{kind=link}

With this weblog, I want to present one small agent built-in with `LangGraph` and Google Gemini for analysis functions. The target is to reveal one analysis agent (Paper-to-Voice Assistant) who plans to summarize the analysis paper. This instrument will use a imaginative and prescient mannequin to deduce the data. This methodology solely identifies the step and its sub-steps and tries to get the reply for these motion objects. Lastly, all of the solutions are transformed into conversations by which two folks will talk about the paper. You possibly can take into account this a mini NotebookLM of Google.
To elaborate additional, I’m utilizing a single uni-directed graph the place communication between steps occurs from high to backside. I’ve additionally used conditional node connections to course of repeated jobs.
- A course of to construct easy brokers with the assistance of Langgraph
- MultiModal Dialog with Google Gemini llm

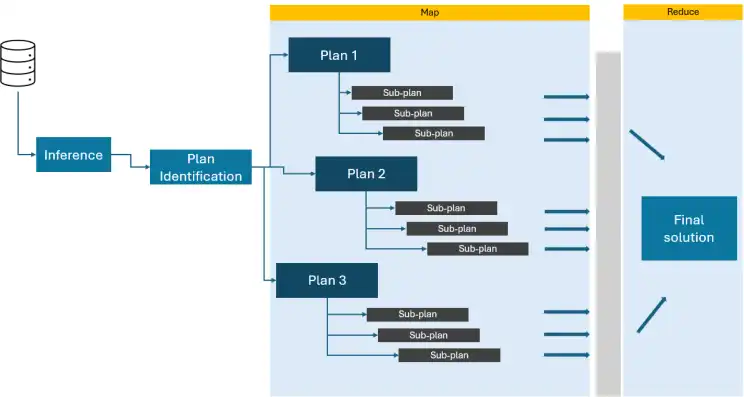
Paper-to-Voice Assistant: Map-reduce in Agentic AI
Think about an enormous downside so giant {that a} single particular person would take a number of days/months to unravel. Now, image a group of expert folks, every given a particular part of the duty to work on. They may begin by sorting the plans by goal or complexity, then progressively piecing collectively smaller sections. As soon as every solver has accomplished their part, they mix their options into the ultimate one.
That is primarily how map-reduce works in Agentic AI. The primary “downside” will get divided into sub-problem statements. The “solvers” are particular person LLMs, which map every sub-plan with totally different solvers. Every solver works on its assigned sub-problem, performing calculations or inferring data as wanted. Lastly, the outcomes from all “solvers” are mixed (decreased) to provide the ultimate output.
From Automation to Help: The Evolving Position of AI Brokers
After developments in generative AI, LLM brokers are fairly fashionable, and persons are profiting from their capabilities. Some argue that brokers can automate the method finish to finish. Nevertheless, I view them as productiveness enablers. They will help in problem-solving, designing workflow, and enabling people to give attention to important components. As an example, brokers can function automated provers exploring the area of mathematical proofs. They will provide new views and methods of considering past “human-generated” proofs.
One other latest instance is the AI-enabled Cursor Studio. The cursor is a managed atmosphere much like VS code that helps programming help.
Brokers are additionally changing into extra able to planning and taking motion, resembling the best way people motive, and most significantly, they will modify their methods. They’re shortly bettering of their means to research duties, develop plans to finish them and refine their method by repeated self-critique. Some strategies contain holding people within the loop, the place brokers search steerage from people at intervals after which proceed primarily based on these directions.

What isn’t included?
- I’ve not included any instruments like search or any customized operate to make it extra superior.
- No routing method or reverse connection is developed.
- No branching strategies are used for parallel processing or conditional job
- Related issues will be applied by loading pdf and parsing photographs and graphs.
- Enjoying with solely 3 photographs in a single immediate.
Python Libraries Used
- langchain-google-genai : To attach langchain with Google generative AI fashions
- python-dotenv: To load secrete keys or any atmosphere variables
- langgraph: To assemble the brokers
- pypdfium2 & pillow: To transform PDF into photographs
- pydub : to section the audio
- gradio_client : to name HF 🤗 mannequin
Paper-to-Voice Assistant: Sensible Implementation
Right here’s the implementation:
Load the Supporting Libraries
from dotenv import dotenv_values
from langchain_core.messages import HumanMessage
import os
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.graph import StateGraph, START, END,MessagesState
from langgraph.graph.message import add_messages
from langgraph.constants import Ship
import pypdfium2 as pdfium
import json
from PIL import Picture
import operator
from typing import Annotated, TypedDict # ,Non-compulsory, Checklist
from langchain_core.pydantic_v1 import BaseModel # ,AreaLoad Atmosphere Variables
config = dotenv_values("../.env")
os.environ["GOOGLE_API_KEY"] = config['GEMINI_API']At the moment, I’m utilizing a Multimodal method on this mission. To realize this, I load a PDF file and convert every web page into a picture. These photographs are then fed into the Gemini imaginative and prescient mannequin for conversational functions.
The next code demonstrates find out how to load a PDF file, convert every web page into a picture, and save these photographs to a listing.
pdf = pdfium.PdfDocument("./pdf_image/imaginative and prescient.pdf")
for i in vary(len(pdf)):
web page = pdf[i]
picture = web page.render(scale=4).to_pil()
picture.save(f"./pdf_image/vision_P{i:03d}.jpg")Let’s show the one web page for our reference.
image_path = "./pdf_image/vision_P000.jpg"
img = Picture.open(image_path)
imgOutput:

Google Vission Mannequin
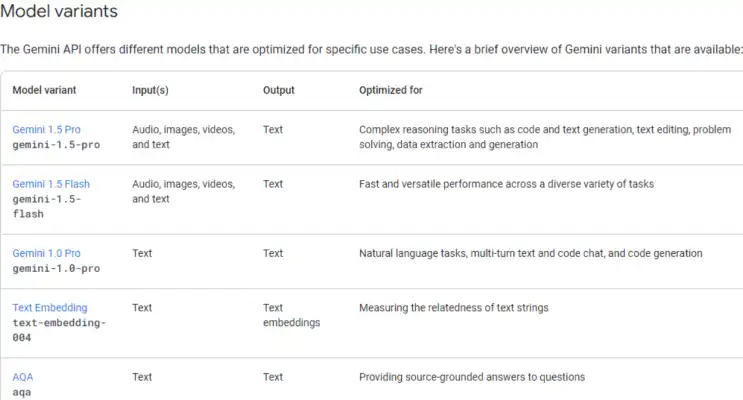
Connecting Gemini mannequin by API key. The next are the totally different variants accessible. One necessary factor to note is that we must always choose the mannequin that helps the info sort. Since I’m working with photographs within the dialog, I wanted to go for both the Gemini 1.5 Professional or Flash fashions, as these variants assist picture knowledge.
llm = ChatGoogleGenerativeAI(
mannequin="gemini-1.5-flash-001", # "gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
Let’s transfer ahead by constructing the schema to handle the output and switch data between nodes. Make the most of the add operator to merge all of the steps and sub-steps that the agent will create.
class State(TypedDict):
image_path: str # To retailer reference of all of the pages
steps: Annotated[list, operator.add] # Retailer all of the steps generated by the agent
substeps: Annotated[list, operator.add] # Retailer all of the sub steps generated by the agent for each step
options: Annotated[list, operator.add] # Retailer all of the options generated by the agent for every step
content material:str # retailer the content material of the paper
plan:str # retailer the processed plan
Dialog: Annotated[list, operator.add]The Schema to manage the output of step one.
class Job(BaseModel):
job: strSchema will retailer the output of every sub-step primarily based on the duties recognized within the earlier step.
class SubStep(BaseModel):
substep: strSchema to manage the output throughout conditional looping.
class StepState(TypedDict):
step: str
image_path: str
options: str
Dialog: strStep 1: Generate Duties
In our first step, we’ll move the pictures to the LLM and instruct it to establish all of the plans it intends to execute to know the analysis paper totally. I’ll present a number of pages directly, asking the mannequin to generate a mixed plan primarily based on all the pictures.
def generate_steps(state: State):
immediate="""
Take into account you're a analysis scientist in synthetic intelligence who's knowledgeable in understanding analysis papers.
You can be given a analysis paper and it's essential to establish all of the steps a researcher must carry out.
Determine every steps and their substeps.
"""
message = HumanMessage(content material=[{'type':'text','text':prompt},
*[{"type":'image_url','image_url':img} for img in state['image_path']]
]
)
response = llm.invoke([message])
return {"content material": [response.content],"image_path":state['image_path']}Step 2: Plan Parsing
On this step, we’ll take the plan recognized in step one and instruct the mannequin to transform it right into a structured format. I’ve outlined the schema and included that data with the immediate. It’s necessary to notice that exterior parsing instruments can be utilized to remodel the plan into a correct knowledge construction. To boost robustness, you may use “Instruments” to parse the info or create a extra rigorous schema as effectively.
def markdown_to_json(state: State):
immediate ="""
You're given a markdown content material and it's essential to parse this knowledge into json format. Comply with accurately key and worth
pairs for every bullet level.
Comply with following schema strictly.
schema:
[
{
"step": "description of step 1 ",
"substeps": [
{
"key": "title of sub step 1 of step 1",
"value": "description of sub step 1 of step 1"
},
{
"key": "title of sub step 2 of step 1",
"value": "description of sub step 2 of step 1"
}]},
{
"step": "description of step 2",
"substeps": [
{
"key": "title of sub step 1 of step 2",
"value": "description of sub step 1 of step 2"
},
{
"key": "title of sub step 2 of step 2",
"value": "description of sub step 2 of step 2"
}]}]'
Content material:
%s
"""% state['content']
str_response = llm.invoke([prompt])
return({'content material':str_response.content material,"image_path":state['image_path']})Step 3 Textual content To Json
Within the third step, we’ll take the plan recognized in 2nd step and convert it into JSON format. Please be aware that this methodology might not all the time work if LLM violates the schema construction.
def parse_json(state: State):
str_response_json = json.masses(state['content'][7:-3].strip())
output = []
for step in str_response_json:
substeps = []
for merchandise in step['substeps']:
for okay,v in merchandise.objects():
if okay=='worth':
substeps.append(v)
output.append({'step':step['step'],'substeps':substeps})
return({"plan":output})Step 4: Resolution For Every Step
The answer findings of each step will probably be taken care of by this step. It should take one plan and mix all of the sub-plans in a pair of Questions and Solutions in a single immediate. Moreover, LLM will establish the answer of each sub-step.
This step may even mix the a number of outputs into one with the assistance of the Annotator and “add” operator. For now, this step is working with honest high quality. Nevertheless, it may be improved through the use of branching and translating each sub-step into a correct reasoning immediate.
Primarily, each substep ought to get translated into a sequence of thought in order that LLM can put together an answer. One can use React as effectively.
def sovle_substeps(state: StepState):
print(state)
inp = state['step']
print('fixing sub steps')
qanda=" ".be a part of([f'n Question: {substep} n Answer:' for substep in inp['substeps']])
immediate=f""" You can be given instruction to research analysis papers. It's essential to perceive the
instruction and resolve all of the questions talked about within the listing.
Hold the pair of Query and its reply in your response. Your response needs to be subsequent to the key phrase "Reply"
Instruction:
{inp['step']}
Questions:
{qanda}
"""
message = HumanMessage(content material=[{'type':'text','text':prompt},
*[{"type":'image_url','image_url':img} for img in state['image_path']]
]
)
response = llm.invoke([message])
return {"steps":[inp['step']], 'options':[response.content]}Step 5: Conditional Loop
This step is important for managing the circulate of the dialog. It entails an iterative course of that maps out the generated plans (steps) and repeatedly passes data from one node to a different in a loop. The loop terminates as soon as all of the plans have been executed. At the moment, this step handles one-way communication between nodes, but when there’s a necessity for bi-directional communication, we would wish to contemplate implementing totally different branching strategies.
def continue_to_substeps(state: State):
steps = state['plan']
return [Send("sovle_substeps", {"step": s,'image_path':state['image_path']}) for s in steps]Step 6: Voice
After all of the solutions are generated, the next code will flip them right into a dialogue after which mix all the things right into a podcast that includes two folks discussing the paper. The next immediate is taken from right here.
SYSTEM_PROMPT = """
You're a world-class podcast producer tasked with remodeling the offered enter textual content into an attractive and informative podcast script. The enter could also be unstructured or messy, sourced from PDFs or net pages. Your purpose is to extract probably the most attention-grabbing and insightful content material for a compelling podcast dialogue.
# Steps to Comply with:
1. **Analyze the Enter:**
Rigorously look at the textual content, figuring out key matters, factors, and attention-grabbing information or anecdotes that
might drive an attractive podcast dialog. Disregard irrelevant data or formatting points.
2. **Brainstorm Concepts:**
Within the ``, creatively brainstorm methods to current the important thing factors engagingly. Take into account:
- Analogies, storytelling strategies, or hypothetical eventualities to make content material relatable
- Methods to make complicated matters accessible to a basic viewers
- Thought-provoking inquiries to discover throughout the podcast
- Artistic approaches to fill any gaps within the data
3. **Craft the Dialogue:**
Develop a pure, conversational circulate between the host (Jane) and the visitor speaker (the writer or an knowledgeable on the subject). Incorporate:
- The most effective concepts out of your brainstorming session
- Clear explanations of complicated matters
- An enticing and energetic tone to captivate listeners
- A stability of knowledge and leisure
Guidelines for the dialogue:
- The host (Jane) all the time initiates the dialog and interviews the visitor
- Embody considerate questions from the host to information the dialogue
- Incorporate pure speech patterns, together with occasional verbal fillers (e.g., "um," "effectively," "")
- Enable for pure interruptions and back-and-forth between host and visitor
- Make sure the visitor's responses are substantiated by the enter textual content, avoiding unsupported claims
- Preserve a PG-rated dialog acceptable for all audiences
- Keep away from any advertising and marketing or self-promotional content material from the visitor
- The host concludes the dialog
4. **Summarize Key Insights:**
Naturally weave a abstract of key factors into the closing a part of the dialogue. This could really feel like an off-the-cuff dialog somewhat than a proper recap, reinforcing the primary takeaways earlier than signing off.
5. **Preserve Authenticity:**
All through the script, try for authenticity within the dialog. Embody:
- Moments of real curiosity or shock from the host
- Situations the place the visitor may briefly wrestle to articulate a posh thought
- Gentle-hearted moments or humor when acceptable
- Temporary private anecdotes or examples that relate to the subject (throughout the bounds of the enter textual content)
6. **Take into account Pacing and Construction:**
Make sure the dialogue has a pure ebb and circulate:
- Begin with a powerful hook to seize the listener's consideration
- Regularly construct complexity because the dialog progresses
- Embody transient "breather" moments for listeners to soak up complicated data
- Finish on a excessive be aware, maybe with a thought-provoking query or a call-to-action for listeners
""" def generate_dialog(state):
textual content = state['text']
tone = state['tone']
size = state['length']
language = state['language']
modified_system_prompt = SYSTEM_PROMPT
modified_system_prompt += f"nPLEASE paraphrase the next TEXT in dialog format."
if tone:
modified_system_prompt += f"nnTONE: The tone of the podcast needs to be {tone}."
if size:
length_instructions = {
"Brief (1-2 min)": "Hold the podcast transient, round 1-2 minutes lengthy.",
"Medium (3-5 min)": "Purpose for a average size, about 3-5 minutes.",
}
modified_system_prompt += f"nnLENGTH: {length_instructions[length]}"
if language:
modified_system_prompt += (
f"nnOUTPUT LANGUAGE : The the podcast needs to be {language}."
)
messages = modified_system_prompt + 'nTEXT: '+ textual content
response = llm.invoke([messages])
return {"Step":[state['step']],"Discovering":[state['text']], 'Dialog':[response.content]} def continue_to_substeps_voice(state: State):
print('voice substeps')
options = state['solutions']
steps = state['steps']
tone="Formal" # ["Fun", "Formal"]
return [Send("generate_dialog", {"step":st,"text": s,'tone':tone,'length':"Short (1-2 min)",'language':"EN"}) for st,s in zip(steps,solutions)]Step 7: Graph Building
Now it’s time to assemble all of the steps we’ve outlined:
- Initialize the Graph: Begin by initializing the graph and defining all the required nodes.
- Outline and Join Nodes: Join the nodes utilizing edges, making certain the circulate of knowledge from one node to a different.
- Introduce the Loop: Implement the loop as described in step 5, permitting for iterative processing of the plans.
- Terminate the Course of: Lastly, use the END methodology of LangGraph to shut and terminate the method correctly.
It’s time to show the community for higher understanding.
graph = StateGraph(State)
graph.add_node("generate_steps", generate_steps)
graph.add_node("markdown_to_json", markdown_to_json)
graph.add_node("parse_json", parse_json)
graph.add_node("sovle_substeps", sovle_substeps)
graph.add_node("generate_dialog", generate_dialog)
graph.add_edge(START, "generate_steps")
graph.add_edge("generate_steps", "markdown_to_json")
graph.add_edge("markdown_to_json", "parse_json")
graph.add_conditional_edges("parse_json", continue_to_substeps, ["sovle_substeps"])
graph.add_conditional_edges("sovle_substeps", continue_to_substeps_voice, ["generate_dialog"])
graph.add_edge("generate_dialog", END)
app = graph.compile()
It’s time to show the community for higher understanding.
from IPython.show import Picture, show
strive:
show(Picture(app.get_graph().draw_mermaid_png()))
besides Exception:
print('There appears error')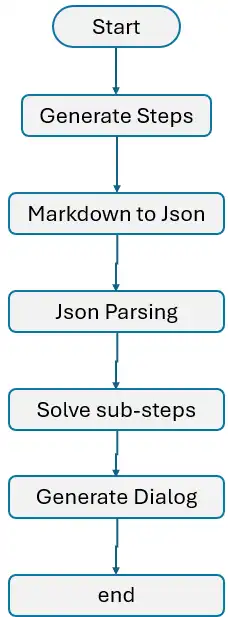
Let’s start the method and consider how the present framework operates. For now, I’m testing with solely three photographs, although this may be prolonged to a number of photographs. The code will take photographs as enter and move this knowledge to the graph’s entry level. Subsequently, every step will take the enter from the earlier step and move the output to the following step till the method is accomplished.
output = []
for s in app.stream({"image_path": [f"./pdf_image/vision_P{i:03d}.jpg" for i in range(6)]}):
output.append(s)
with open('./knowledge/output.json','w') as f:
json.dump(output,f)Output:
with open('./knowledge/output.json','r') as f:
output1 = json.load(f)print(output1[10]['generate_dialog']['Dialog'][0])Output:
I’m utilizing the next code to stream the outcomes sequentially, the place every plan and sub-plan will probably be mapped to a corresponding response.
import sys
import time
def printify(tx,stream=False):
if stream:
for char in tx:
sys.stdout.write(char)
sys.stdout.flush()
time.sleep(0.05)
else:
print(tx)matters =[]
substeps=[]
for idx, plan in enumerate(output1[2]['parse_json']['plan']):
matters.append(plan['step'])
substeps.append(plan['substeps'])Let’s separate the solutions of each sub-step
text_planner = {}
stream = False
for matter,substep,responses in zip(matters,substeps,output1[3:10]):
response = responses['sovle_substeps']
response_topic = response['steps']
if matter in response_topic:
reply = response['solutions'][0].strip().break up('Reply:')
reply =[ans.strip() for ans in answer if len(ans.strip())>0]
for q,a in zip(substep,reply):
printify(f'Sub-Step : {q}n',stream=stream)
printify(f'Motion : {a}n',stream=stream)
text_planner[topic]={'reply':listing(zip(substep,reply))}The output of Sub-steps and their Motion

The final node within the graph converts all of the solutions into dialog. Let’s retailer them in separate variables in order that we are able to convert them into voice.
stream = False
dialog_planner ={}
for matter,responses in zip(matters,output1[10:17]):
dialog = responses['generate_dialog']['Dialog'][0]
dialog = dialog.strip().break up('## Podcast Script')[-1].strip()
dialog = dialog.change('[Guest Name]','Robin').change('**Visitor:**','**Robin:**')
printify(f'Dialog: : {dialog}n',stream=stream)
dialog_planner[topic]=dialogDialog Output
Dialog to Voice
from pydantic import BaseModel, Area
from typing import Checklist, Literal, Tuple, Non-compulsory
import glob
import os
import time
from pathlib import Path
from tempfile import NamedTemporaryFile
from scipy.io.wavfile import write as write_wav
import requests
from pydub import AudioSegment
from gradio_client import Consumer
import json
from tqdm.pocket book import tqdm
import sys
from time import sleepwith open('./knowledge/dialog_planner.json','r') as f:
dialog_planner1 = json.load(f)Now, let’s convert these textual content dialogs into voice
1. Textual content To Speech
For now, I’m accessing the tts mannequin from the HF endpoint, and for that, I must set the URL and API key.
HF_API_URL = config['HF_API_URL']
HF_API_KEY = config['HF_API_KEY']
headers = {"Authorization": HF_API_KEY}2. Gradio Consumer
I’m utilizing the Gradio shopper to name the mannequin and set the next path so the Gradio shopper can save the audio knowledge within the specified listing. If no path is outlined, the shopper will retailer the audio in a short lived listing.
os.environ['GRADIO_TEMP_DIR'] = "path_to_data_dir"
hf_client = Consumer("mrfakename/MeloTTS")
hf_client.output_dir= "path_to_data_dir"
def get_text_to_voice(textual content,velocity,accent,language):
file_path = hf_client.predict(
textual content=textual content,
language=language,
speaker=accent,
velocity=velocity,
api_name="/synthesize",
)
return(file_path)3. Voice Accent
To generate the dialog for the podcast, I’m assigning two totally different accents: one for the host and one other for the visitor.
def generate_podcast_audio(textual content: str, language: str) -> str:
if "**Jane:**" in textual content:
textual content = textual content.change("**Jane:**",'').strip()
accent = "EN-US"
velocity = 0.9
elif "**Robin:**" in textual content: # host
textual content = textual content.change("**Robin:**",'').strip()
accent = "EN_INDIA"
velocity = 1
else:
return 'Empty Textual content'
for try in vary(3):
strive:
file_path = get_text_to_voice(textual content,velocity,accent,language)
return file_path
besides Exception as e:
if try == 2: # Final try
elevate # Re-raise the final exception if all makes an attempt fail
time.sleep(1) # Await 1 second earlier than retrying4. Retailer voice in mp3 file
Every audio clip will probably be below 2 minutes in size. This part will generate audio for every quick dialog, and the recordsdata will probably be saved within the specified listing.
def store_voice(topic_dialog):
audio_path = []
merchandise =0
for matter,dialog in tqdm(topic_dialog.objects()):
dialog_speaker = dialog.break up("n")
for speaker in tqdm(dialog_speaker):
one_dialog = speaker.strip()
language_for_tts = "EN"
if len(one_dialog)>0:
audio_file_path = generate_podcast_audio(
one_dialog, language_for_tts
)
audio_path.append(audio_file_path)
# proceed
sleep(5)
break
return(audio_path)audio_paths = store_voice(topic_dialog=dialog_planner1)5. Mixed Audio
Lastly, let’s mix all of the quick audio clips to create an extended dialog.
def consolidate_voice(audio_paths,voice_dir):
audio_segments =[]
voice_path = [paths for paths in audio_paths if paths!='Empty Text']
audio_segment = AudioSegment.from_file(voice_dir+"/light-guitar.wav")
audio_segments.append(audio_segment)
for audio_file_path in tqdm(voice_path):
audio_segment = AudioSegment.from_file(audio_file_path)
audio_segments.append(audio_segment)
audio_segment = AudioSegment.from_file(voice_dir+"/ambient-guitar.wav")
audio_segments.append(audio_segment)
combined_audio = sum(audio_segments)
temporary_directory = voice_dir+"/tmp/"
os.makedirs(temporary_directory, exist_ok=True)
temporary_file = NamedTemporaryFile(
dir=temporary_directory,
delete=False,
suffix=".mp3",
)
combined_audio.export(temporary_file.title, format="mp3")consolidate_voice(audio_paths=audio_paths,voice_dir="./knowledge")Additionally, to know the Agent AI higher, discover: The Agentic AI Pioneer Program.
Conclusion
General, this mission is meant purely for demonstration functions and would require vital effort and course of adjustments to create a production-ready agent. It might function a proof of idea (POC) with minimal effort. On this demonstration, I’ve not accounted for components like time complexity, price, and accuracy, that are important issues in a manufacturing atmosphere. With that stated, I’ll conclude right here. Thanks for studying. For extra technical particulars, please refer GitHub.
Steadily Requested Questions
Ans. The Paper-to-Voice Assistant is designed to simplify the method of summarizing analysis papers by changing the extracted data right into a conversational format, enabling simple understanding and accessibility.
Ans. The assistant makes use of a map-reduce method, the place it breaks down the analysis paper into steps and sub-steps, processes the data utilizing LangGraph and Google Gemini LLMs, after which combines the outcomes right into a coherent dialogue.
Ans. The mission makes use of LangGraph, Google Gemini generative AI fashions, multimodal processing (imaginative and prescient and textual content), and text-to-speech conversion with the assistance of Python libraries like pypdfium2, pillow, pydub, and gradio_client.
Ans. Sure, the agent can analyze PDFs containing photographs by changing every web page into photographs and feeding them into the imaginative and prescient mannequin, permitting it to extract visible and textual data.
Ans. No, this mission is a proof of idea (POC) that demonstrates the workflow. Additional optimization, dealing with of time complexity, price, and accuracy changes are wanted to make it production-ready.