{kind=link}
")
Multimodal giant language fashions (MLLMs) characterize a cutting-edge space in synthetic intelligence, combining numerous knowledge modalities like textual content, pictures, and even video to construct a unified understanding throughout domains. These fashions are being developed to deal with more and more advanced duties resembling visible query answering, text-to-image era, and multi-modal knowledge interpretation. The final word aim of MLLMs is to empower AI techniques to motive and infer with capabilities just like human cognition by concurrently understanding a number of knowledge varieties. This subject has seen fast developments, but there stays a problem in creating fashions that may combine these numerous inputs whereas sustaining excessive efficiency, scalability, and generalization.
One of many crucial issues confronted by the event of MLLMs is reaching a strong interplay between totally different knowledge varieties. Present fashions typically need assistance to steadiness textual content and visible data processing, which results in a drop in efficiency when dealing with text-rich pictures or fine-grained visible grounding duties. Moreover, these fashions need assistance sustaining a excessive diploma of contextual understanding when working throughout a number of pictures. Because the demand for extra versatile fashions grows, researchers are searching for modern methods to boost MLLMs’ capability to deal with these challenges, thereby enabling the fashions to seamlessly deal with advanced situations with out sacrificing effectivity or accuracy.
Conventional approaches to MLLMs primarily depend on single-modality coaching and don’t leverage the complete potential of mixing visible and textual knowledge. This ends in a mannequin that may excel in both language or visible duties however struggles in multimodal contexts. Though current approaches have built-in bigger datasets and extra advanced architectures, they nonetheless endure from inefficiencies in combining the 2 knowledge varieties. There’s a rising want for fashions that may carry out properly on duties that require interplay between pictures and textual content, resembling object referencing and visible reasoning whereas remaining computationally possible and deployable at scale.
Researchers from Apple developed the MM1.5 mannequin household and launched a number of improvements to beat these limitations. The MM1.5 fashions improve the capabilities of their predecessor, MM1, by bettering text-rich picture comprehension and multi-image reasoning. The researchers adopted a novel data-centric method, integrating high-resolution OCR knowledge and artificial captions in a continuing pre-training section. This considerably permits the MM1.5 fashions to outperform prior fashions in visible understanding and grounding duties. Along with general-purpose MLLMs, the MM1.5 mannequin household contains two specialised variants: MM1.5-Video for video understanding and MM1.5-UI for cell UI comprehension. These focused fashions present tailor-made options for particular use instances, resembling decoding video knowledge or analyzing cell display layouts.
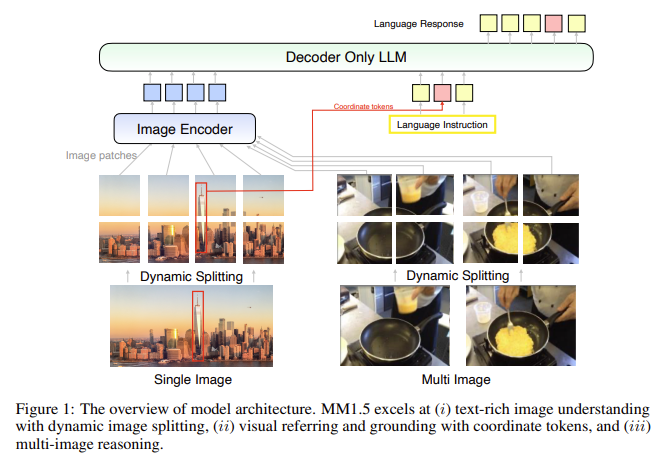
MM1.5 makes use of a novel coaching technique that entails three foremost levels: large-scale pre-training, high-resolution continuous pre-training, and supervised fine-tuning (SFT). The primary stage makes use of a large dataset comprising 2 billion image-text pairs, 600 million interleaved image-text paperwork, and a pair of trillion tokens of text-only knowledge, offering a stable basis for multimodal comprehension. The second stage entails continuous pre-training utilizing 45 million high-quality OCR knowledge factors and seven million artificial captions, which helps improve the mannequin’s efficiency on text-rich picture duties. The ultimate stage, SFT, optimizes the mannequin utilizing a well-curated combination of single-image, multi-image, and text-only knowledge, making it adept at dealing with fine-grained visible referencing and multi-image reasoning.

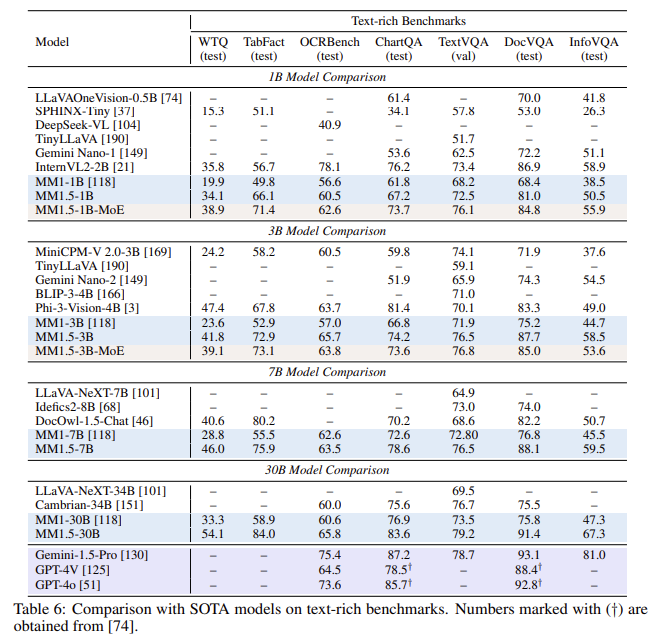
The MM1.5 fashions have been evaluated on a number of benchmarks, exhibiting superior efficiency over open-source and proprietary fashions in numerous duties. For instance, the MM1.5 dense and MoE variants vary from 1 billion to 30 billion parameters, reaching aggressive outcomes even at smaller scales. The efficiency enhance is especially noticeable in text-rich picture understanding, the place the MM1.5 fashions show a 1.4-point enchancment over earlier fashions in particular benchmarks. Moreover, MM1.5-Video, educated solely on picture knowledge with out video-specific knowledge, achieved state-of-the-art ends in video understanding duties by leveraging its robust general-purpose multimodal capabilities.
The intensive empirical research performed on the MM1.5 fashions revealed a number of key insights. The researchers demonstrated that knowledge curation and optimum coaching methods can yield robust efficiency even at decrease parameter scales. Furthermore, together with OCR knowledge and artificial captions in the course of the continuous pre-training stage considerably boosts textual content comprehension throughout various picture resolutions and side ratios. These insights pave the way in which for growing extra environment friendly MLLMs sooner or later, which might ship high-quality outcomes with out requiring extraordinarily large-scale fashions.
Key Takeaways from the Analysis:
- Mannequin Variants: This contains dense and MoE fashions with parameters starting from 1B to 30B, making certain scalability and deployment flexibility.
- Coaching Information: Makes use of 2B image-text pairs, 600M interleaved image-text paperwork, and 2T text-only tokens.
- Specialised Variants: MM1.5-Video and MM1.5-UI provide tailor-made options for video understanding and cell UI evaluation.
- Efficiency Enchancment: Achieved a 1.4-point acquire in benchmarks targeted on text-rich picture understanding in comparison with prior fashions.
- Information Integration: Utilizing 45M high-resolution OCR knowledge successfully and 7M artificial captions considerably boosts mannequin capabilities.

In conclusion, the MM1.5 mannequin household units a brand new benchmark in multimodal giant language fashions, providing enhanced text-rich picture understanding, visible grounding, and multi-image reasoning capabilities. With its rigorously curated knowledge methods, specialised variants for particular duties, and scalable structure, MM1.5 is poised to deal with key challenges in multimodal AI. The proposed fashions show that combining sturdy pre-training strategies and continuous studying methods can lead to a high-performing MLLM that’s versatile throughout numerous purposes, from basic image-text understanding to specialised video and UI comprehension.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Involved in selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.