{kind=link}

One of the essential challenges of LLMs is the right way to align these fashions with human values and preferences, particularly in generated texts. Most generated textual content outputs by fashions are inaccurate, biased, or doubtlessly dangerous—for instance, hallucinations. This misalignment limits the potential utilization of LLMs in real-world functions throughout domains comparable to schooling, well being, and buyer help. That is additional compounded by the truth that the bias accrues in LLMs; iterative coaching processes are sure to make alignment issues worse, and subsequently it’s not clear whether or not the output produced will probably be trusted. That is certainly a really severe problem for the bigger and simpler scaling of LLM modalities utilized to real-world functions.
Present options to alignment contain strategies comparable to RLHF and direct choice optimization (DPO). RLHF trains a reward mannequin that rewards the LLM by way of reinforcement studying based mostly on human suggestions, whereas DPO optimizes the LLM immediately with annotated choice pairs and doesn’t require a separate mannequin for rewards. Each approaches rely closely on large quantities of human-labeled information, which is difficult to scale. Self-rewarding language fashions attempt to scale back this dependency by robotically producing choice information with out human interference. In SRLMs, a single mannequin is often performing each as a coverage mannequin—which generates responses—and as a reward mannequin that ranks these responses. Whereas this has met with some success, its main downside is that such a course of inherently leads to bias within the rewards iteration. The extra a mannequin has been extensively skilled on its self-created choice information on this method, the extra biased the reward system is, and this reduces the reliability of choice information and degrades the general efficiency in alignment.
In gentle of those deficiencies, researchers from the College of North Carolina, Nanyang Technological College, the Nationwide College of Singapore, and Microsoft launched CREAM, which stands for Consistency Regularized Self-Rewarding Language Fashions. This method alleviates bias amplification points in self-rewarding fashions by incorporating a regularization time period on the consistency of rewards throughout generations throughout coaching. The instinct is to herald consistency regularizers that consider the rewards produced by the mannequin throughout consecutive iterations and use this consistency as steering for the coaching course of. By contrasting the rating of responses from the present iteration with these from the earlier iteration, CREAM finds and focuses on dependable choice information, hindering the mannequin’s overlearning tendency from noisy or unreliable labels. This novel regularization mechanism reduces the bias and additional permits the mannequin to study extra effectively and successfully from its self-generated choice information. It is a huge enchancment in comparison with present self-rewarding strategies.
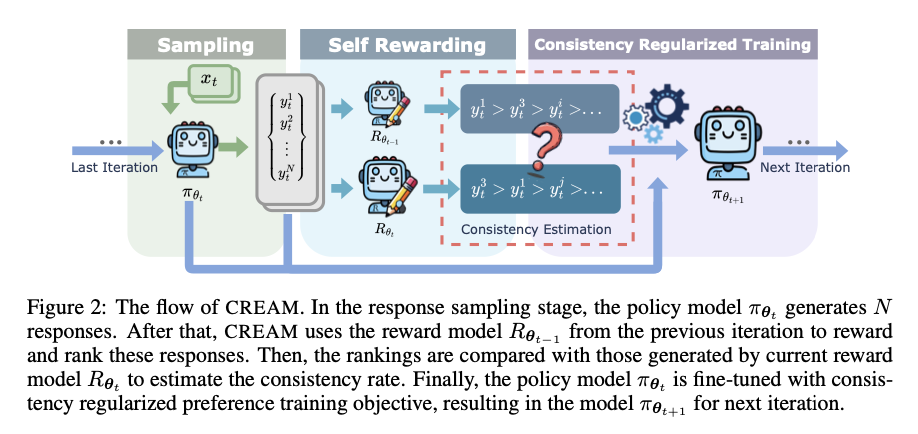
CREAM operates inside a generalized iterative choice fine-tuning framework relevant to each self-rewarding and RLHF strategies. The consistency regularization works by placing into comparability the rating of responses produced by the mannequin throughout consecutive iterations. Extra exactly, the consistency between rankings coming from the present and former iterations is measured by way of Kendall’s Tau coefficient. This consistency rating is then inducted into the loss operate as a regularization time period, which inspires the mannequin to rely extra on choice information that has excessive consistency throughout iterations. Moreover, CREAM fine-tunes a lot smaller LLMs, comparable to LLaMA-7B, utilizing datasets which might be extensively accessible, comparable to ARC-Straightforward/Problem, OpenBookQA, SIQA, and GSM8K. Iteratively, the strategy strengthens this through the use of a weighting mechanism for choice information based mostly on its consistency in reaching superior alignment with out necessitating large-scale human-labeled datasets.

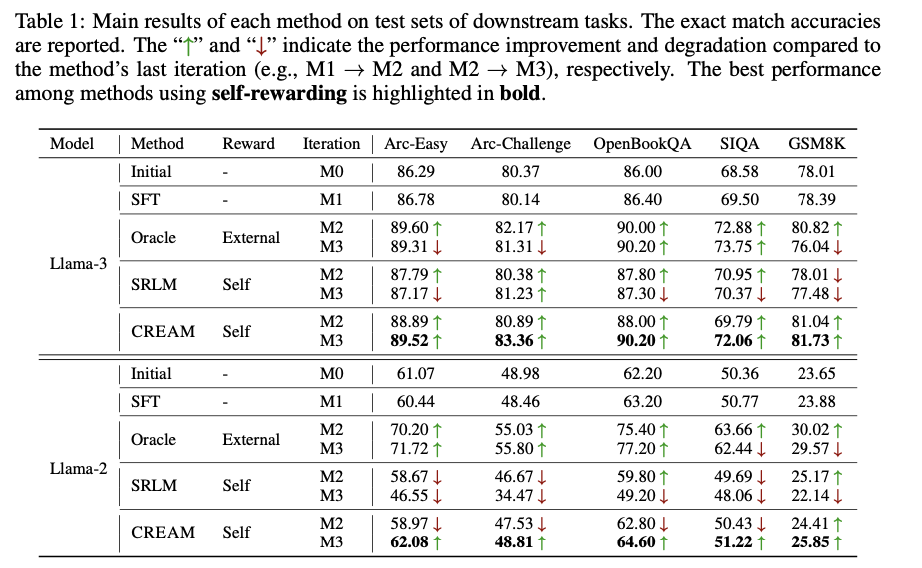
CREAM outperforms the baseline in lots of downstream duties when it comes to alignment and de-biasing of self-rewarding fashions. The notable accuracy positive aspects utilizing the strategy embody a rise from 86.78% to 89.52% in ARC-Straightforward and from 69.50% to 72.06% in SIQA. These constant enhancements over iterations present the ability of the consistency regularization mechanism at work. Whereas normal strategies of self-rewarding are inclined to have decrease general consistency of reward and alignment, CREAM outperforms current fashions, even compared with methods utilizing high-quality exterior reward fashions. This additionally maintained the efficiency enchancment with out utilizing any exterior assist, which exhibits the robustness of the mannequin in producing dependable choice information. In addition to, this mannequin retains bettering when it comes to accuracy and consistency in reward metrics, actually reflecting the significance of regularization in mitigating reward bias and bettering effectivity in self-rewarding. These outcomes additional set up CREAM as a robust answer to the alignment drawback by offering a scalable and efficient methodology for optimizing giant language fashions.
In conclusion, CREAM provides a novel answer towards the problem of rewarding bias in self-rewarding language fashions by introducing a consistency regularization mechanism. By paying extra consideration to reliable and constant information of choice, CREAM realizes an immense enchancment within the alignment of efficiency, particularly for somewhat small fashions like LLaMA-7B. Whereas this occludes longer-term reliance on human-annotated information, this methodology represents an vital enhancement towards scalability and effectivity in choice studying. This thus locations it as a really useful contribution to the continued growth of LLMs towards real-world functions. Empirical outcomes strongly validate that CREAM certainly outperforms current strategies and will have a possible influence on bettering alignment and reliability in LLMs.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Overlook to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Nice-Tuned Fashions: Predibase Inference Engine (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.