{kind=link}
 Releases Molmo: A Household of Open-Supply Multimodal Language Fashions")
Multimodal fashions symbolize a major development in synthetic intelligence by enabling methods to course of and perceive information from a number of sources, like textual content and pictures. These fashions are important for functions like picture captioning, answering visible questions, and helping in robotics, the place understanding visible and language inputs is essential. With advances in vision-language fashions (VLMs), AI methods can generate descriptive narratives of photographs, reply questions based mostly on visible data, and carry out duties like object recognition. Nonetheless, most of the highest-performing multimodal fashions at present are constructed utilizing proprietary information, which limits their accessibility to the broader analysis neighborhood and stifles innovation in open-access AI analysis.
One of many vital issues going through the event of open multimodal fashions is their dependence on information generated by proprietary methods. Closed methods, like GPT-4V and Claude 3.5, have created high-quality artificial information that assist fashions obtain spectacular outcomes, however this information isn’t out there to everybody. Consequently, researchers face limitations when trying to duplicate or enhance upon these fashions, and the scientific neighborhood wants a basis for constructing such fashions from scratch utilizing absolutely open datasets. This downside has stalled the progress of open analysis within the area of AI, as researchers can not entry the basic parts required to create state-of-the-art multimodal fashions independently.
The strategies generally used to coach multimodal fashions rely closely on distillation from proprietary methods. Many vision-language fashions, for example, use information like ShareGPT4V, which is generated by GPT-4V, to coach their methods. Whereas extremely efficient, this artificial information retains these fashions depending on closed methods. Open-weight fashions have been developed however typically carry out considerably worse than their proprietary counterparts. Additionally, these fashions are constrained by their restricted entry to high-quality datasets, which makes it difficult to shut the efficiency hole with closed methods. Open fashions are thus often left behind in comparison with extra superior fashions from firms with entry to proprietary information.
The researchers from the Allen Institute for AI and the College of Washington launched the Molmo household of vision-language fashions. This new household of fashions represents a breakthrough within the area by offering a wholly open-weight and open-data answer. Molmo doesn’t depend on artificial information from proprietary methods, making it a totally accessible device for the AI analysis neighborhood. The researchers developed a brand new dataset, PixMo, which consists of detailed picture captions created totally by human annotators. This dataset permits the Molmo fashions to be skilled on pure, high-quality information, making them aggressive with the perfect fashions within the area.
The primary launch contains a number of key parts:
- MolmoE-1B: Constructed utilizing the absolutely open OLMoE-1B-7B mixture-of-experts giant language mannequin (LLM).
- Molmo-7B-O: Makes use of the absolutely open OLMo-7B-1024 LLM, set for the October 2024 pre-release, with a full public launch deliberate later.
- Molmo-7B-D: This demo mannequin leverages the open-weight Qwen2 7B LLM.
- Molmo-72B: The best-performing mannequin within the household, utilizing the open-weight Qwen2 72B LLM.
The Molmo fashions are skilled utilizing a easy but highly effective pipeline that mixes a pre-trained imaginative and prescient encoder with a language mannequin. The imaginative and prescient encoder relies on OpenAI’s ViT-L/14 CLIP mannequin, which supplies dependable picture tokenization. Molmo’s PixMo dataset, which comprises over 712,000 photographs and roughly 1.3 million captions, is the inspiration for coaching the fashions to generate dense, detailed picture descriptions. Not like earlier strategies that requested annotators to write down captions, the PixMo dataset depends on spoken descriptions. Annotators have been prompted to explain each picture element for 60 to 90 seconds. This modern strategy allowed for the gathering of extra descriptive information in much less time and offered high-quality picture annotations, avoiding the reliance on artificial information from closed VLMs.
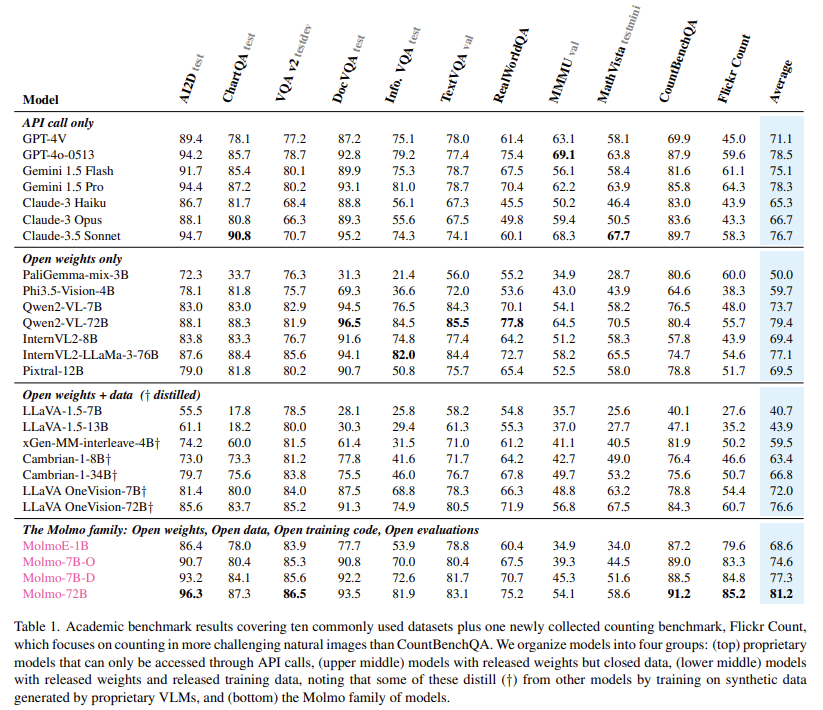
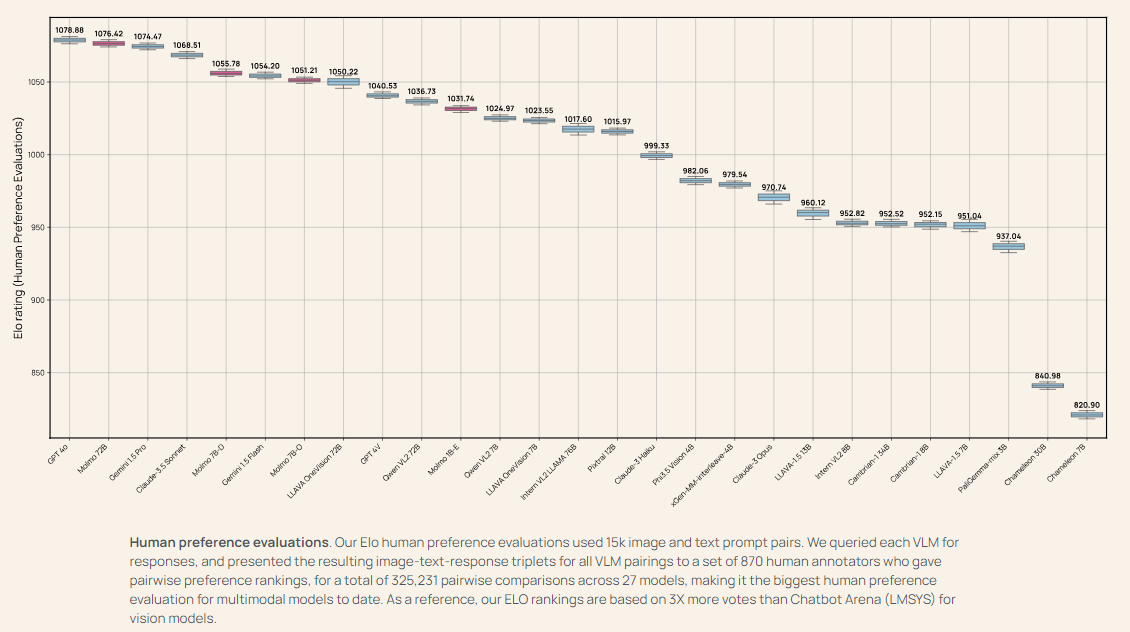
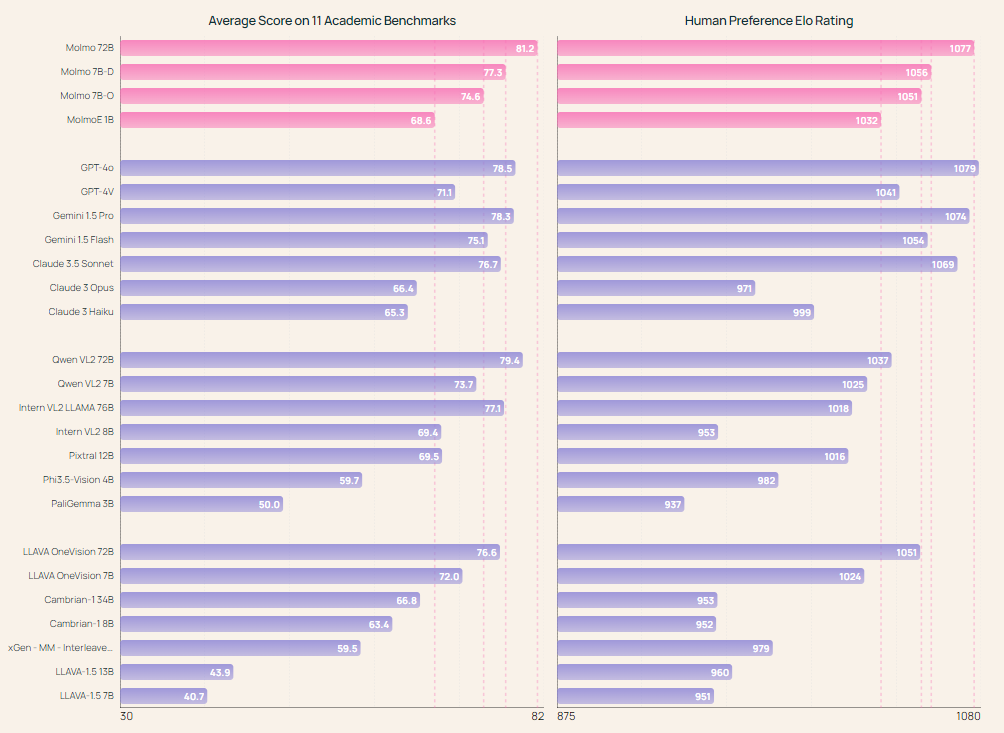
The Molmo-72B mannequin, essentially the most superior within the household, has outperformed many main proprietary methods, together with Gemini 1.5 and Claude 3.5 Sonnet, on 11 educational benchmarks. It additionally ranked second in a human analysis with 15,000 image-text pairs, solely barely behind GPT-4o. The mannequin achieved high scores in benchmarks comparable to AndroidControl, the place it reached an accuracy of 88.7% for low-level duties and 69.0% for high-level duties. The MolmoE-1B mannequin, one other within the household, was in a position to intently match the efficiency of GPT-4V, making it a extremely environment friendly and aggressive open-weight mannequin. The broad success of the Molmo fashions in each educational and consumer evaluations demonstrates the potential of open VLMs to compete with and even surpass proprietary methods.

In conclusion, the event of the Molmo household supplies the analysis neighborhood with a strong, open-access different to closed methods, providing absolutely open weights, datasets, and supply code. By introducing modern information assortment strategies and optimizing the mannequin structure, the researchers on the Allen Institute for AI have efficiently created a household of fashions that carry out on par with, and in some circumstances surpass, the proprietary giants of the sector. The discharge of those fashions, together with the related PixMo datasets, paves the way in which for future innovation and collaboration in growing vision-language fashions, guaranteeing that the broader scientific neighborhood has the instruments wanted to proceed pushing the boundaries of AI.
Take a look at the Fashions on the HF Web page, Demo, and Particulars. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our 52k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.