{kind=link}

Transformer fashions, the spine of contemporary language AI, depend on the eye mechanism to course of context when producing output. Throughout inference, the eye mechanism works by computing the important thing and worth vectors for every token seen to date, and utilizing these vectors to replace the inner illustration of the subsequent token which might be output. As a result of the identical key and worth vectors of the previous tokens get reused each time the mannequin outputs a brand new token, it’s commonplace apply to cache it in an information construction referred to as the Key-Worth (KV) cache. For the reason that KV cache grows proportionally to the variety of tokens seen to date, KV cache measurement is a significant factor in figuring out each the utmost context size (i.e., the utmost variety of tokens) and the utmost variety of concurrent requests that may be supported for inference on trendy language fashions. Significantly for lengthy inputs, LLM inference can be dominated by the I/O price of shifting the KV cache from Excessive Bandwidth Reminiscence (HBM) to the GPU’s shared reminiscence. Subsequently, reducing the KV cache measurement has the potential to be a robust methodology to hurry up and scale back the price of inference on trendy language fashions. On this submit, we discover concepts not too long ago proposed by Character.AI for lowering KV cache measurement by changing many of the layers within the community with sliding window consideration (a type of native consideration that solely makes use of the important thing and worth vectors of a small variety of most up-to-date tokens) and sharing the KV cache amongst layers. We name this structure MixAttention; our experiments with completely different variants of this structure have demonstrated that it maintains each quick and lengthy context mannequin high quality whereas enhancing the inference velocity and reminiscence footprint.
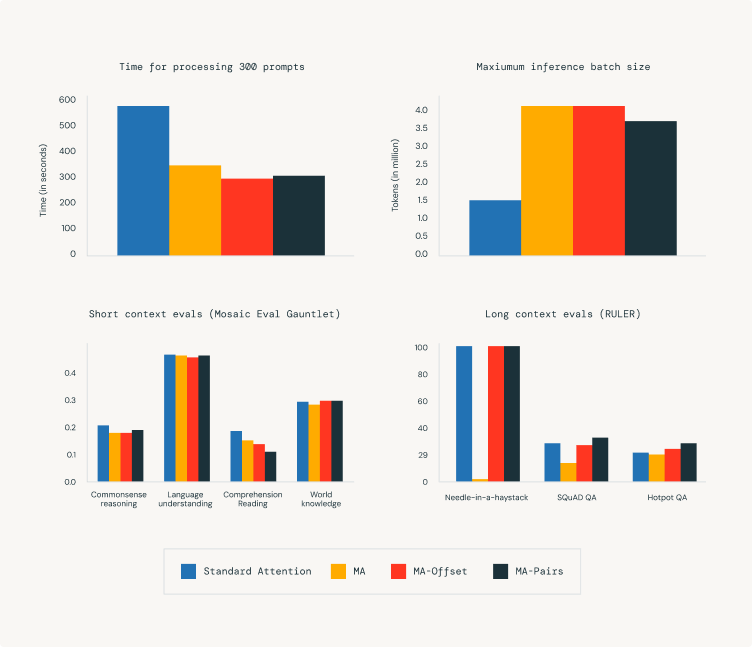
We discovered that KV cache sharing between layers and including sliding window layers can velocity up inference and scale back inference reminiscence utilization whereas sustaining mannequin high quality, though some eval metrics present some degradation. As well as, our ablation experiments confirmed the next:
- Having just a few commonplace consideration layers is essential for the mannequin’s lengthy context talents. Specifically, having the usual KV cache computed within the deeper layers is extra necessary for lengthy context talents than the usual KV cache of the primary few layers.
- KV cache of normal consideration layers will be shared between non-consecutive layers with none noticed degradation in lengthy context talents.
- Rising the KV-cache sharing between sliding window layers an excessive amount of additionally hurts lengthy context talents.
Now we have offered a information to configuring and coaching MixAttention fashions utilizing LLM Foundry within the appendix of this weblog submit.

MixAttention Structure Overview
Customary transformer fashions use international consideration in every layer. To create inference-friendly mannequin architectures, we used a mixture of sliding window consideration layers, commonplace consideration, and KV cache reuse layers. Beneath is a quick dialogue of every part:
- Sliding Window Consideration Layers: In Sliding Window Consideration (or Native Consideration) with window measurement s, the question solely pays consideration to the final s keys as an alternative of all of the keys previous it. Which means throughout inference, the KV cache measurement must solely retailer the KV tensors for the previous s tokens as an alternative of storing the KV tensors for all of the previous tokens. In our experiments, we set a window measurement of s=1024 tokens.
- Customary Consideration Layers: We discovered that though Customary Consideration Layers result in larger KV caches and slower consideration computation in comparison with Sliding Window Consideration, having just a few Customary Consideration Layers is essential for the mannequin’s lengthy context talents.
- KV cache reuse: This refers to a layer within the transformer community that’s reusing the KV cache computed by a earlier layer. Therefore, if each l layers share KV tensors, then the scale of KV cache is decreased by issue of 1/l.
We experimented with completely different combos of the elements above to ablate the results of every of them. (Extra combos are described within the appendices.) We discovered that not solely do every of the above elements play necessary roles in lengthy context talents and inference velocity and reminiscence consumption, but additionally their relative positions and counts have important results on these metrics.
The fashions we skilled are 24-layer Combination of Consultants (MoE) fashions with 1.64B energetic and 5.21B whole parameters. We used RoPE positional embeddings and elevated the RoPE base theta as we elevated the context size throughout coaching. We used Grouped Question Consideration with 12 consideration heads and three KV heads.
Coaching
We used LLM Foundry to coach MixAttention fashions. Just like prior work on coaching lengthy context fashions, we adopted a multi-stage coaching process to impart lengthy context talents to the fashions.
- We pretrained the fashions with a RoPE theta of 0.5M on 101B tokens, the place every sequence has been truncated to 4k token size.
- To extend the context size, we then skilled the mannequin on 9B tokens from a mixture of pure language and code knowledge, the place the sequences have been truncated to 32k tokens. We elevated the RoPE theta to 8M for this stage. When coaching at 32k context size, we skilled solely the eye weights and froze the remainder of the community. We discovered that this delivered higher outcomes than full community coaching.
- Lastly, we skilled the mannequin on a 32k-length, artificial, long-context QA dataset.
- To create the dataset, we took pure language paperwork and chunked them into 1k-token chunks. Every chunk was then fed to a pretrained instruction mannequin and the mannequin was prompted to generate a question-answer pair based mostly on the chunk. Then, we concatenated chunks from completely different paperwork collectively to function the “lengthy context.” On the finish of this lengthy context, the question-answer pairs for every of the chunks have been added. The loss gradients have been computed solely on the reply components of those sequences.
- This part of coaching was carried out on 500M tokens (this quantity contains the tokens from the context, questions, and solutions). The RoPE theta was saved at 8M for this stage.
Analysis
The fashions have been evaluated on the Mosaic Analysis Gauntlet to measure mannequin high quality throughout numerous metrics together with studying comprehension, commonsense reasoning, world information, symbolic drawback fixing, and language understanding. To guage the fashions’ lengthy context talents, we used RULER at a context size of 32000 tokens. RULER is a composite benchmark consisting of 13 particular person evals of the next varieties:
- Needle-in-a-haystack (NIAH): Some of these evals cover a single or a number of keys and values in an extended textual content, and the mannequin is evaluated on its capacity to retrieve the right worth(s) from the lengthy context for a given key(s).
- Variable Monitoring (VT): This eval gives the mannequin with an extended context containing variable task statements, and the mannequin is tasked to determine which variables have a specific worth by the tip of all of the variable assignments.
- Widespread and Frequent Phrase Extraction (CWE and FWE): These duties ask the mannequin to extract the commonest or frequent phrases from the textual content.
- Query Answering (QA): Given an extended context, the mannequin is requested a query from someplace within the context and is evaluated on whether or not it will possibly appropriately reply that query.
We used SGLang to deploy our fashions on 1 NVIDIA H100 GPU to run RULER and get inference velocity and reminiscence consumption metrics.
Outcomes
Place and Rely of Customary Consideration KV Caches
To measure the impact of the place and rely of the usual consideration KV caches, we tried 4 variants. All of the configurations are variants of the configuration proposed in Character.AI’s weblog submit.
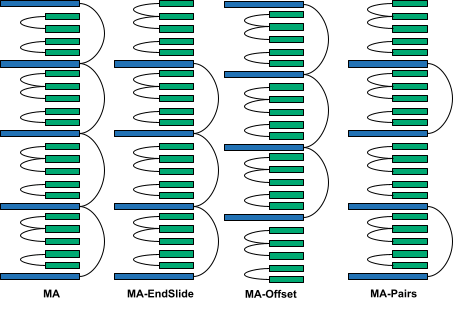
- MA: This variant has a single commonplace consideration KV cache, which is the KV cache of the primary layer. All the opposite commonplace consideration layers share this KV cache.
- MA-EndSlide: This variant is similar as MA, however the final layer is a sliding window consideration layer. This was completed to measure how a lot having commonplace consideration within the final layer impacts long-context talents.
- MA-Offset: This variant is just like MA, however the first commonplace consideration layer is offset to a later layer to permit the mannequin to course of the native context for just a few layers earlier than the usual consideration layer is used to take a look at longer contexts.
- MA-Pairs: This variant computes two commonplace consideration KV caches (on the first and thirteenth layers), that are then shared with one other commonplace consideration layer every.
We in contrast these fashions to a transformer mannequin with Customary Consideration and a transformer mannequin with Sliding Window Consideration in all layers.

Whereas the loss curves in Phases 1 and a couple of of Coaching have been shut for all of the fashions, we discovered that in Stage 3 (coaching on lengthy context QA dataset), there was a transparent bifurcation within the loss curves. Specifically, we see that configurations MA and MA-EndSlide present a lot worse loss than the others. These outcomes are in line with the lengthy context RULER evals, the place we discovered that MA and MA-EndSlide carried out a lot worse than others. Their efficiency was just like the efficiency of the community with solely sliding window consideration in all layers. We expect the loss in Stage 3 correlates nicely with RULER evals as a result of not like Phases 1 and a couple of, which have been next-word prediction duties the place native context was ample to foretell the subsequent phrase more often than not, in Stage 3 the mannequin wanted to retrieve the right info from doubtlessly long-distance context to reply the questions.
As we see from the RULER evals, MA-Offset and MA-Pairs have higher long-context talents than MA and MA-EndSlide throughout all of the classes. Each MA and MA-EndSlide have just one commonplace consideration KV cache, which is computed within the first layer, whereas each MA-Offset and MA-Pairs have no less than one commonplace consideration KV cache which is computed in deeper layers. Therefore, this means that having no less than one commonplace consideration KV cache computed within the deeper layers of a transformer mannequin is important for good long-context talents.
KV cache sharing in sliding window layers
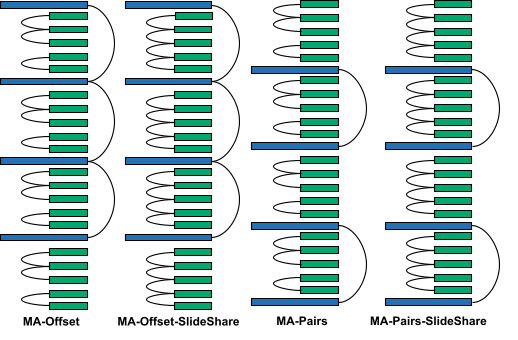
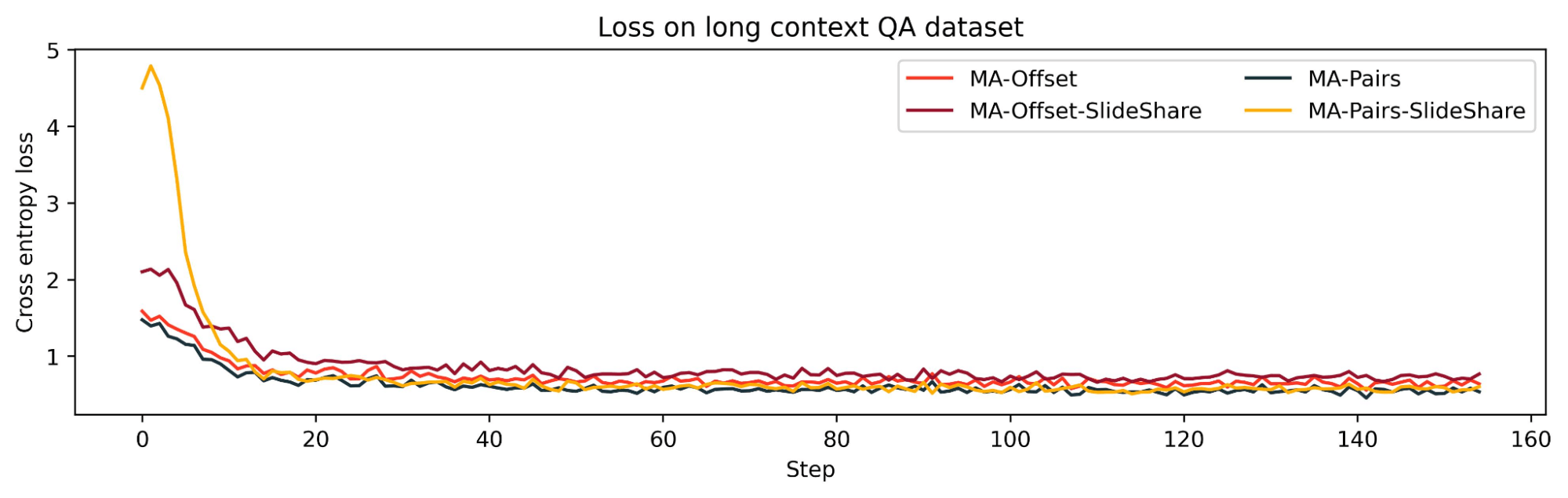

We discovered that growing the sharing between sliding window layers degraded the mannequin’s lengthy context efficiency: MA-Offset-slide-share was worse than MA-Offset and MA-Pairs-SlideShare was worse than MA-Pairs. This exhibits that the KV cache sharing sample amongst the sliding window layers can be necessary for lengthy context talents.
Now we have offered the outcomes of some extra ablation experiments within the appendices.
Gauntlet Evals
Utilizing the Mosaic Eval Gauntlet v0.3.0, we additionally measured the efficiency of MixAttention fashions on commonplace duties like MMLU, HellaSwag, and many others. to confirm that they maintain good shorter context talents. The entire duties on this eval suite have context lengths of lower than just a few thousand tokens.
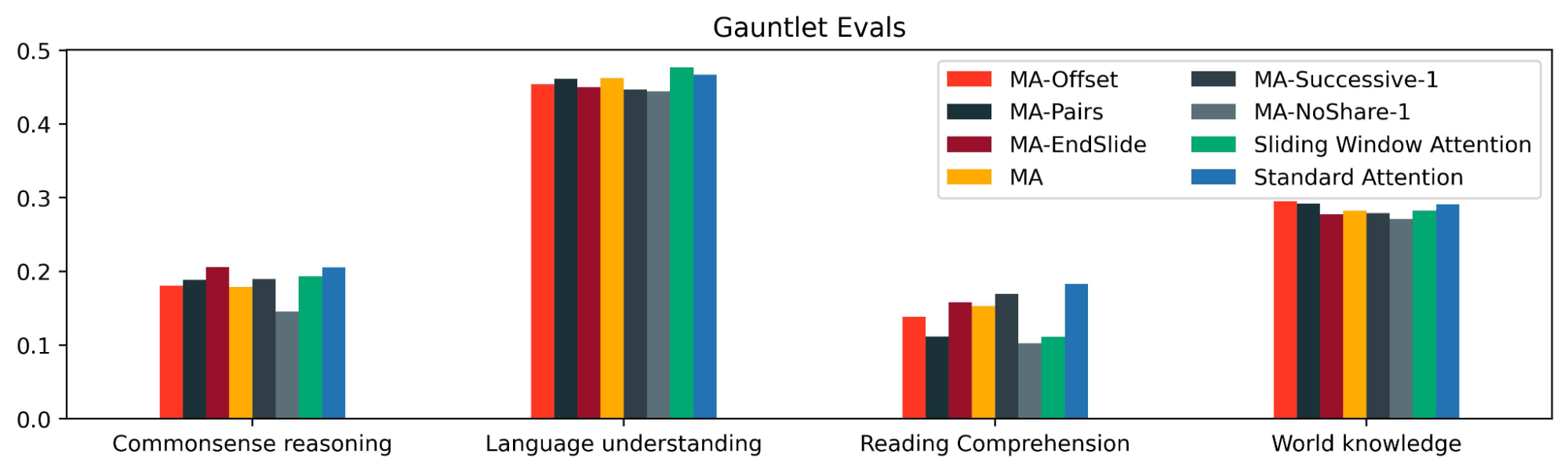
We discovered that MixAttention fashions have related eval metrics to the baseline mannequin on commonsense reasoning, language understanding, and world information; nonetheless, they carried out worse on studying comprehension. An attention-grabbing open query is that if studying comprehension talents could possibly be improved with a unique MixAttention configuration or by coaching MixAttention fashions longer.
Inference Pace and Reminiscence Consumption

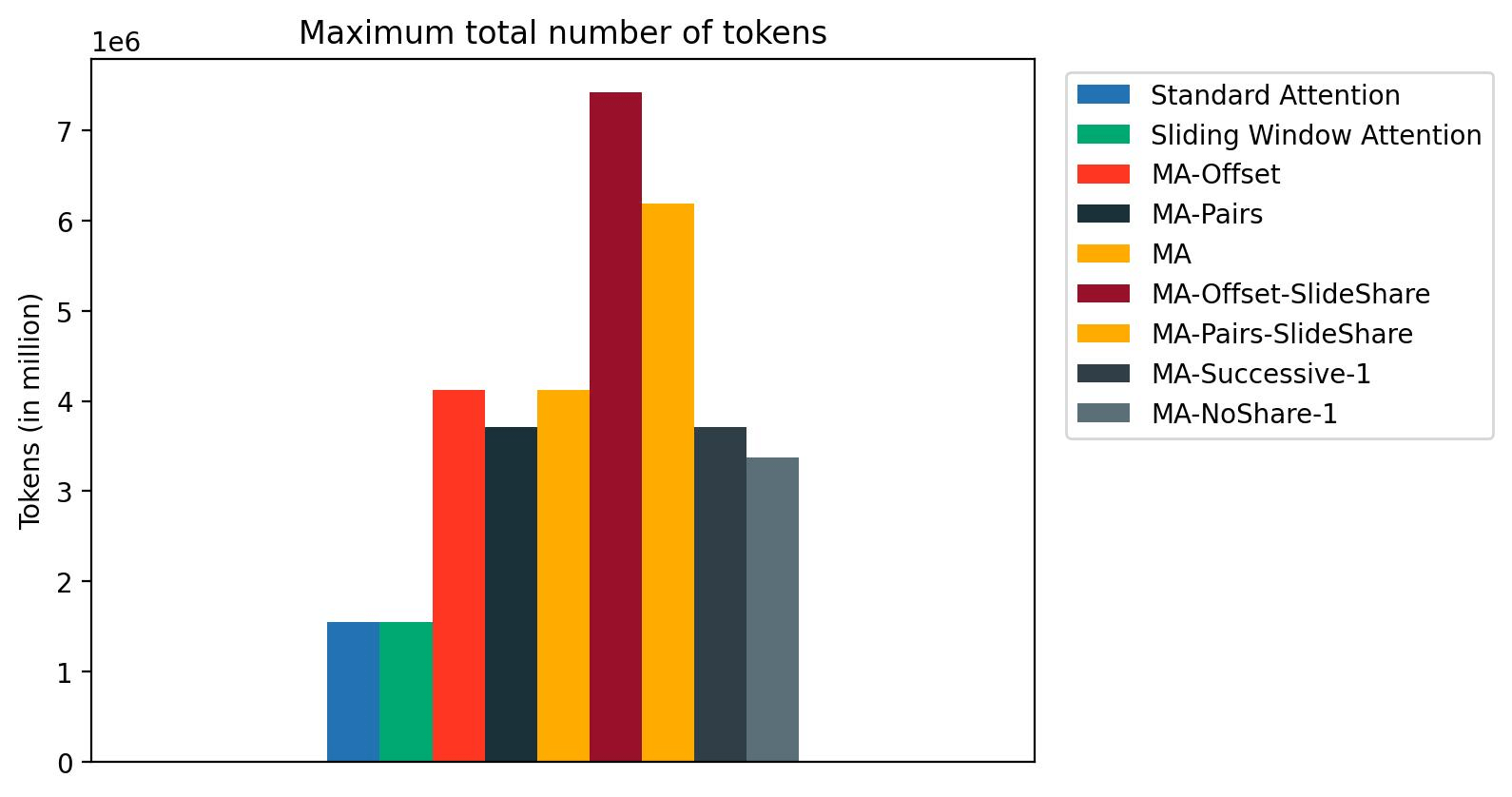
We benchmarked the inference velocity and reminiscence consumption of MixAttention fashions by deploying them on a single NVIDIA H100 GPU utilizing SGLang and querying them with 300 prompts, with an enter size of 31000 and output size of 1000. Within the determine, we present that the inference velocity of MixAttention fashions is far sooner than commonplace consideration fashions. We additionally present that with MixAttention, we will assist a a lot bigger inference batch measurement when it comes to the full variety of tokens.
We discovered that the present implementation of Sliding Window Consideration in SGLang doesn’t optimize the reminiscence consumption for sliding window consideration; therefore, sliding window consideration has the identical most variety of tokens as the usual consideration Mannequin. Optimizing the reminiscence consumption for sliding window consideration ought to additional improve the utmost variety of tokens that MixAttention can assist throughout inference.
Conclusion
We discovered that MixAttention fashions are aggressive with commonplace consideration fashions on each long- and short-context talents whereas being sooner throughout inference and supporting bigger batch sizes. We additionally noticed that on some lengthy context duties like Variable Monitoring and Widespread Phrase Extraction, neither MixAttention nor commonplace consideration fashions carried out nicely. We imagine this was as a result of our fashions weren’t skilled lengthy sufficient or the fashions want a unique form of lengthy context knowledge to be skilled for such duties. Extra analysis must be completed to measure the impression of MixAttention architectures on these metrics.
We encourage others to discover extra MixAttention architectures to be taught extra about them. Beneath are just a few observations to assist with additional analysis:
- Including a normal consideration layer within the preliminary layers by itself doesn’t appear to assist lengthy context talents (for instance, see MA-NoShare-1 within the appendix), even when the KV cache from that layer is reused in layers deeper into the community (MA and MA-EndSlide). Therefore we suggest putting the primary commonplace consideration layer deeper within the community (like MA-Offset) or having a number of commonplace consideration layers, no less than considered one of which is computed at a deeper layer (like MA-Pairs).
- Sliding window layers additionally contribute to the mannequin’s lengthy context talents. Rising the KV cache sharing amongst the sliding window layers worsened lengthy context talents (MA-Offset-SlideShare and MA-Pairs-SlideShare). For that motive, we expect that the 2-3 sharing sample in sliding window layers appears to strike a great stability.
- Sharing full consideration KV caches between consecutive layers gave combined outcomes, with barely worse accuracy on lengthy context QA duties (see the appendix).
- In our experiments, MA-Offset and MA-Pair confirmed nice speedup and reminiscence financial savings throughout inference, whereas additionally sustaining lengthy and quick context talents. Therefore, MA-Offset and MA-Pairs may be good configurations for additional analysis.
- MixAttention fashions will be skilled with LLM Foundry. Please see the appendix for tips.
Normally, there’s a massive hyperparameter area to discover, and we look ahead to seeing quite a lot of new methods for lowering the price of inference by way of combos of sliding window consideration and KV cache reuse.
Appendix: Utilizing LLM Foundry to coach MixAttention fashions
The way in which to configure MixAttention fashions with LLM Foundry is to make use of the block_overrides characteristic. The block_overrides definition consists of two sections: order and overrides. The order key defines the ordering and the names of the layers within the community, whereas the overrides key comprises the customized configuration of every named layer.
For instance, to create a 5 layer community with the primary two layers being the usual consideration layers, the subsequent two being the sliding window layers, and the final one being a normal consideration layer, we use the next YAML:

Right here, the order part conveys that the primary two layers are of kind ‘default’, the subsequent two are of kind ‘sliding_window_layer’, and the final is of kind ‘default’ once more. The definitions of every of those varieties are contained within the overrides part utilizing the names outlined within the order part. It says that the ‘sliding_window_layer‘ ought to have a sliding_window_size of 1024. Word that ‘default’ is a particular kind, which doesn’t want a definition within the overrides part as a result of it simply refers back to the default layer (on this case, a normal consideration layer). Additionally, observe that ‘sliding_window_layer‘ is only a customized title and will be changed with every other arbitrary title so long as that title is correspondingly additionally outlined within the overrides part.
The mannequin configuration is printed within the logs, which can be utilized to substantiate that the mannequin is configured appropriately. For instance, the above YAML will end result within the following being printed within the logs:

We are able to additionally configure the 2 sliding window layers to have completely different sliding window sizes as follows:

The above will end result within the third layer having a sliding window measurement of 1024, and the fourth layer having a sliding window measurement of 512. Word that the repeat key phrase defaults to 1. So, the above YAML can be written as:

The repeat key phrase can be relevant to the order key phrase. So, if we wish to create a 4 layer community with alternating commonplace and sliding window consideration layers like the next,

then we will use the next YAML:

To make a layer reuse the KV cache of a earlier layer, we use reuse_kv_layer_idx within the attn_config within the override definition. The important thing reuse_kv_layer_idx comprises the relative layer index whose KV cache we would like this layer to reuse. To make a two layered community the place the second layer reuses the primary layer’s KV cache, we will use the next YAML:

The worth -1 signifies that the layer named kv_reuse_layer reuses the KV cache of the layer that’s one layer earlier than it. To create a 5 layer community with the next configuration

we will use the next YAML:

Word that within the above configuration, layer #4 reuses the KV cache of layer #3, which in flip reuses the KV cache of layer #2. Therefore, layer #4 finally ends up reusing the KV cache of layer #2.
Lastly, observe that order will be outlined recursively; that’s, the order can include one other order sub-block. For instance, MA-Offset-SlideShare

will be outlined as follows:

Appendix: Different Ablation Experiments
Sharing Customary Consideration KV Caches between Consecutive Layers
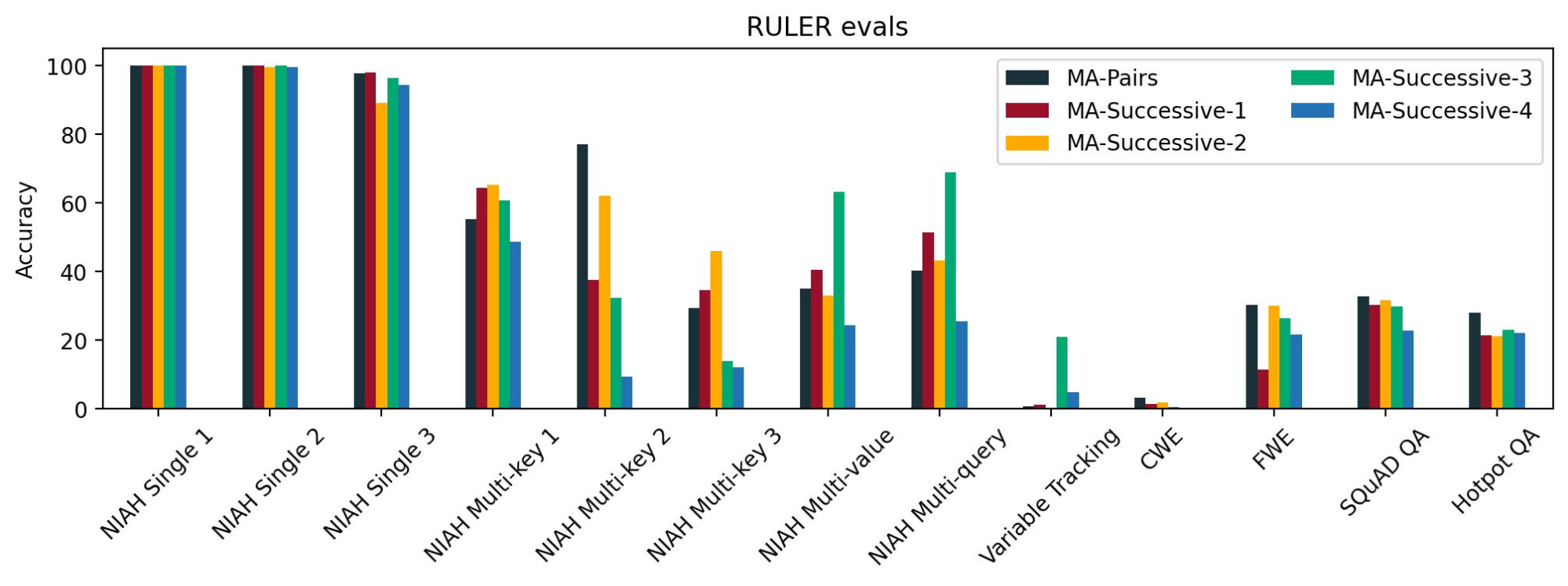
For the reason that transformer layers progressively replace the latent illustration of a token because it progresses via the layers, the Question, Key, and Worth tensors may need considerably completely different representations for layers which might be far aside. Therefore, it’d make extra sense to share KV caches between consecutive layers. To check this, we in contrast 4 such configurations: MA-Successive-1, MA-Successive-2, MA-Successive-3, and MA-Successive-4 in opposition to MA-Pairs. These configurations differ the positions of the usual KV consideration layers and the space between the consecutive pairs of normal KV consideration layers.

For the reason that transformer layers progressively replace the latent illustration of a token because it progresses via the layers, the Question, Key, and Worth tensors may need considerably completely different representations for layers which might be far aside. Therefore, it’d make extra sense to share KV caches between consecutive layers. To check this, we in contrast 4 such configurations: MA-Successive-1, MA-Successive-2, MA-Successive-3, and MA-Successive-4 in opposition to MA-Pairs. These configurations differ the positions of the usual KV consideration layers and the space between the consecutive pairs of normal KV consideration layers.

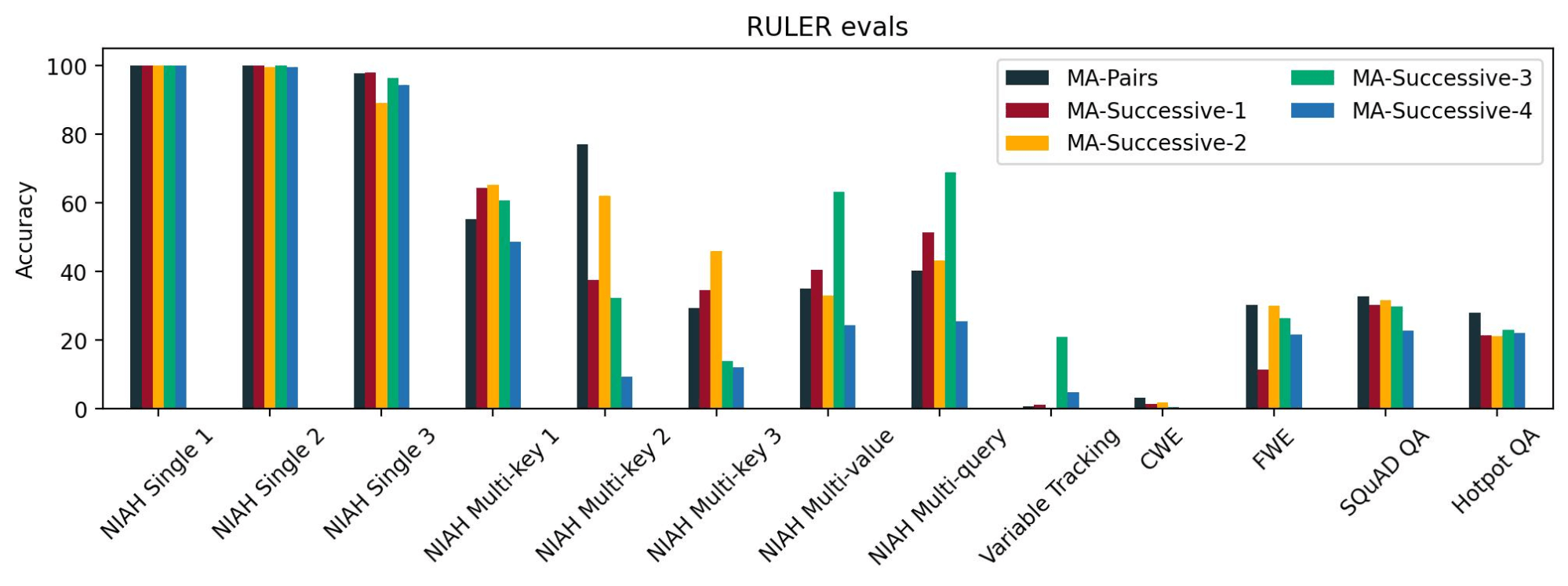
We decided that every one the fashions have related loss curves and related efficiency on NIAH single 1, 2, and three duties, which we take into account to be the simplest lengthy context duties. Nonetheless, we didn’t see a constant sample throughout the opposite NIAH duties. For lengthy context QA duties, we discovered that MA-Pairs was barely higher than the others. These outcomes point out that sharing commonplace consideration KV cache between layers which might be additional aside doesn’t result in any important degradation in lengthy context talents as in comparison with sharing commonplace consideration KV cache between consecutive layers.
Impact of Sharing Customary Consideration KV Cache

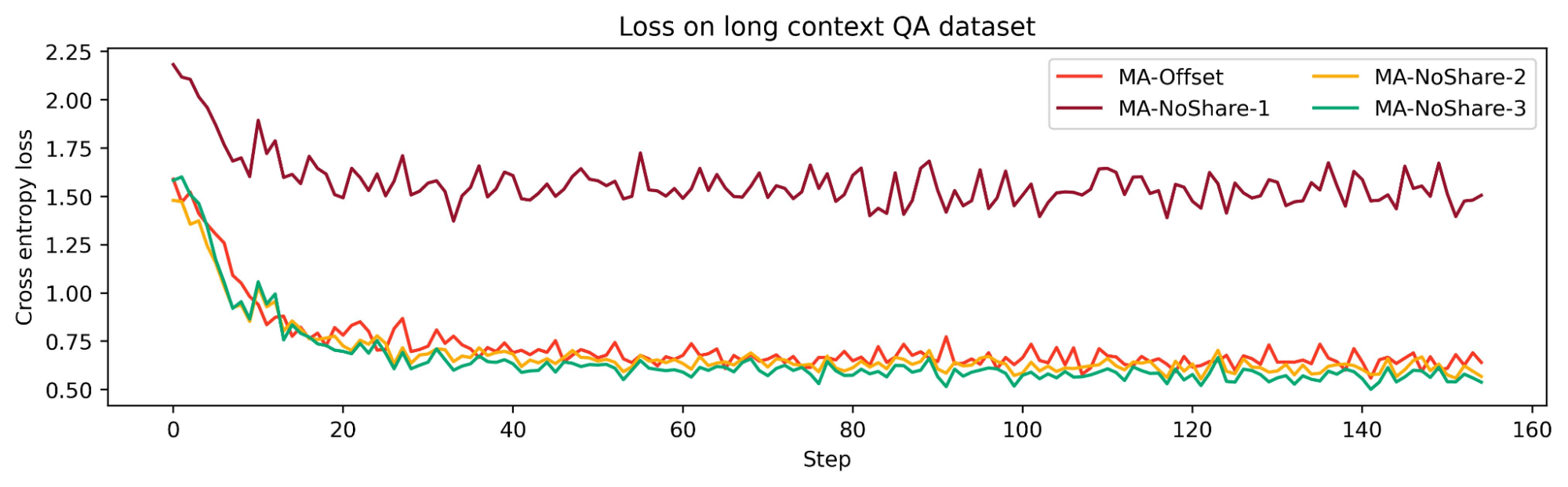
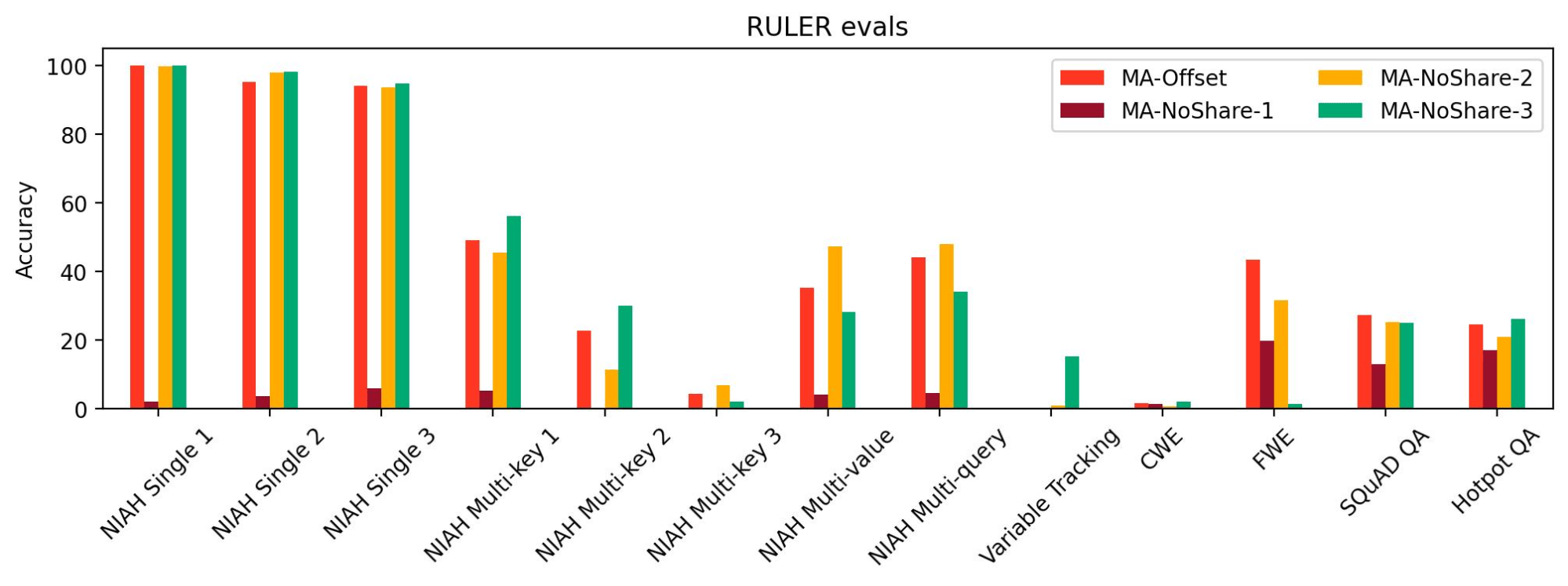
To check the impact of sharing the KV cache between commonplace consideration layers, we tried out three configurations: MA-NoShare-1, MA-NoShare-2, and MA-NoShare-3. We discovered that MA-NoShare-1 carried out very badly on RULER, indicating its lack of lengthy context talents. Nonetheless, MA-NoShare-2 and MA-NoShare-3 have been akin to MA-Offset on lengthy context duties. Therefore, we expect that additional analysis is required to establish the results of sharing commonplace consideration KV cache.