{kind=link}

Computerized speech recognition (ASR) has turn out to be an important space in synthetic intelligence, specializing in the flexibility to transcribe spoken language into textual content. ASR know-how is extensively utilized in numerous functions comparable to digital assistants, real-time transcription, and voice-activated techniques. These techniques are integral to how customers work together with know-how, offering hands-free operation and enhancing accessibility. Because the demand for ASR grows, so does the necessity for fashions that may deal with lengthy speech sequences effectively whereas sustaining excessive accuracy, particularly in real-time or streaming situations.
One important problem with ASR techniques is their capability to effectively course of lengthy speech utterances, particularly in units with restricted computing sources. ASR fashions’ complexity will increase because the enter speech’s size grows. For example, many present ASR techniques depend on self-attention mechanisms, like multi-head self-attention (MHSA), which seize international interactions between acoustic frames. Whereas efficient, these techniques have quadratic time complexity, that means that the time required to course of speech grows with the size of the enter. This turns into a important bottleneck when implementing ASR on low-latency units comparable to cellphones or embedded techniques, the place velocity and reminiscence consumption are extremely constrained.
A number of strategies have been proposed to cut back the computational load of ASR techniques. MHSA, whereas extensively used for its capability to seize fine-grained interactions, is inefficient for streaming functions resulting from its excessive computational & reminiscence necessities. To deal with this, researchers have explored options comparable to low-rank approximations, linearization, and sparsification of self-attention layers. Different improvements, like Squeezeformer and Emformer, intention to cut back sequence size throughout processing. Nonetheless, these approaches solely mitigate the affect of the quadratic time complexity with out eliminating it, resulting in marginal features in effectivity.
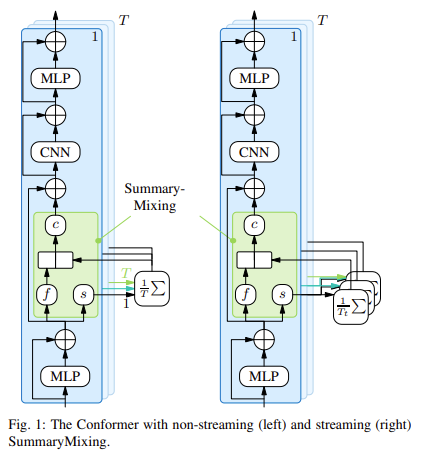
Researchers from the Samsung AI Middle – Cambridge have launched a novel technique referred to as SummaryMixing, which reduces the time complexity of ASR from quadratic to linear. This technique, built-in right into a conformer transducer structure, permits extra environment friendly speech recognition for streaming and non-streaming modes. The conformer-based transducer is a extensively used mannequin in ASR resulting from its capability to deal with giant sequences with out sacrificing efficiency. SummaryMixing considerably enhances the conformer’s effectivity, significantly in real-time functions. The tactic replaces MHSA with a extra environment friendly mechanism that summarizes the whole enter sequence right into a single vector, permitting the mannequin to course of speech sooner and with much less computational overhead.
The SummaryMixing strategy includes remodeling every body of the enter speech sequence utilizing a neighborhood non-linear perform whereas concurrently summarizing the whole sequence right into a single vector. This vector is then concatenated to every body, preserving international relationships between frames whereas lowering computational complexity. This method permits the system to take care of accuracy corresponding to MHSA however at a fraction of the computational value. For instance, when evaluated on the Librispeech dataset, SummaryMixing outperformed MHSA by reaching a phrase error fee (WER) of two.7% on the “dev-clean” set, in comparison with MHSA’s 2.9%. The tactic demonstrated even larger enhancements in streaming situations, lowering the WER from 7.0% to six.9% on longer utterances. Furthermore, SummaryMixing requires considerably much less reminiscence, lowering peak VRAM utilization by 16% to 19%, relying on the dataset.
The researchers carried out experiments to validate SummaryMixing’s effectivity additional. On the Librispeech dataset, the system demonstrated a notable discount in coaching time. Coaching with SummaryMixing required 15.5% fewer GPU hours than MHSA, leading to sooner mannequin deployment. Relating to reminiscence consumption, SummaryMixing decreased peak VRAM utilization by 3.3 GB for lengthy speech utterances, demonstrating its scalability for brief and lengthy sequences. The system’s efficiency was additionally examined on Voxpopuli, a tougher dataset with various accents and recording circumstances. Right here, SummaryMixing achieved a WER of 14.1% in streaming situations, in comparison with 14.6% for MHSA, whereas utilizing an infinite left-context, considerably enhancing accuracy for real-time ASR techniques.
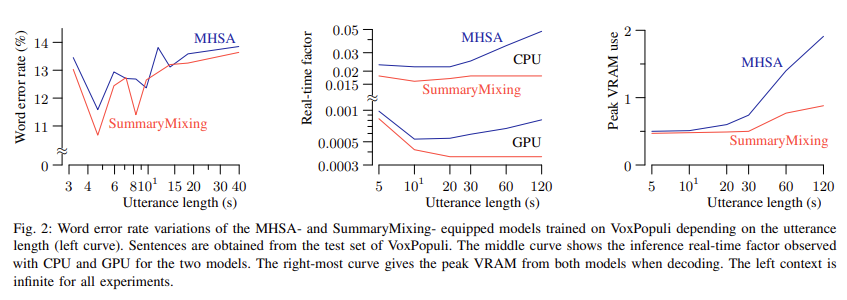
SummaryMixing’s scalability and effectivity make it a great answer for real-time ASR functions. The tactic’s linear time complexity ensures it might probably course of lengthy sequences with out the exponential improve in computational prices related to conventional self-attention mechanisms. Along with enhancing WER and lowering reminiscence utilization, SummaryMixing’s capability to deal with each streaming and non-streaming duties with a unified mannequin structure simplifies the deployment of ASR techniques throughout totally different use circumstances. Integrating dynamic chunk coaching and convolution additional enhances the mannequin’s capability to function effectively in real-time environments, making it a sensible answer for contemporary ASR wants.

In conclusion, SummaryMixing represents a big development in ASR know-how by addressing the important thing challenges of processing effectivity, reminiscence consumption, and accuracy. This technique considerably improves self-attention mechanisms by lowering time complexity from quadratic to linear. The Librispeech and Voxpopuli datasets reveal that SummaryMixing outperforms conventional strategies and scales properly throughout numerous speech recognition duties. The discount in computational and reminiscence necessities makes it appropriate for deployment in resource-constrained environments, providing a promising answer for the way forward for ASR in real-time and offline functions.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.