

LLMs leverage the transformer structure, significantly the self-attention mechanism, for top efficiency in pure language processing duties. Nonetheless, as these fashions enhance in depth, many deeper layers exhibit “consideration degeneration,” the place the eye matrices collapse into rank-1, specializing in a single column. These “lazy layers” grow to be redundant as they fail to be taught significant representations. This subject has been noticed in GPT-2 fashions, the place deeper layers lose effectiveness, limiting the mannequin’s capability to enhance with elevated depth. The phenomenon, nevertheless, nonetheless must be explored in normal LLMs.
Numerous research have explored consideration degeneration, primarily specializing in consideration rank and entropy collapse, which trigger illustration points and coaching instability. Earlier analysis has recommended strategies to deal with these issues, similar to adjusting residual connections or including tokens to sequences, although these strategies typically sluggish coaching. In distinction, this work proposes smaller, extra environment friendly fashions that keep away from structural inefficiencies and match the efficiency of bigger fashions. Different strategies like stacking strategies, data distillation, and weight initialization have been efficient in bettering coaching for language fashions, although primarily utilized in imaginative and prescient fashions.
Researchers from the College of Texas at Austin and New York College launched “Inheritune,” a way geared toward coaching smaller, environment friendly language fashions with out sacrificing efficiency. Inheritune includes inheriting early transformer layers from bigger pre-trained fashions, retraining, and progressively increasing the mannequin till it matches or surpasses the unique mannequin’s efficiency. This strategy addresses inefficiencies in deeper layers, the place consideration degeneration results in lazy layers. In experiments on datasets like OpenWebText and FineWeb_Edu, Inheritune-trained fashions outperform bigger fashions and baselines, reaching comparable or superior efficiency with fewer layers.
In transformer-based fashions like GPT-2, deeper layers typically exhibit consideration degeneration, the place consideration matrices collapse into rank-1, resulting in uniform, much less targeted token relationships. This phenomenon, termed “lazy layers,” diminishes mannequin efficiency. To deal with this, researchers developed Inheritune, which initializes smaller fashions by inheriting early layers from bigger pre-trained fashions and progressively expands them by way of coaching. Regardless of utilizing fewer layers, fashions skilled with Inheritune outperform bigger fashions by sustaining targeted consideration patterns and avoiding consideration degeneration. This strategy is validated by way of experiments on GPT-2 variants and huge datasets, reaching environment friendly efficiency enhancements.
The researchers performed in depth experiments on Inheritune utilizing GPT-2 xlarge, giant, and medium fashions pre-trained on the OpenWebText dataset. They in contrast fashions skilled with Inheritune towards three baselines: random initialization, zero-shot initialization strategies, and data distillation. Inheritune fashions constantly outperformed baselines throughout varied sizes, displaying comparable or higher validation losses with fewer layers. Ablation research demonstrated that initializing consideration and MLP weights supplied one of the best outcomes. Even when skilled with out knowledge repetition, Inheritune fashions converged quicker, reaching related validation losses as bigger fashions, confirming its effectivity in decreasing mannequin measurement whereas sustaining efficiency.
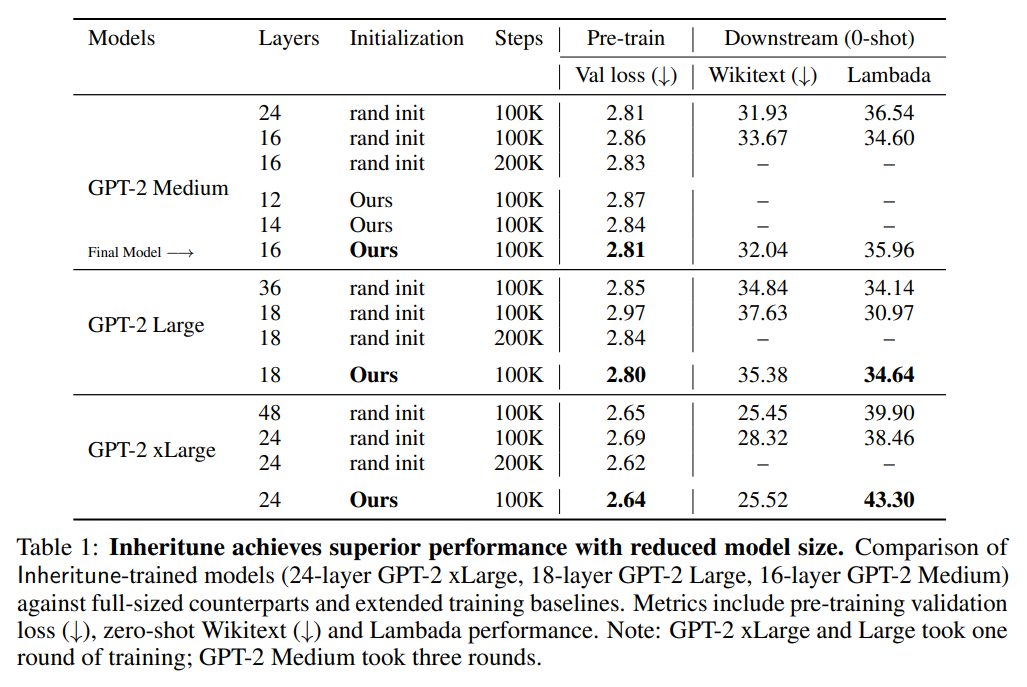
The research identifies a flaw in deep decoder-style transformers, generally utilized in LLMs, the place consideration matrices in deeper layers lose rank, resulting in inefficient “lazy layers.” The proposed Inheritune methodology transfers early layers from a bigger pre-trained mannequin and progressively trains smaller fashions to deal with this. Inheritune achieves the identical efficiency as bigger fashions with fewer layers, as demonstrated on GPT-2 fashions skilled on datasets like OpenWebText-9B and FineWeb_Edu.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication.. Don’t Neglect to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Nice-Tuned Fashions: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.