{kind=link}
 Functions on Factuality, Retrieval Accuracy, and Reasoning")
Retrieval-augmented technology (RAG) has been a transformative strategy in pure language processing, combining retrieval mechanisms with generative fashions to boost factual accuracy and reasoning capabilities. RAG programs excel in producing complicated responses by leveraging exterior sources and synthesizing the retrieved info into coherent narratives. Not like conventional fashions that rely solely on pre-existing data, RAG programs can incorporate real-time knowledge, making them helpful for duties requiring up-to-date info and multi-hop reasoning. This analysis explores how RAG programs deal with complicated queries involving a number of paperwork and temporal disambiguation, thereby precisely reflecting how these programs carry out in real-world eventualities.
The problem with evaluating RAG programs is that present strategies typically have to catch up in capturing their true efficiency. Present benchmarks, akin to TruthfulQA, HotpotQA, and TriviaQA, consider remoted elements like factual accuracy or retrieval precision however want to supply a unified view of how these programs combine a number of points to supply end-to-end reasoning options. In consequence, it turns into tough to evaluate these programs’ effectiveness in dealing with complicated, multi-document queries that require synthesizing info from numerous sources.
Present strategies to judge RAG programs depend on datasets designed for single-turn query answering or factual verification, limiting their applicability to extra complicated, multi-step duties. For example, the TruthfulQA dataset focuses totally on verifying the factual correctness of responses. In distinction, datasets like HotpotQA emphasize retrieving related paperwork with out assessing the reasoning wanted to synthesize this info. Consequently, the dearth of a complete analysis set leads to an incomplete understanding of RAG programs’ efficiency.
The researchers from Google and Harvard College developed the FRAMES (Factuality, Retrieval, And reasoning MEasurement Set) dataset, comprising 824 difficult multi-hop questions that demand integrating info from a number of sources. This distinctive dataset evaluates RAG programs on three core capabilities: factuality, retrieval, and reasoning. The questions cowl numerous subjects, from historical past and sports activities to scientific phenomena, every requiring 2-15 Wikipedia articles to reply. Roughly 36% of the questions contain reasoning by means of a number of constraints, 20% demand numerical comparisons, and 16% require temporal disambiguation. The FRAMES dataset is designed to supply a sensible illustration of queries encountered in real-world functions, thus offering a rigorous check mattress for evaluating state-of-the-art RAG programs.
The analysis launched a multi-step retrieval methodology to enhance the efficiency of RAG programs on complicated queries. Conventional single-step approaches achieved an accuracy of solely 0.40, highlighting the issue even superior fashions face in synthesizing info from a number of sources. Nevertheless, the brand new multi-step retrieval methodology confirmed a big enchancment, with accuracy rising to 0.66 when fashions iteratively retrieved and synthesized related info. This methodology generates a number of search queries in iterative steps, the place every question retrieves top-ranking paperwork added to the mannequin’s context. The mannequin positive factors entry to extra related info with every iteration, enhancing its capability to cause by means of complicated constraints and precisely reply multi-hop questions.

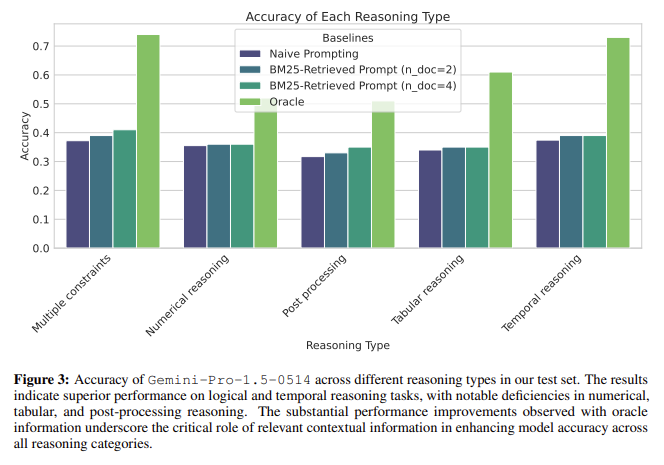
Regardless of these developments, the researchers discovered that the fashions ought to have carried out higher in sure reasoning classes. For instance, the accuracy for numerical reasoning, tabular knowledge extraction, and post-processing remained low, even when all related paperwork had been supplied. The state-of-the-art mannequin achieved 0.40 accuracy in a single-step analysis state of affairs, bettering to 0.45 with two extra paperwork and 0.47 with 4. The Oracle Immediate, the place all vital paperwork had been current within the context, yielded an accuracy of 0.73, demonstrating the potential of good retrieval programs to maximise mannequin efficiency. The examine concludes that whereas RAG programs have made vital strides, they nonetheless face challenges integrating retrieved info into coherent solutions, particularly in complicated eventualities.
This analysis highlights the necessity for additional improvement in RAG programs, notably in enhancing retrieval mechanisms and reasoning capabilities. The findings present a strong basis for future work to concentrate on bettering the combination of complicated, multi-document retrievals and refining reasoning frameworks. By addressing these gaps, RAG programs may turn out to be much more sturdy and able to dealing with real-world queries extra exactly and constantly.
Key Takeaways from the discharge:
- The FRAMES dataset launched 824 questions to judge factuality, retrieval, and reasoning capabilities.
- Roughly 36% of the dataset entails reasoning by means of a number of constraints, and 20% contains numerical comparisons.
- Single-step analysis strategies achieved an accuracy of 0.40, whereas multi-step strategies improved accuracy to 0.66.
- The Oracle Immediate, which included all vital paperwork, was 0.73 correct, indicating the potential of ideally suited retrieval programs.
- Regardless of iterative retrieval enhancements, the examine underscores vital gaps in numerical, tabular, and post-processing reasoning duties.

In conclusion, this analysis offers a complete framework for evaluating RAG programs, showcasing each the progress and the challenges in creating sturdy multi-hop reasoning capabilities. The FRAMES dataset affords a clearer image of how RAG programs carry out in real-world functions, setting the stage for future improvements to bridge the prevailing gaps and advance these programs’ capabilities.
Take a look at the Paper and Dataset. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.