{kind=link}

Massive Language Fashions (LLMs) have emerged as highly effective instruments in pure language processing, but understanding their inner representations stays a major problem. Current breakthroughs utilizing sparse autoencoders have revealed interpretable “options” or ideas throughout the fashions’ activation area. Whereas these found characteristic level clouds are actually publicly accessible, comprehending their complicated structural group throughout totally different scales presents an important analysis downside. The evaluation of those buildings includes a number of challenges: figuring out geometric patterns on the atomic stage, understanding useful modularity on the intermediate scale, and analyzing the general distribution of options on the bigger scale. Conventional approaches have struggled to supply a complete understanding of how these totally different scales work together and contribute to the mannequin’s behaviour, making it important to develop new methodologies for analyzing these multi-scale buildings.
Earlier methodological makes an attempt to know LLM characteristic buildings have adopted a number of distinct approaches, every with its limitations. Sparse autoencoders (SAE) emerged as an unsupervised technique for locating interpretable options, initially revealing neighbourhood-based groupings of associated options by means of UMAP projections. Early phrase embedding strategies like GloVe and Word2vec found linear relationships between semantic ideas, demonstrating primary geometric patterns comparable to analogical relationships. Whereas these approaches supplied worthwhile insights, they had been restricted by their deal with single-scale evaluation. Meta-SAE strategies tried to decompose options into extra atomic parts, suggesting a hierarchical construction, however struggled to seize the complete complexity of multi-scale interactions. Perform vector evaluation in sequence fashions revealed linear representations of assorted ideas, from sport positions to numerical portions, however these strategies usually centered on particular domains quite than offering a complete understanding of the characteristic area’s geometric construction throughout totally different scales.
Researchers from the Massachusetts Institute of Know-how suggest a strong methodology to research geometric buildings in SAE characteristic areas by means of the idea of “crystal buildings” – patterns that replicate semantic relationships between ideas. This system extends past easy parallelogram relationships (like man:lady::king: queen) to incorporate trapezoid formations, which characterize single-function vector relationships comparable to country-to-capital mappings. Preliminary investigations revealed that these geometric patterns are sometimes obscured by “distractor options” – semantically irrelevant dimensions like phrase size that distort the anticipated geometric relationships. To handle this problem, the research introduces a refined methodology utilizing Linear Discriminant Evaluation (LDA) to mission the info onto a lower-dimensional subspace, successfully filtering out these distractor options. This method permits for clearer identification of significant geometric patterns by specializing in signal-to-noise eigenmodes, the place sign represents inter-cluster variation and noise represents intra-cluster variation.
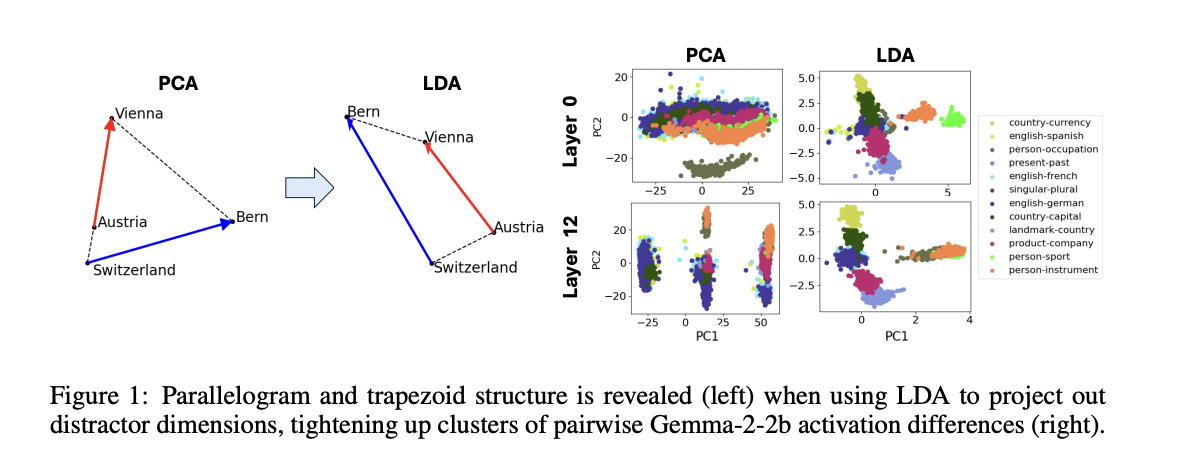

The methodology expands into analyzing larger-scale buildings by investigating useful modularity throughout the SAE characteristic area, just like specialised areas in organic brains. The method identifies useful “lobes” by means of a scientific means of analyzing characteristic co-occurrences in doc processing. Utilizing a layer 12 residual stream SAE with 16,000 options, the research processes paperwork from The Pile dataset, contemplating options as “firing” when their hidden activation exceeds 1 and recording co-occurrences inside 256-token blocks. The evaluation employs varied affinity metrics (easy matching coefficient, Jaccard similarity, Cube coefficient, overlap coefficient, and Phi coefficient) to measure characteristic relationships, adopted by spectral clustering. To validate the spatial modularity speculation, the analysis implements two quantitative approaches: evaluating mutual data between geometry-based and co-occurrence-based clustering outcomes and coaching logistic regression fashions to foretell useful lobes from geometric positions. This complete methodology goals to ascertain whether or not functionally associated options exhibit spatial clustering within the activation area.
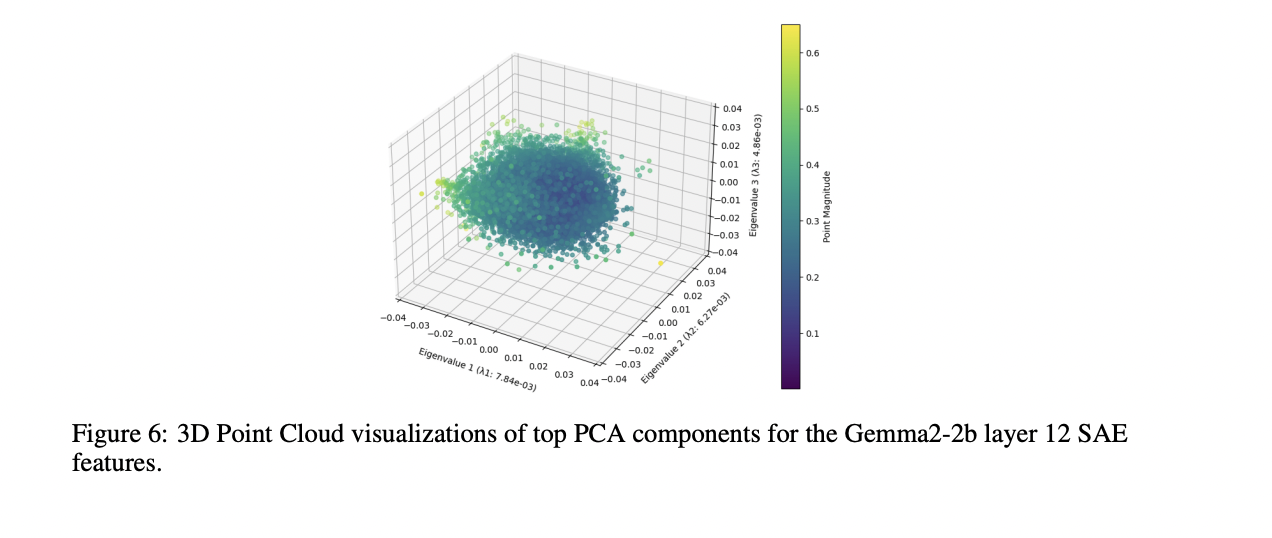
The big-scale “galaxy” construction evaluation of the SAE characteristic level cloud reveals distinct patterns that deviate from a easy isotropic Gaussian distribution. Analyzing the primary three principal parts demonstrates that the purpose cloud reveals uneven shapes, with various widths alongside totally different principal axes. This construction bears a resemblance to organic neural organizations, notably the human mind’s uneven formation. These findings counsel that the characteristic area maintains organized, non-random distributions even on the largest scale of study.
The multi-scale evaluation of SAE characteristic level clouds reveals three distinct ranges of structural group. On the atomic stage, geometric patterns emerge within the type of parallelograms and trapezoids representing semantic relationships, notably when distractor options are eliminated. The intermediate stage demonstrates useful modularity just like organic neural programs, with specialised areas for particular duties like arithmetic and coding. The galaxy-scale construction reveals non-isotropic distribution with a attribute energy regulation of eigenvalues, most pronounced within the center layers. These findings considerably advance the understanding of how language fashions arrange and characterize data throughout totally different scales.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An Intensive Assortment of Small Language Fashions (SLMs) for Intel PCs
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.