{kind=link}
A brand new speedy DataFrame library referred to as Polars is beginning to flip heads within the information science neighborhood because of its efficiency and adoption price. The open supply challenge, which gives a multithreaded, vectorized question engine for analyzing and manipulating information in Python, not too long ago gained assist for GPUs. And with a cloud model launching quickly by the business outfit behind Polars, the adoption curve appears prone to proceed bending upward.
Polars began out as a facet challenge for Ritchie Vink, a Dutch civil engineer-turned self-trained information scientist. Vink initially started Polars as a solution to discover the usage of question engines, Apache Arrow, and the Rust programming language. However when Vink made the code obtainable as open supply in June 2020, it shortly grew to become obvious that Polars was way more.
Since then, Polars has gained greater than 29,000 GitHub stars, making it one of the well-liked DataFrame libraries round, narrowly trailing entrenched libraries like Apache Spark and Pandas, which have 39,500 and 43,500 stars, respectively. In July, as a part of the Polars 1.0 launch, the Polars challenge introduced that the software program, which is obtainable below an MIT license, was being downloaded 7 million occasions a month, and is being utilized by organizations like Netflix, Microsoft, and UCSF.
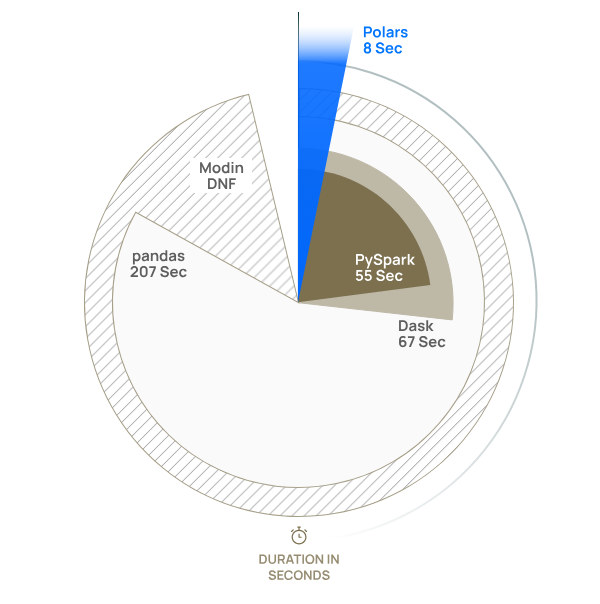
A TPC-H benchmark exhibits Polars beating different question engines (Picture supply Polars)
What has pushed this intense curiosity in Polars and such fast adoption? To cite Lightning McQueen: Velocity.
Polars is simply plain quick. In April, the business outfit behind Polars, which Vink and fellow Xomni worker Chiel Peters co-founded in August 2023, printed the outcomes of a TPC-H benchmark. In a take a look at of seven of twenty-two TPC-H queries on a 10GB dataset, Polars outperformed all different libraries in information wrangling duties, together with DuckDB, PySpark, Dask, Pandas, and Modin (though DuckDB outperformed Polars in some classes). In comparison with pandas, Polars accomplished the information wrangling activity 25 occasions faster.
“Polars simply trumps different options resulting from its parallel execution engine, environment friendly algorithms and use of vectorization with SIMD (Single Instruction, A number of Knowledge),” the corporate says.
Polars was designed to run on a wide range of methods, from laptops to on-prem clusters to assets operating within the cloud. The library was written natively in Rust, which the corporate says provides it distinctive efficiency and fine-grained reminiscence dealing with. It additionally Apache Arrow, which gives integration with different instruments on the reminiscence layer and eliminates the necessity to copy information.
“Polars was written from scratch in Rust, and due to this fact didn’t inherit dangerous design decisions from its predecessors, however as a substitute discovered from them,” Vink wrote in 2023. “Cherry choosing good concepts, and studying from errors.”
Vink says the principle drivers of Polars’ velocity boil right down to a handful of design ideas. For starters, it affords a “strict, constant, and composable API. Polars provides you the hangover up entrance and fails quick, making it very appropriate for writing appropriate information pipelines,” he says.

Ritchie Vink, the creator of Polars and the CEO and Co-founder of an organization by the identical title
Pandas additionally brings a question planner, which helps its job as a front-end to an OLAP engine. “I consider a DataFrame ought to be seen as a materialized view. What’s most essential is the question plan beneath it and the way in which we optimize and execute that plan,” Vink writes.
Clients shouldn’t need to put up with the decrease efficiency bounds of pandas, which is single-threaded. Pandas additionally makes use of NumPy, “although it’s a poor match for relational information processing… Every other device that makes use of pandas inherits the identical poor information sorts and the identical single threaded execution. If the issue is GIL [global interpreter lock] sure, we stay in single threaded Python land.”
In late September, Polars (the corporate) introduced the open beta of a Polars GPU engine. By integrating Nvidia’s RAPIDS cuDF into the challenge, Polars prospects can benefit from the acute parallelism of GPUs, offering as much as a 13x efficiency enhance in comparison with operating Polars on CPUs.
The mix of Polars operating on GPUs through RAPIDS cuDF allows customers to course of a whole lot of tens of millions of rows of knowledge on a single machine in lower than two seconds, based on a weblog submit by Nvidia product advertising supervisor Jamil Semaan.
“Conventional information processing libraries like pandas are single-threaded and turn out to be impractical to make use of past just a few million rows of knowledge. Distributed information processing methods can deal with billions of rows however add complexity and overhead for processing small-to-medium measurement datasets,” Semaan writes.
“Polars…was designed from the bottom as much as deal with these challenges,” he continues. “It makes use of superior question optimizations to scale back pointless information motion and processing, permitting information scientists to easily deal with workloads of a whole lot of tens of millions of rows in scale on a single machine. Polars bridges the hole the place single-threaded options are too gradual, and distributed methods add pointless complexity, providing an interesting ‘medium-scale’ information processing answer.”
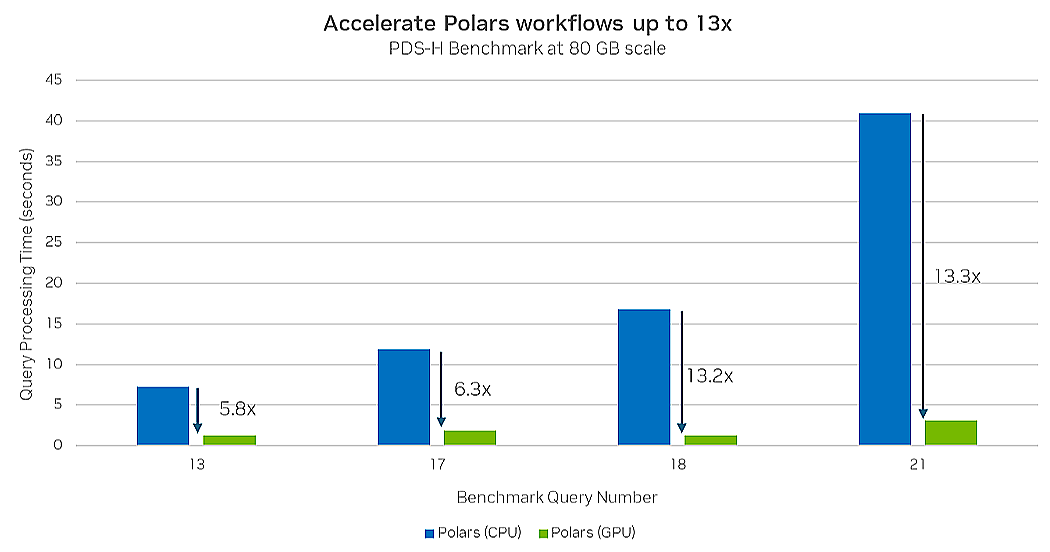 Operating Polars on GPUs provides it a 13x enhance over CPUs (Picture supply Nvidia)
Operating Polars on GPUs provides it a 13x enhance over CPUs (Picture supply Nvidia)As adoption of open supply Polars spreads, Vink and Peters are taking the DataFrame library into the cloud. Later this 12 months, the Polars firm is predicted to launch Polars Cloud, which is able to enable prospects to get Polars methods up and operating shortly on methods managed by AWS. The corporate is encouraging prospects to join the wait record right here.
Within the meantime, early adopters appear completely satisfied to be getting the efficiency advantages of Polars which can be obtainable now.
“The speedup of Polars in comparison with pandas is massively noticeable,” Casey H, a machine studying engineer at G-Analysis, says on the Polars web site. “I usually get pleasure from writing code that I do know is quick.”
“Polars revolutionizes information evaluation, fully changing pandas in my setup,” Matt Whitehead, a quantitative researchers at Optiver, says in a blurb on the Polars web site. “It affords huge efficiency boosts, effortlessly dealing with information frames with tens of millions of rows….Polars isn’t simply quick – it’s lightning-fast.”
“Migrating from pandas to Polars was surprisingly straightforward,” Paul Duvenage, a senior information engineer at Test, writes in a blurb that seems on the Polars web site. “For us, the outcomes velocity for themselves. Polars not solely solved our preliminary drawback however opened the door to new prospects. We’re excited to make use of Polars on future information engineering initiatives.”
Associated Objects:
From Monolith to Microservices: The Way forward for Apache Spark
Knowledge Engineering in 2024: Predictions For Knowledge Lakes and The Serving Layer
Apache Arrow Declares DataFusion Comet