

Synthetic intelligence (AI) has made vital strides in recent times, particularly with the event of large-scale language fashions. These fashions, skilled on large datasets like web textual content, have proven spectacular skills in knowledge-based duties comparable to answering questions, summarizing content material, and understanding directions. Nevertheless, regardless of their success, these fashions need assistance relating to specialised domains the place knowledge is scarce or extremely particular. Coaching these fashions to carry out nicely in area of interest areas stays a major hurdle, with solely a small quantity of textual content obtainable.
A central drawback in AI analysis is the inefficient manner fashions purchase information from small datasets. Present fashions want publicity to 1000’s of variations of the identical truth to be taught it successfully. This poses an issue when a truth seems solely a couple of times in a specialised corpus, making it tough for fashions to grasp and generalize from such restricted info. This inefficiency is much more pronounced when adapting a basic language mannequin to a brand new, domain-specific subject the place numerous representations of key ideas are absent.
Present AI strategies try to handle this concern via pretraining on large datasets, which supplies fashions a broad understanding of basic subjects. Nevertheless, this method is ineffective for domains with solely a small corpus of data. Some researchers have tried to unravel this by paraphrasing the unique textual content a number of instances to create numerous representations. Nevertheless, this methodology, although easy, wants extra skill to introduce new views or deepen understanding. After just a few rounds of rephrasing, the mannequin’s efficiency tends to plateau, as rephrasing alone doesn’t present sufficient variation for vital studying enhancements.
Researchers from Stanford College launched EntiGraph, an revolutionary method to fixing this drawback via artificial knowledge technology. The group, comprised of members from the Division of Statistics and the Division of Laptop Science, developed EntiGraph to generate a big, artificial corpus from a small, domain-specific dataset. The objective is to assist fashions be taught extra successfully by offering a higher range of examples. EntiGraph identifies key entities inside the authentic textual content after which makes use of a language mannequin to generate new, different content material across the relationships between these entities. This methodology permits the creation of a various coaching set, even from a small quantity of knowledge.
EntiGraph begins by extracting vital entities from a given dataset. Entities could be folks, locations, or ideas central to the textual content. After figuring out these entities, the algorithm makes use of a language mannequin to explain their relationships. These descriptions are then mixed into an artificial dataset that expands the unique corpus, offering the language mannequin with a a lot bigger and richer coaching knowledge set. This course of permits the language mannequin to be taught connections between entities in methods not current within the authentic textual content, main to raised information acquisition. Moreover, EntiGraph organizes these relationships right into a information graph, which permits additional exploration of how totally different entities work together inside the dataset.
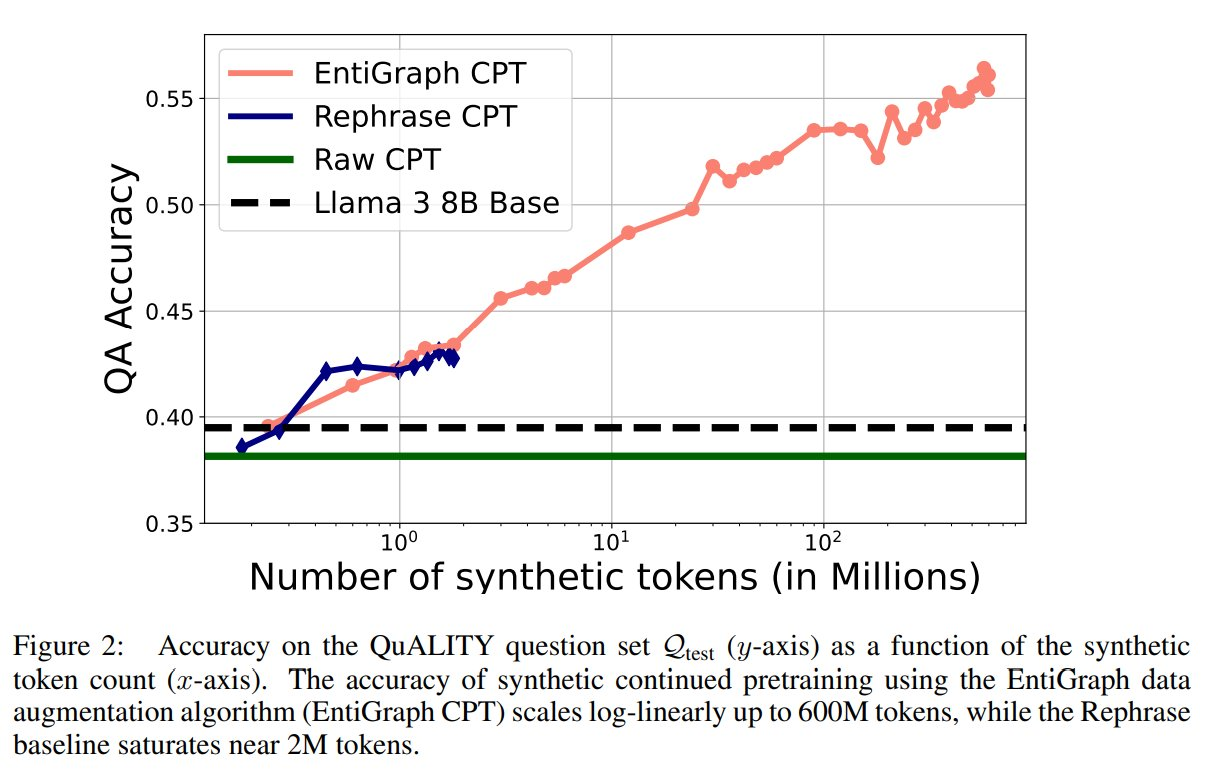
The efficiency of EntiGraph was examined in a collection of experiments, and the outcomes had been promising. The researchers took a corpus of 1.3 million tokens and used EntiGraph to generate an artificial dataset containing 600 million tokens. They then pretrained a language mannequin, Llama 3 8B, on this bigger dataset. The outcomes confirmed a log-linear enchancment in accuracy because the variety of artificial tokens elevated. As an illustration, the mannequin’s accuracy in question-answering duties improved from 39.49% when utilizing the unique dataset to 56.42% after pretraining on the artificial corpus. Furthermore, the artificial pretraining utilizing EntiGraph supplied as much as 80% of the accuracy increase that fashions obtain once they can entry the unique paperwork throughout inference. This exhibits that even with out entry to the unique knowledge, fashions can carry out nicely after coaching on an artificial corpus.
The examine additionally revealed that EntiGraph outperforms current strategies, comparable to merely rephrasing the dataset. In a single comparability, the rephrased corpus contained only one.8 million tokens, and the mannequin’s accuracy plateaued at 43.08%. In distinction, EntiGraph improved mannequin efficiency even because the artificial dataset grew to 600 million tokens. The flexibility to synthesize bigger and extra numerous datasets allowed for simpler information switch, demonstrating the prevalence of this methodology in enabling language fashions to be taught from small, specialised datasets.
In conclusion, the introduction of EntiGraph marks a major development in addressing the challenges of knowledge effectivity in AI fashions. The tactic efficiently generates a various, artificial corpus from a small dataset, enabling fashions to amass domain-specific information extra successfully. This analysis highlights a novel method that would result in additional developments in AI coaching methods, notably for specialised fields the place knowledge is restricted. The outcomes present that EntiGraph offers a viable answer to overcoming the constraints of current strategies, permitting language fashions to raised adapt to area of interest domains and carry out complicated duties with improved accuracy.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.