{kind=link}

The sector of multimodal synthetic intelligence (AI) revolves round creating fashions able to processing and understanding numerous enter sorts akin to textual content, pictures, and movies. Integrating these modalities permits for a extra holistic understanding of information, making it potential for the fashions to supply extra correct and contextually related data. With rising purposes in areas like autonomous programs and superior analytics, highly effective multimodal fashions have develop into important. Though proprietary fashions presently dominate the house, there’s a urgent want for open fashions that provide aggressive efficiency and accessibility for wider analysis and improvement.
A serious situation on this area is the necessity for open-source fashions with excessive effectivity and efficiency throughout varied multimodal duties. Most open-source fashions are restricted in functionality, excelling in a single modality whereas underperforming in others. Alternatively, proprietary fashions like GPT-4o or Gemini-1.5 have demonstrated success throughout numerous duties however are closed to the general public, hindering additional innovation and utility. This creates a major hole within the AI analysis panorama, as researchers want open fashions that may adequately function benchmarks or instruments for additional developments in multimodal analysis.
The AI analysis group has explored varied strategies to construct multimodal fashions, however most of those approaches have wanted assist with the complexity of integrating totally different knowledge sorts. Present open fashions are sometimes designed to deal with solely a single form of enter at a time, like textual content or pictures, making it tough to adapt them for duties that require mixed understanding. Whereas proprietary fashions have proven how multimodal understanding may be achieved, they usually depend on undisclosed coaching methods and knowledge sources, making them inaccessible for broader use. This limitation has left the analysis group on the lookout for an open mannequin to ship robust efficiency in language and visible duties with out entry boundaries.
A group of researchers from Rhymes AI launched Aria, an open multimodal AI mannequin designed from scratch to deal with varied duties, seamlessly integrating textual content, pictures, and video inputs. Aria makes use of a fine-grained mixture-of-experts (MoE) structure, guaranteeing environment friendly computational useful resource utilization and superior efficiency. The mannequin boasts 3.9 billion activated parameters per visible token and three.5 billion per textual content token, making it a strong device for multimodal duties. Additionally, Aria’s mannequin dimension contains 24.9 billion parameters in whole, and it prompts solely a fraction of those parameters at a time, leading to decrease computation prices than absolutely dense fashions.
The technical spine of Aria lies in its mixture-of-experts decoder, which is complemented by a specialised visible encoder. The visible encoder converts visible inputs akin to pictures and video frames into visible tokens with the identical characteristic dimensions as phrase embeddings, enabling the mannequin to combine these seamlessly. Additionally, the mannequin employs a 64,000-token context window, permitting it to course of long-form multimodal knowledge effectively. This prolonged context window units Aria aside from different fashions, making it extremely efficient in duties that require a deep understanding of lengthy and sophisticated sequences, akin to video comprehension and doc evaluation.
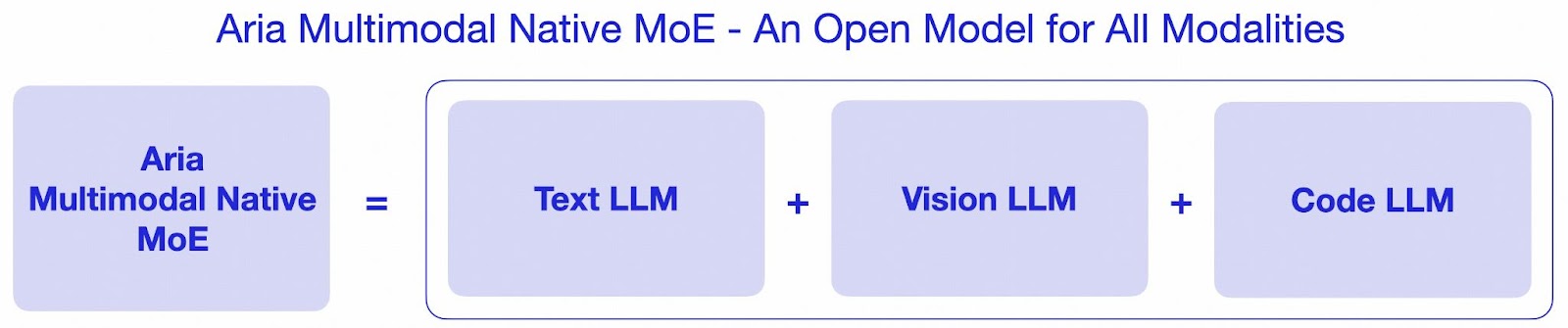

Key Options of Aria:
- Multimodal Native Understanding: Aria is designed to seamlessly course of textual content, pictures, movies, and code in a single mannequin with out requiring separate setups for every enter kind. It demonstrates state-of-the-art efficiency throughout varied multimodal duties and matches or exceeds modality-specialized fashions in understanding capabilities.
- SoTA Multimodal Native Efficiency: Aria performs strongly throughout varied multimodal, language, and coding duties. It excels notably in video and doc understanding, outperforming different fashions in these areas and demonstrating its means to deal with complicated multimodal knowledge effectively.
- Environment friendly Combination-of-Consultants (MoE) Structure: Aria leverages a fine-grained Combination-of-Consultants structure, activating solely a fraction of its whole parameters per token (3.9 billion for visible tokens and three.5 billion for textual content tokens), guaranteeing parameter effectivity and decrease computational prices. That is in comparison with full parameter activation in Pixtral-12B and Llama3.2-11B fashions.
- Lengthy Context Window: The mannequin boasts a protracted multimodal context window of 64,000 tokens, making it able to processing complicated, lengthy knowledge sequences, akin to lengthy paperwork or prolonged movies with subtitles. It considerably outperforms competing fashions like GPT-4o mini and Gemini-1.5-Flash in understanding lengthy papers and movies.
- Excessive Efficiency on Benchmarks: Aria has achieved best-in-class benchmark outcomes for multimodal, language, and coding duties. It competes favorably with high proprietary fashions like GPT-4o and Gemini-1.5, making it a most well-liked selection for doc understanding, chart studying, and visible query answering.
- Open Supply and Developer-Pleasant: Launched beneath the Apache 2.0 license, Aria gives open mannequin weights and an accessible code repository, making it straightforward for builders to fine-tune the mannequin on varied datasets. The help for quick and straightforward inference utilizing Transformers or vllm permits broader adoption and customization.
- Multimodal Native Coaching Pipeline: Aria is educated utilizing a four-stage pipeline: Language Pre-Coaching, Multimodal Pre-Coaching, Multimodal Lengthy-Context Pre-Coaching, and Multimodal Publish-Coaching. This technique progressively enhances the mannequin’s understanding capabilities whereas retaining beforehand acquired information.
- Pre-Coaching Dataset: The mannequin was pre-trained on a big, curated dataset, which incorporates 6.4 trillion language tokens and 400 billion multimodal tokens. This dataset was collected from varied sources, akin to interleaved image-text sequences, artificial picture captions, doc transcriptions, and question-answering pairs.
- Instruction Following Functionality: Aria understands and follows directions based mostly on multimodal and language inputs. It performs higher than open-source fashions on instruction-following benchmarks like MIA-Bench and MT-Bench.
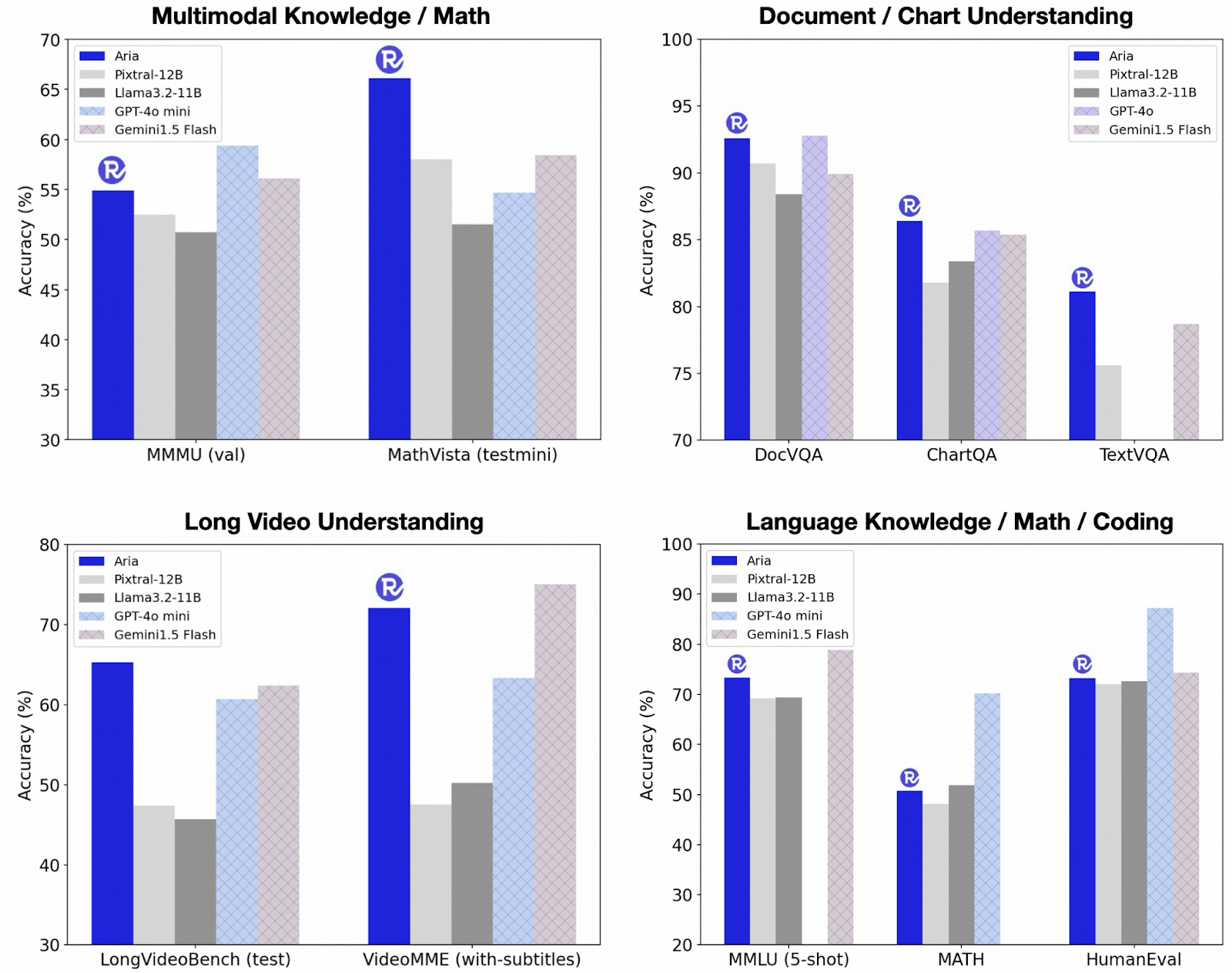
When evaluated in opposition to competing fashions, Aria achieved exceptional outcomes throughout a number of benchmarks. It persistently outperformed open-source fashions like Pixtral-12B and Llama3.2-11B in multimodal understanding duties. As an illustration, Aria scored 92.6% on the TextVQA validation set and 81.8% on the MATH benchmark, highlighting its superior functionality in visible question-answering and mathematical reasoning. As well as, Aria demonstrated state-of-the-art efficiency in long-context video understanding, attaining over 90% accuracy on the VideoMME benchmark with subtitles, surpassing many proprietary fashions. The mannequin’s environment friendly structure additionally leads to decrease computational prices, making it a possible choice for real-world purposes the place each efficiency and cost-efficiency are essential.
Aria is launched beneath the Apache 2.0 license, making it accessible for educational and business use. The analysis group additionally gives a sturdy coaching framework for fine-tuning Aria on varied knowledge sources, permitting customers to leverage the mannequin for particular use circumstances. This open entry to a high-performance multimodal mannequin will catalyze additional analysis and improvement, driving innovation in digital assistants, automated content material technology, and multimodal search engines like google and yahoo.


In conclusion, Aria fills a important hole within the AI analysis group by providing a strong open-source different to proprietary multimodal fashions. Its fine-grained mixture-of-experts structure, light-weight visible encoder, and prolonged context window allow it to carry out exceptionally properly on complicated duties that require complete understanding throughout a number of modalities. Aria is a flexible device for a variety of multimodal purposes by attaining aggressive efficiency on varied benchmarks and providing low computation prices.
Take a look at the Paper, Mannequin, and Particulars. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Information Retrieval Convention (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.