduling insurance policies similar to FIFO (First-In, First-Out) and SJF (Shortest-Job-First) have been explored to handle the range in request sizes, however each approaches fail underneath excessive load. FIFO typically causes head-of-line blocking for smaller requests, whereas SJF results in hunger of longer requests, leading to missed service degree aims (SLOs).
Researchers from the College of Illinois Urbana-Champaign and IBM Analysis launched Chameleon, an revolutionary LLM inference system designed to optimize environments with quite a few task-specific adapters. Chameleon combines adaptive caching and a complicated scheduling mechanism to mitigate inefficiencies. It employs GPU reminiscence extra successfully by caching incessantly used adapters, thus decreasing the time required for adapter loading. Additionally, the system makes use of a multi-level queue scheduling coverage that dynamically prioritizes duties based mostly on useful resource wants and execution time.
Chameleon leverages idle GPU reminiscence to cache in style adapters, dynamically adjusting cache dimension based mostly on system load. This adaptive cache eliminates the necessity for frequent knowledge transfers between CPU and GPU, considerably decreasing rivalry on the PCIe hyperlink. The scheduling mechanism categorizes requests into size-based queues and allocates assets proportionally, guaranteeing no activity is starved. This strategy accommodates heterogeneity in activity sizes and prevents smaller requests from being blocked by bigger ones. The scheduler dynamically recalibrates queue priorities and quotas, optimizing efficiency underneath various workloads.
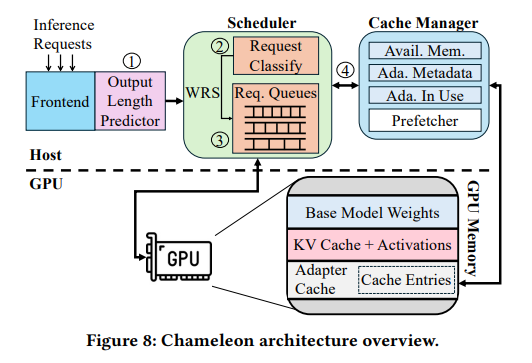
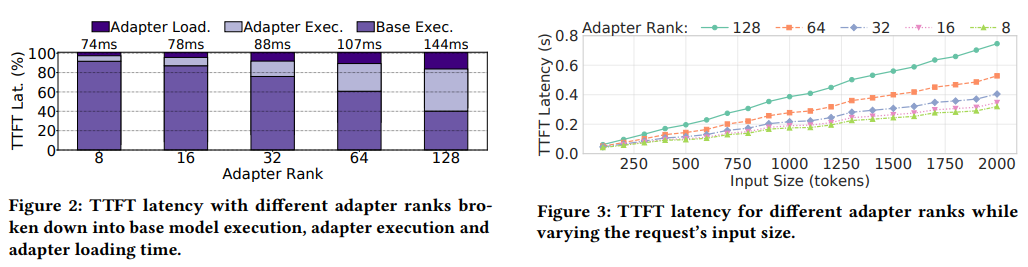
The system was evaluated utilizing real-world manufacturing workloads and open-source LLMs, together with the Llama-7B mannequin. Outcomes present that Chameleon reduces the P99 time-to-first-token (TTFT) latency by 80.7% and P50 TTFT latency by 48.1%, outperforming baseline programs like S-LoRA. Throughput improved by 1.5 instances, permitting the system to deal with increased request charges with out violating SLOs. Notably, Chameleon demonstrated scalability, effectively dealing with adapter ranks starting from 8 to 128 whereas minimizing the latency impression of bigger adapters.
Key Takeaways from the Analysis:
- Efficiency Good points: Chameleon decreased tail latency (P99 TTFT) by 80.7% and median latency (P50 TTFT) by 48.1%, considerably bettering response instances underneath heavy workloads.
- Enhanced Throughput: The system achieved 1.5x increased throughput than baseline strategies, permitting for extra concurrent requests.
- Dynamic Useful resource Administration: Adaptive caching successfully utilized idle GPU reminiscence, dynamically resizing the cache based mostly on system demand to reduce adapter reloads.
- Modern Scheduling: The multi-level queue scheduler eradicated head-of-line blocking and ensured honest useful resource allocation, stopping hunger of bigger requests.
- Scalability: Chameleon effectively supported adapter ranks from 8 to 128, demonstrating its suitability for numerous activity complexities in multi-adapter settings.
- Broader Implications: This analysis units a precedent for designing inference programs that stability effectivity and scalability, addressing real-world manufacturing challenges in deploying large-scale LLMs.

In conclusion, Chameleon introduces vital developments for LLM inference in multi-adapter environments. Leveraging adaptive caching and a non-preemptive multi-level queue scheduler optimizes reminiscence utilization and activity scheduling. The system effectively addresses adapter loading and heterogeneous request dealing with points, delivering substantial efficiency enhancements.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.