{kind=link}


Introduction
Massive Language Fashions (LLMs), regardless of how superior or highly effective, basically function as next-token predictors. One well-known limitation of those fashions is their tendency to hallucinate, producing info that will sound believable however is factually incorrect. On this weblog, we’ll –
- dive into the idea of hallucinations,
- discover the various kinds of hallucinations that may happen,
- perceive why they come up within the first place,
- talk about how you can detect and assess when a mannequin is hallucinating, and
- present some sensible methods to mitigate these points.
What are LLM Hallucinations?
Hallucinations consult with situations the place a mannequin generates content material that’s incorrect and isn’t logically aligning with the supplied enter/context or underlying knowledge. For instance –
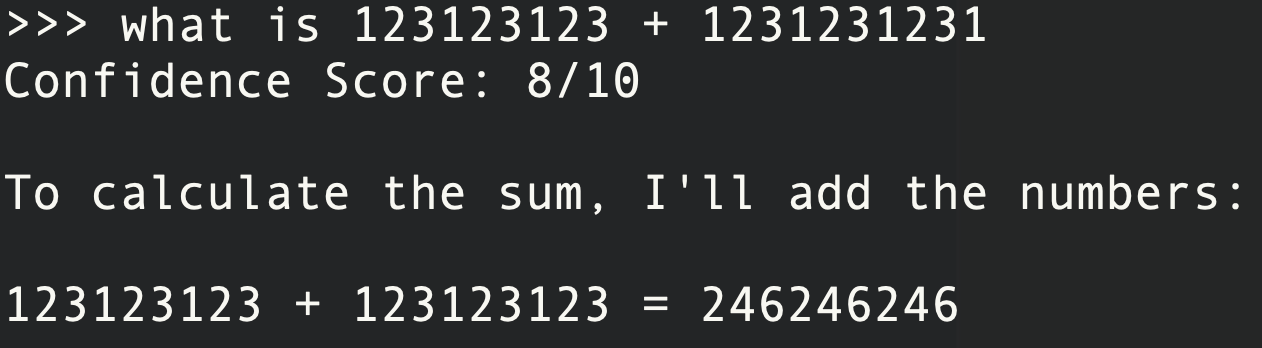
These hallucinations are sometimes categorized based mostly on their causes or manifestations. Listed below are widespread taxonomies and a dialogue of classes with examples in every taxonomy –
Varieties of Hallucinations
Intrinsic Hallucinations:
These happen when it’s doable to determine the mannequin’s hallucinations solely by evaluating the enter with the output. No exterior info is required to identify the errors. Instance –
- Producing info in a doc extraction job that doesn’t exist within the unique doc.
- Mechanically agreeing with customers’ incorrect or dangerous opinions, even when they’re factually mistaken or malicious.
Extrinsic Hallucinations:
These occur when exterior info is required to guage whether or not the mannequin is hallucinating, because the errors aren’t apparent based mostly solely on the enter and output. These are often more durable to detect with out area information
Modes of Hallucinations
Factual Hallucinations:
These happen when the mannequin generates incorrect factual info, equivalent to inaccurate historic occasions, false statistics, or mistaken names. Primarily, the LLM is fabricating information, a.okay.a. mendacity.
A well known instance is the notorious Bard incident –

Listed below are some extra examples of factual hallucinations –
- Mathematical errors and miscalculations.
- Fabricating citations, case research, or analysis references out of nowhere.
- Complicated entities throughout totally different cultures, resulting in “cultural hallucinations.”
- Offering incorrect directions in response to how-to queries.
- Failing to construction advanced, multi-step reasoning duties correctly, resulting in fragmented or illogical conclusions.
- Misinterpreting relationships between totally different entities.
Contextual Hallucinations:
These come up when the mannequin provides irrelevant particulars or misinterprets the context of a immediate. Whereas much less dangerous than factual hallucinations, these responses are nonetheless unhelpful or deceptive to customers.
Listed below are some examples that fall below this class –
- When requested about engine restore, the mannequin unnecessarily delves into the historical past of vehicles.
- Offering lengthy, irrelevant code snippets or background info when the person requests a easy resolution.
- Providing unrelated citations, metaphors, or analogies that don’t match the context.
- Being overly cautious and refusing to reply a standard immediate because of misinterpreting it as dangerous (a type of censorship-based hallucination).
- Repetitive outputs that unnecessarily lengthen the response.
- Displaying biases, notably in politically or morally delicate matters.
Omission-Primarily based Hallucinations:
These happen when the mannequin leaves out essential info, resulting in incomplete or deceptive solutions. This may be notably harmful, as customers could also be left with false confidence or inadequate information. It typically forces customers to rephrase or refine their prompts to get an entire response.
Examples:
- Failing to offer counterarguments when producing argumentative or opinion-based content material.
- Neglecting to say unintended effects when discussing the makes use of of a medicine.
- Omitting drawbacks or limitations when summarizing analysis experiments.
- Skewing protection of historic or information occasions by presenting just one facet of the argument.
Within the subsequent part we’ll talk about why LLMs hallucinate to start with.
Causes for Hallucinations
Dangerous Coaching Information
Like talked about firstly of the article, LLMs have principally one job – given the present sequence of phrases, predict the following phrase. So it ought to come as no shock that if we educate the LLM on dangerous sequences it should carry out badly.
The standard of the coaching knowledge performs a essential function in how properly an LLM performs. LLMs are sometimes skilled on huge datasets scraped from the net, which incorporates each verified and unverified sources. When a good portion of the coaching knowledge consists of unreliable or false info, the mannequin can reproduce this misinformation in its outputs, resulting in hallucinations.
Examples of poor coaching knowledge embrace:
- Outdated or inaccurate info.
- Information that’s overly particular to a selected context and never generalizable.
- Information with important gaps, resulting in fashions making inferences that could be false.
Bias in Coaching Information
Fashions can hallucinate because of inherent biases within the knowledge they had been skilled on. If the coaching knowledge over-represents sure viewpoints, cultures, or views, the mannequin may generate biased or incorrect responses in an try to align with the skewed knowledge.
Dangerous Coaching Schemes
The method taken throughout coaching, together with optimization methods and parameter tuning, can straight affect hallucination charges. Poor coaching methods can introduce or exacerbate hallucinations, even when the coaching knowledge itself is of excellent high quality.
- Excessive Temperatures Throughout Coaching – Coaching fashions with larger temperatures encourages the mannequin to generate extra numerous outputs. Whereas this will increase creativity and selection, it additionally will increase the danger of producing extremely inaccurate or nonsensical responses.
- Extreme on Trainer Forcing – Trainer forcing is a technique the place the proper reply is supplied as enter at every time step throughout coaching. Over-reliance on this system can result in hallucinations, because the mannequin turns into overly reliant on excellent situations throughout coaching and fails to generalize properly to real-world eventualities the place such steering is absent.
- Overfitting on Coaching Information – Overfitting happens when the mannequin learns to memorize the coaching knowledge slightly than generalize from it. This results in hallucinations, particularly when the mannequin is confronted with unfamiliar knowledge or questions outdoors its coaching set. The mannequin might “hallucinate” by confidently producing responses based mostly on irrelevant or incomplete knowledge patterns.
- Lack of Ample Tremendous-Tuning – If a mannequin just isn’t fine-tuned for particular use circumstances or domains, it should seemingly hallucinate when queried with domain-specific questions. For instance, a general-purpose mannequin might wrestle when requested extremely specialised medical or authorized questions with out extra coaching in these areas.
Dangerous Prompting
The standard of the immediate supplied to an LLM can considerably have an effect on its efficiency. Poorly structured or ambiguous prompts can lead the mannequin to generate responses which are irrelevant or incorrect. Examples of dangerous prompts embrace:
- Obscure or unclear prompts: Asking broad or ambiguous questions equivalent to, “Inform me all the pieces about physics,” could cause the mannequin to “hallucinate” by producing (by the way) pointless (to you) info.
- Below-specified prompts: Failing to offer sufficient context, equivalent to asking, “How does it work?” with out specifying what “it” refers to, can lead to hallucinated responses that attempt to fill within the gaps inaccurately.
- Compound questions: Asking multi-part or advanced questions in a single immediate can confuse the mannequin, inflicting it to generate unrelated or partially incorrect solutions.
Utilizing Contextually Inaccurate LLMs
The underlying structure or pre-training knowledge of the LLM will also be a supply of hallucinations. Not all LLMs are constructed to deal with particular area information successfully. As an illustration, if an LLM is skilled on normal knowledge from sources just like the web however is then requested domain-specific questions in fields like regulation, drugs, or finance, it could hallucinate because of a scarcity of related information.
In conclusion, hallucinations in LLMs are sometimes the results of a mix of things associated to knowledge high quality, coaching methodologies, immediate formulation, and the capabilities of the mannequin itself. By enhancing coaching schemes, curating high-quality coaching knowledge, and utilizing exact prompts, many of those points will be mitigated.
inform in case your LLM is Hallucinating?
Human within the Loop
When the quantity of knowledge to guage is restricted or manageable, it is doable to manually evaluation the responses generated by the LLM and assess whether or not it’s hallucinating or offering incorrect info. In principle, this hands-on method is among the most dependable methods to guage an LLM’s efficiency. Nevertheless, this methodology is constrained by two important components: the time required to completely look at the information and the experience of the individual performing the analysis.
Evaluating LLMs Utilizing Normal Benchmarks
In circumstances the place the information is comparatively easy and any hallucinations are prone to be intrinsic/restricted to the query+reply context, a number of metrics can be utilized to check the output with the specified enter, guaranteeing the LLM isn’t producing surprising or irrelevant info.
Fundamental Scoring Metrics: Metrics like ROUGE, BLEU, and METEOR function helpful beginning factors for comparability, though they’re typically not complete sufficient on their very own.
PARENT-T: A metric designed to account for the alignment between output and enter in additional structured duties.
Data F1: Measures the factual consistency of the LLM’s output in opposition to identified info.
Bag of Vectors Sentence Similarity: A extra subtle metric for evaluating the semantic similarity of enter and output.
Whereas the methodology is simple and computationally low cost, there are related drawbacks –
Proxy for Mannequin Efficiency: These benchmarks function proxies for assessing an LLM’s capabilities, however there isn’t any assure they are going to precisely mirror efficiency in your particular knowledge.
Dataset Limitations: Benchmarks typically prioritize particular forms of datasets, making them much less adaptable to different or advanced knowledge eventualities.
Information Leakage: Provided that LLMs are skilled on huge quantities of knowledge sourced from the web, there is a risk that some benchmarks might already be current within the coaching knowledge, affecting the analysis’s objectivity.
Nonetheless, utilizing normal statistical methods presents a helpful however imperfect method to evaluating LLMs, notably for extra specialised or distinctive datasets.
Mannequin-Primarily based Metrics
For extra advanced and nuanced evaluations, model-based methods contain auxiliary fashions or strategies to evaluate syntactic, semantic, and contextual variations in LLM outputs. Whereas immensely helpful, these strategies include inherent challenges, particularly regarding computational value and reliance on the correctness of the fashions used for analysis. Nonetheless, let’s talk about among the well-known methods to make use of LLMs for assessing LLMs
Self-Analysis:
LLMs will be prompted to evaluate their very own confidence within the solutions they generate. As an illustration, you may instruct an LLM to:
“Present a confidence rating between 0 and 1 for each reply, the place 1 signifies excessive confidence in its accuracy.”
Nevertheless, this method has important flaws, because the LLM will not be conscious when it’s hallucinating, rendering the boldness scores unreliable.
Producing A number of Solutions:
One other quite common method is to generate a number of solutions to the identical (or barely different) query and examine for consistency. Sentence encoders adopted by cosine similarity can be utilized to measure how related the solutions are. This methodology is especially efficient in eventualities involving mathematical reasoning, however for extra generic questions, if the LLM has a bias, all solutions may very well be constantly incorrect. This introduces a key disadvantage—constant but incorrect solutions do not essentially sign high quality.
Quantifying Output Relations:
Data extraction metrics assist determine whether or not the relationships between enter, output, and floor fact maintain up below scrutiny. This includes utilizing an exterior LLM to create and examine relational buildings from the enter and output. For instance:
Enter: What's the capital of France?
Output: Toulouse is the capital of France.
Floor Fact: Paris is the capital of France.
Floor Fact Relation: (France, Capital, Paris)
Output Relation: (Toulouse, Capital, France)
Match: False
This method permits for extra structured verification of outputs however relies upon closely on the mannequin’s capacity to appropriately determine and match relationships.
Pure Language Entailment (NLE):
NLE includes evaluating the logical relationship between a premise and a speculation to find out whether or not they’re in alignment (entailment), contradict each other (contradiction), or are impartial. An exterior mannequin evaluates whether or not the generated output aligns with the enter. For instance:
Premise: The affected person was identified with diabetes and prescribed insulin remedy.
LLM Era 1:
Speculation: The affected person requires remedy to handle blood sugar ranges.
Evaluator Output: Entailment.
LLM Era 2:
Speculation: The affected person doesn't want any remedy for his or her situation.
Evaluator Output: Contradiction.
LLM Era 3:
Speculation: The affected person might must make way of life modifications.
Evaluator Output: Impartial.
This methodology permits one to evaluate whether or not the LLM’s generated outputs are logically according to the enter. Nevertheless, it could actually wrestle with extra summary or long-form duties the place entailment will not be as easy.
Incorporating model-based metrics equivalent to self-evaluation, a number of reply era, and relational consistency presents a extra nuanced method, however every has its personal challenges, notably when it comes to reliability and context applicability.
Value can also be an necessary think about these courses of evaluations since one has to make a number of LLM calls on the identical query making the entire pipeline computationally and monetarily costly. Let’s talk about one other class of evaluations that tries to mitigate this value, by acquiring auxiliary info straight from the producing LLM itself.
Entropy-Primarily based Metrics for Confidence Estimation in LLMs
As deep studying fashions inherently present confidence measures within the type of token possibilities (logits), these possibilities will be leveraged to gauge the mannequin’s confidence in varied methods. Listed below are a number of approaches to utilizing token-level possibilities for evaluating an LLM’s correctness and detecting potential hallucinations.
Utilizing Token Chances for Confidence:
An easy methodology includes aggregating token possibilities as a proxy for the mannequin’s total confidence:
- Imply, max, or min of token possibilities: These values can function easy confidence scores, indicating how assured the LLM is in its prediction based mostly on the distribution of token possibilities. As an illustration, a low minimal chance throughout tokens might recommend uncertainty or hallucination in components of the output.
Asking an LLM a Sure/No Query:
After producing a solution, one other easy method is to ask the LLM itself (or one other mannequin) to guage the correctness of its response. For instance:
Methodology:
- Present the mannequin with the unique query and its generated reply.
- Ask a follow-up query, “Is that this reply right? Sure or No.”
- Analyze the logits for the “Sure” and “No” tokens and compute the chance that the mannequin believes its reply is right.
The chance of correctness is then calculated as:
Instance:
- Q: “What’s the capital of France?”
- A: “Paris” → P(Appropriate) = 78%
- A: “Berlin” → P(Appropriate) = 58%
- A: “Gandalf” → P(Appropriate) = 2%
A low P(Appropriate) worth would point out that the LLM is probably going hallucinating.
Coaching a Separate Classifier for Correctness:
You may prepare a binary classifier particularly to find out whether or not a generated response is right or incorrect. The classifier is fed examples of right and incorrect responses and, as soon as skilled, can output a confidence rating for the accuracy of any new LLM-generated reply. Whereas efficient, this methodology requires labeled coaching knowledge with optimistic (right) and unfavourable (incorrect) samples to operate precisely.
Tremendous-Tuning the LLM with an Further Confidence Head:
One other method is to fine-tune the LLM by introducing an additional output layer/token that particularly predicts how assured the mannequin is about every generated response. This may be achieved by including an “I-KNOW” token to the LLM structure, which signifies the mannequin’s confidence stage in its response. Nevertheless, coaching this structure requires a balanced dataset containing each optimistic and unfavourable examples to show the mannequin when it is aware of a solution and when it doesn’t.
Computing token Relevance and Significance:
The “Shifting Consideration to Relevance” (SAR) method includes two key components:
- Mannequin’s confidence in predicting a selected phrase: This comes from the mannequin’s token possibilities.
- Significance of the phrase within the sentence: It is a measure of how essential every phrase is to the general which means of the sentence.
The place significance of a phrase is calculated by evaluating the similarity of unique sentence with sentence the place the the phrase is eliminated.
For instance, we all know that the which means of the sentence “of an object” is totally totally different from the which means of “Density of an object”. This suggests that the significance of the phrase “Density” within the sentence could be very excessive. We won’t say the identical for “an” since “Density of an object” and “Density of object” convey related which means.
Mathematically it’s computed as follows –
SAR quantifies uncertainty by combining these components, and the paper calls this “Uncertainty Quantification.”
Think about the sentence: “Density of an object.”. One can compute the entire uncertainty like so –
| Density | of | an | object | |
|---|---|---|---|---|
| Logit from Cross-Entropy (A) |
0.238 | 6.258 | 0.966 | 0.008 |
| Significance (B) | 0.757 | 0.057 | 0.097 | 0.088 |
| Uncertainty (C = A*B) |
0.180 | 0.356 | 0.093 | 0.001 |
| Complete Uncertainty (common of all Cs) |
(0.18+0.35+0.09+0.00)/4 |
This methodology quantifies how essential sure phrases are to the sentence’s which means and the way confidently the mannequin predicts these phrases. Excessive uncertainty scores sign that the mannequin is much less assured in its prediction, which may point out hallucination.
To conclude, entropy-based strategies supply numerous methods to guage the boldness of LLM-generated responses. From easy token chance aggregation to extra superior methods like fine-tuning with extra output layers or utilizing uncertainty quantification (SAR), these strategies present highly effective instruments to detect potential hallucinations and consider correctness.
Keep away from Hallucinations in LLMs
There are a number of methods you may make use of to both forestall or decrease hallucinations, every with totally different ranges of effectiveness relying on the mannequin and use case. As we already mentioned above, slicing down on the sources of hallucinations by enhancing the coaching knowledge high quality and coaching high quality can go an extended option to cut back hallucinations. Listed below are some extra methods that may none the much less be efficient in any state of affairs with any LLM –
1. Present Higher Prompts
One of many easiest but only methods to scale back hallucinations is to craft higher, extra particular prompts. Ambiguous or open-ended prompts typically result in hallucinated responses as a result of the mannequin tries to “fill within the gaps” with believable however probably inaccurate info. By giving clearer directions, specifying the anticipated format, and specializing in express particulars, you may information the mannequin towards extra factual and related solutions.
For instance, as an alternative of asking, “What are the advantages of AI?”, you possibly can ask, “What are the highest three advantages of AI in healthcare, particularly in diagnostics?” This limits the scope and context, serving to the mannequin keep extra grounded.
2. Discover Higher LLMs Utilizing Benchmarks
Choosing the proper mannequin on your use case is essential. Some LLMs are higher aligned with explicit contexts or datasets than others, and evaluating fashions utilizing benchmarks tailor-made to your wants may help discover a mannequin with decrease hallucination charges.
Metrics equivalent to ROUGE, BLEU, METEOR, and others can be utilized to guage how properly fashions deal with particular duties. It is a easy option to filter out the dangerous LLMs earlier than even making an attempt to make use of an LLM.
3. Tune Your Personal LLMs
Tremendous-tuning an LLM in your particular knowledge is one other highly effective technique to scale back hallucination. This customization course of will be executed in varied methods:
3.1. Introduce a P(IK) Token (P(I Know))
On this method, throughout fine-tuning, you introduce a further token (P(IK)) that measures how assured the mannequin is about its output. This token is skilled on each right and incorrect solutions, however it’s particularly designed to calibrate decrease confidence when the mannequin produces incorrect solutions. By making the mannequin extra self-aware of when it doesn’t “know” one thing, you may cut back overconfident hallucinations and make the LLM extra cautious in its predictions.
3.2. Leverage Massive LLM Responses to Tune Smaller Fashions
One other technique is to make use of responses generated by huge LLMs (equivalent to GPT-4 or bigger proprietary fashions) to fine-tune smaller, domain-specific fashions. Through the use of the bigger fashions’ extra correct or considerate responses, you may refine the smaller fashions and educate them to keep away from hallucinating inside your personal datasets. This lets you steadiness efficiency with computational effectivity whereas benefiting from the robustness of bigger fashions.
4. Create Proxies for LLM Confidence Scores
Measuring the boldness of an LLM may help in figuring out hallucinated responses. As outlined within the Entropy-Primarily based Metrics part, one method is to research token possibilities and use these as proxies for the way assured the mannequin is in its output. Decrease confidence in key tokens or phrases can sign potential hallucinations.
For instance, if an LLM assigns unusually low possibilities to essential tokens (e.g., particular factual info), this may increasingly point out that the generated content material is unsure or fabricated. Making a dependable confidence rating can then function a information for additional scrutiny of the LLM’s output.
5. Ask for Attributions and Deliberation
Requesting that the LLM present attributions for its solutions is one other efficient option to cut back hallucinations. When a mannequin is requested to reference particular quotes, sources, or parts from the query or context, it turns into extra deliberate and grounded within the supplied knowledge. Moreover, asking the mannequin to offer reasoning steps (as in Chain-of-Thought reasoning) forces the mannequin to “suppose aloud,” which regularly leads to extra logical and fact-based responses.
For instance, you may instruct the LLM to output solutions like:
“Primarily based on X examine or Y knowledge, the reply is…” or “The explanation that is true is due to Z and A components.” This methodology encourages the mannequin to attach its outputs extra on to actual info.
6. Present Doubtless Choices
If doable, constrain the mannequin’s era course of by offering a number of pre-defined, numerous choices. This may be executed by producing a number of responses utilizing a better temperature setting (e.g., temperature = 1 for artistic range) after which having the mannequin choose probably the most applicable possibility from this set. By limiting the variety of doable outputs, you cut back the mannequin’s probability to stray into hallucination.
As an illustration, when you ask the LLM to decide on between a number of believable responses which have already been vetted for accuracy, it’s much less prone to generate an surprising or incorrect output.
7. Use Retrieval-Augmented Era (RAG) Techniques
When relevant, you may leverage Retrieval-Augmented Era (RAG) programs to reinforce context accuracy. In RAG, the mannequin is given entry to an exterior retrieval mechanism, which permits it to tug info from dependable sources like databases, paperwork, or net sources through the era course of. This considerably reduces the chance of hallucinations as a result of the mannequin just isn’t compelled to invent info when it does not “know” one thing—it could actually look it up as an alternative.
For instance, when answering a query, the mannequin may seek the advice of a doc or information base to fetch related information, guaranteeing the output stays rooted in actuality.
Keep away from Hallucinations throughout Doc Extraction
Armed with information, one can use the next methods to keep away from hallucinations when coping with info extraction in paperwork
- Cross confirm responses with doc content material: The character of doc extraction is such that we’re extracting info verbatim. This implies, if the mannequin returns one thing that isn’t current within the doc, then it means the LLM is hallucinating
- Ask the LLM the situation of knowledge being extracted: When the questions are extra advanced, equivalent to second-order info (like sum of all of the gadgets within the invoice), make the LLM present the sources from the doc in addition to their places in order that we are able to cross examine for ourselves that the knowledge it extracted is reliable
- Confirm with templates: One can use features equivalent to format-check, regex matching to say that the extracted fields are following a sample. That is particularly helpful when the knowledge is dates, quantities or fields which are identified to be inside a template with prior information.
- Use a number of LLMs to confirm: As spoken in above sections, one can use a number of LLM passes in a myriad of the way to verify that the response is all the time constant, and therefore dependable.
- Use mannequin’s logits: One can examine the mannequin’s logits/possibilities to give you a proxy for confidence rating on the essential entities.
Conclusion
Hallucinations are dangerous and inevitable as of 2024. Avoiding them includes a mix of considerate immediate design, mannequin choice, fine-tuning, and confidence measurement. By leveraging the methods talked about, at any stage of the LLM pipeline—whether or not it is throughout knowledge curation, mannequin choice, coaching, or prompting—you may considerably cut back the probabilities of hallucinations and be sure that your LLM produces extra correct and dependable info.