{kind=link}

Pure language processing (NLP) continues to evolve with new strategies like in-context studying (ICL), which presents modern methods to reinforce giant language fashions (LLMs). ICL entails conditioning fashions on particular instance demonstrations with out straight modifying the mannequin’s parameters. This technique is particularly priceless for coaching LLMs shortly for numerous duties. Nevertheless, ICL may be extremely resource-intensive, particularly in Transformer-based fashions the place reminiscence calls for scale with the variety of enter examples. This limitation implies that because the variety of demonstrations will increase, each computational complexity and reminiscence utilization develop considerably, probably exceeding the fashions’ processing capability and impacting efficiency. As NLP programs intention for higher effectivity and robustness, optimizing how demonstrations are dealt with in ICL has change into an important analysis focus.
A key concern ICL addresses is learn how to successfully use demonstration information with out exhausting computational assets or reminiscence. In conventional setups, ICL implementations have relied on concatenating all demonstrations right into a single sequence, a way often known as concat-based ICL. Nevertheless, this strategy should distinguish every demonstration’s high quality or relevance, usually resulting in suboptimal efficiency. Additionally, concat-based ICL should work on contextual limitations when dealing with giant datasets, which can inadvertently embrace irrelevant or noisy information. This inefficiency makes coaching extra resource-intensive and negatively impacts mannequin accuracy. Choosing demonstrations that precisely signify activity necessities whereas managing reminiscence calls for stays a big hurdle for efficient in-context studying.
Concatenation-based strategies, whereas easy, want to enhance when it comes to effectively utilizing accessible demonstrations. These strategies mix all examples with out regard for each’s relevance, usually resulting in redundancy and reminiscence overload. Present methods largely depend on heuristics, which lack precision and scalability. This limitation, coupled with the rising computational expense, creates a bottleneck that hampers the potential of ICL. Furthermore, concatenating all examples implies that the self-attention mechanism in Transformer fashions, which scales quadratically with enter size, additional intensifies reminiscence pressure. This quadratic scaling problem is a major impediment in enabling ICL to function successfully throughout diversified datasets and duties.
Researchers from the College of Edinburgh and Miniml.AI developed the Mixtures of In-Context Learners (MoICL) technique. MoICL introduces a brand new framework for dealing with demonstrations by dividing them into smaller, specialised subsets often known as “consultants.” Every skilled subset processes a portion of the demonstrations and produces a predictive output. A weighting perform, designed to optimize using every skilled subset, dynamically merges these outputs. This perform adjusts based mostly on the dataset and activity necessities, enabling the mannequin to make the most of reminiscence assets effectively. MoICL thus supplies a extra adaptable and scalable strategy to in-context studying, demonstrating notable efficiency enhancements over conventional strategies.
The mechanism underlying MoICL facilities on its dynamic weighting perform, which mixes predictions from skilled subsets to type a remaining, complete output. Researchers can select between scalar weights or a hyper-network, with every choice affecting the mannequin’s adaptability. Scalar weights, initialized equally, permit every skilled’s contribution to be tuned throughout coaching. Alternatively, a hyper-network can generate weights based mostly on context, optimizing outcomes for various enter subsets. This adaptability permits MoICL to perform successfully with various sorts of fashions, making it versatile for numerous NLP functions. MoICL’s partitioning system additionally reduces computational prices by limiting the necessity to course of the whole dataset as an alternative of selectively prioritizing related info.
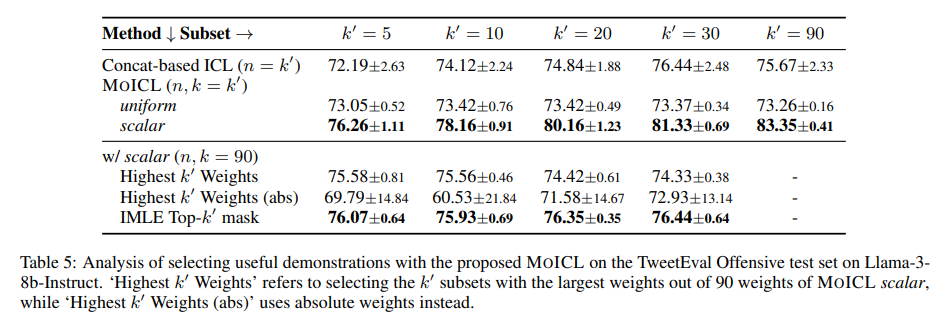
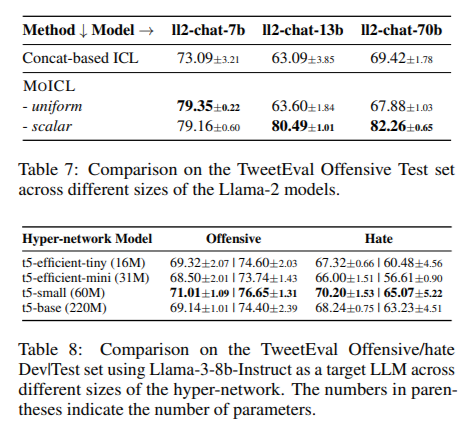
In checks throughout seven classification duties, MoICL constantly outperformed customary ICL strategies. For instance, it achieved as much as 13% greater accuracy on datasets like TweetEval, the place it reached 81.33% accuracy, and improved robustness to noisy information by 38%. The system additionally demonstrated resilience to label imbalances (as much as a 49% enchancment) and out-of-domain information (11% higher dealing with). Not like typical strategies, MoICL maintains steady efficiency even with imbalanced datasets or when uncovered to out-of-domain demonstrations. Through the use of MoICL, the researchers achieved enhanced reminiscence effectivity and quicker processing occasions, proving it to be each computationally and operationally environment friendly.
Key takeaways from the analysis:
- Efficiency Positive aspects: MoICL confirmed an accuracy enchancment of as much as 13% on TweetEval in comparison with customary strategies, with important positive factors in classification duties.
- Noise and Imbalance Robustness: The tactic improved resilience to noisy information by 38% and managed imbalanced label distributions by 49% higher than typical ICL strategies.
- Environment friendly Computation: MoICL diminished inference occasions with out sacrificing accuracy, displaying information and reminiscence effectivity.
- Generalizability: MoICL demonstrated sturdy adaptability to totally different mannequin varieties and NLP duties, offering a scalable resolution for memory-efficient studying.
- Out-of-Area Dealing with: MoICL is powerful towards sudden information variations, with a documented 11% enchancment in managing out-of-domain examples.

In conclusion, MoICL represents a big development in ICL by overcoming reminiscence constraints and delivering constantly greater efficiency. By leveraging skilled subsets and making use of weighting capabilities, it presents a extremely environment friendly technique for demonstration choice. This technique mitigates the constraints of concat-based approaches and delivers sturdy accuracy throughout diversified datasets, making it extremely related for future NLP duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Group Members
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.