
The present design of causal language fashions, comparable to GPTs, is intrinsically burdened with the problem of semantic coherence over longer stretches due to their one-token-ahead prediction design. This has enabled important generative AI growth however usually results in “matter drift” when longer sequences are produced since every token predicted relies upon solely on the presence of mere previous tokens, not from a broader perspective. This narrows the sensible usefulness of those fashions in complicated real-world purposes with strict matter adherence, comparable to narrative era, content material creation, and coding duties. Overcoming this problem by enabling multi-token prediction would drastically enhance semantic continuity, accuracy, and coherence of the generated sequences of the present generative language fashions.
There have been numerous methods by way of which multi-token prediction has been addressed, every with completely different limitations. Fashions that goal to make predictions for a number of tokens by splitting embeddings or having a number of language heads are computationally intensive and infrequently don’t carry out properly. For Seq2Seq fashions in encoder-decoder units, whereas this enables for multi-token prediction, they fail to seize previous contexts into one single embedding; therefore, quite a lot of inefficiencies consequence. Whereas BERT and different masked language fashions can predict a number of tokens of a sequence which can be masked, they fail in left-to-right era, therefore proscribing their use in sequential textual content prediction. ProphetNet, alternatively, makes use of an n-gram prediction technique; nonetheless, this isn’t versatile throughout a variety of knowledge sorts. The fundamental drawbacks of the aforementioned strategies are scalability points, computational waste, and customarily unimpressive outcomes whereas producing high-quality predictions over long-context issues.
The researchers from EPFL introduce the Future Token Prediction mannequin, representing a brand new structure to create broader context-aware token embeddings. It will allow seamless multi-token predictions the place, in distinction with customary fashions, the embedding from the highest layers is utilized by a transformer encoder to offer “pseudo-sequences” cross-attended by a small transformer decoder for next-token predictions. On this means, the mannequin leverages such encoder-decoder functionality of the FTP for retaining context info from tokens of the earlier historical past to make smoother transitions and keep matter coherence throughout multi-token predictions. With extra widespread sequence context encoded inside its embeddings, FTP supplies stronger continuity for generated sequences and has grow to be the most effective approaches to content material era and different purposes that require long-form semantic coherence.

The FTP mannequin employs a modified GPT-2 structure that’s made up of a 12-layer encoder with a 3-layer decoder. Its encoder generates token embeddings which can be linearly projected to increased dimensionality right into a 12-dimensional pseudo-sequence that the decoder cross-attends over to make sense of sequence context. It shares embedding weights between the encoder and decoder; it’s skilled on OpenWebText information and makes use of the GPT-2 tokenizer. In the meantime, optimization is finished by AdamW, with a batch measurement of 500 and a studying price of 4e-4. There’s the gamma parameter set to 0.8 on this mannequin to progressively low cost the eye given to tokens far into the long run in order that fast predictions can stay extremely correct. This fashion, the FTP mannequin manages to maintain semantic coherence with out substantial computational overhead and thus finds an optimum trade-off between effectivity and efficiency.
These outcomes and analysis certainly present that the mannequin brings important enhancements in comparison with conventional GPTs on many key efficiency metrics: important reductions in perplexity, higher predictive accuracy, and enhanced stability for long-sequence duties. It additionally yields increased recall, precision, and F1 scores in BERT-based assessments of textual high quality, which might additional indicate improved semantic alignment towards precise textual content sequences. It additionally outperforms GPT fashions on textual content classification duties just like the IMDB and Amazon evaluations and all the time supplies higher validation loss with increased accuracy. Extra importantly, FTP follows the subject of the generated textual content extra coherently, supported by increased cosine similarity scores in long-sequence evaluations, additional establishing its prowess for coherent, contextually related content material era throughout extra assorted purposes.
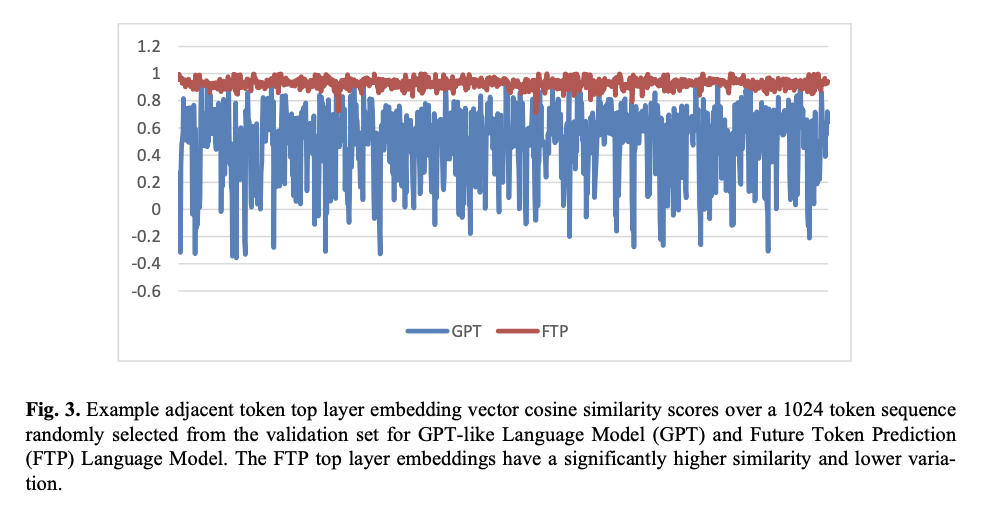
The FTP mannequin represents a paradigm shift in causal language modeling, one which develops essentially the most vital inefficiencies of the traditional single-token strategies into an embedding that helps wider and context-sensitive views for making multi-token predictions. By enhancing each the accuracy of prediction and semantic coherence, this distinction is underlined by improved scores throughout each perplexity and BERT-based metrics for a variety of duties. The pseudo-sequence cross-attention mechanism inside this mannequin enhances generative AI by pulling constant narrative move—an necessary requirement for prime worth in topic-coherent language modeling throughout purposes that require semantic integrity.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An In depth Assortment of Small Language Fashions (SLMs) for Intel PCs
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with information science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.