{kind=link}

The power to precisely interpret advanced visible info is an important focus of multimodal giant language fashions (MLLMs). Current work reveals that enhanced visible notion considerably reduces hallucinations and improves efficiency on resolution-sensitive duties, resembling optical character recognition and doc evaluation. A number of latest MLLMs obtain this by using a mix of imaginative and prescient encoders. Regardless of their success, there’s a lack of systematic comparisons and detailed ablation research addressing important elements, resembling knowledgeable choice and the combination of a number of imaginative and prescient specialists. This text supplies an in depth exploration of the design area for MLLMs utilizing a mix of imaginative and prescient encoders and resolutions, the Eagle framework that makes an attempt to discover the design area for multimodal giant language fashions with a mix of encoders. The findings reveal a number of underlying rules frequent to varied current methods, resulting in a streamlined but efficient design method. Eagle discovers that merely concatenating visible tokens from a set of complementary imaginative and prescient encoders is as efficient as extra advanced mixing architectures or methods. Moreover, Eagle introduces Pre-Alignment to bridge the hole between vision-focused encoders and language tokens, enhancing mannequin coherence. The ensuing household of MLLMs, Eagle, surpasses different main open-source fashions on main MLLM benchmarks.
Eagle’s work is said to the final structure design of multimodal giant language fashions (MLLMs). Moreover the road of consultant open-source analysis talked about earlier, different notable households of MLLMs embody, however aren’t restricted to, MiniGPT-4, Lynx, Otter, QwenVL, CogVLM, VILA, GPT-4V, Gemini, and Llama 3.1. Relying on how imaginative and prescient alerts are built-in into the language mannequin, MLLMs may be broadly categorized into “cross-modal consideration” fashions and “prefix-tuning” fashions. The previous injects visible info into totally different layers of LLMs utilizing cross-modal consideration, whereas the latter treats the visible tokens as a part of the language token sequence and immediately appends them with textual content embeddings. Eagle’s mannequin belongs to the prefix-tuning household by following a LLaVA-styled multimodal structure. Contemplating that MLLM is a fast-growing discipline, Eagle recommends referring to extra detailed research and surveys for additional insights.
Eagle’s work is carefully associated to analysis targeted on bettering imaginative and prescient encoder designs for MLLMs. Early works often adopted imaginative and prescient encoders pre-trained on vision-language alignment duties resembling CLIP and EVA-CLIP. Stronger imaginative and prescient encoders, resembling SigLIP and InternVL, have been proposed to reinforce vision-language duties with higher designs, bigger mannequin sizes, and more practical coaching recipes. Since fashions are sometimes pre-trained on low-resolution photos and will lack the flexibility to encode fine-grained particulars, larger decision adaptation is incessantly carried out to extend the MLLM enter decision. Along with larger decision adaptation, fashions like LLaVA-NeXT, LLaVA-UHD, Monkey, InternLM-XComposer, and InternVL use tiling or adaptive tiling to deal with high-resolution enter, the place photos are divided into lower-resolution patches and processed individually. Whereas the flexibility to deal with larger decision is made attainable by introducing extra imaginative and prescient specialists, this method differs barely from tiling strategies, although each are appropriate and may be mixed.
The success of huge language fashions (LLMs) has sparked vital curiosity in enabling their visible notion capabilities, permitting them to see, perceive, and purpose in the true world. On the core of those multimodal giant language fashions (MLLMs) is a typical design the place photos are transformed right into a sequence of visible tokens by the imaginative and prescient encoders and appended with the textual content embeddings. CLIP is commonly chosen because the imaginative and prescient encoder as a result of its visible illustration is aligned with the textual content area by pre-training on image-text pairs. Relying on the architectures, coaching recipes, and the way in which imaginative and prescient tokens are injected into the language mannequin, notable households of MLLMs embody Flamingo, BLIP, PaLI, PaLM-E, and LLaVA. Most of those fashions preserve comparatively low enter resolutions as a result of limitations in pre-trained imaginative and prescient encoders and LLM sequence size. Eagle’s work is carefully aligned with fashions that use a number of imaginative and prescient encoders for improved notion. Mini-Gemini and LLaVA-HR suggest fusing high-resolution visible options into low-resolution visible tokens. Past decision points, these pre-trained imaginative and prescient encoders might lack particular capabilities resembling studying textual content or localizing objects. To handle this, varied fashions combine imaginative and prescient encoders pre-trained on totally different imaginative and prescient duties to reinforce the imaginative and prescient encoder’s capabilities.
As an example, fashions like Mousi and Courageous fuse visible tokens from totally different imaginative and prescient encoders by concatenating alongside the channel or token path. RADIO introduces a multi-teacher distillation methodology to unify the talents of various imaginative and prescient encoders right into a single mannequin. MoAI, IVE, and Prismer additional use the output of imaginative and prescient specialists, resembling OCR, detection, or depth estimation, to complement extra info for MLLMs to generate solutions. MoVA devises a routing community to assign an optimum imaginative and prescient mannequin primarily based on the given picture and directions.
Current research have proven that stronger imaginative and prescient encoder designs are necessary for lowering MLLM hallucinations and bettering efficiency on resolution-sensitive duties like optical character recognition (OCR). A number of works concentrate on enhancing the aptitude of the imaginative and prescient encoder, both by scaling up the pre-training knowledge and parameters or by dividing photos into low-resolution patches. Nonetheless, these approaches typically introduce giant coaching useful resource calls for. An environment friendly but highly effective technique is mixing visible encoders pre-trained with totally different duties and enter resolutions, both by fusing larger decision encoders with the CLIP encoder, sequentially appending options from totally different encoders, or adopting extra advanced fusion and routing methods to maximise the advantages of various encoders. This “mixture-of-vision-experts” method has confirmed efficient, although an in depth examine of its design area with rigorous ablation continues to be missing, motivating Eagle to revisit this space. Key questions stay: which imaginative and prescient encoder combos to decide on, how you can fuse totally different specialists, and how you can regulate coaching methods with extra imaginative and prescient encoders.
To handle these questions, Eagle systematically investigates the mixture-of-vision-encoders design area for improved MLLM notion. The exploration of this design area includes the next steps: 1) Benchmarking varied imaginative and prescient encoders and trying to find larger decision adaptation; 2) Conducting an “apples to apples” comparability between imaginative and prescient encoder fusion methods; 3) Progressively figuring out the optimum mixture of a number of imaginative and prescient encoders; 4) Enhancing imaginative and prescient knowledgeable pre-alignment and knowledge combination. The exploration steps are illustrated within the following picture.
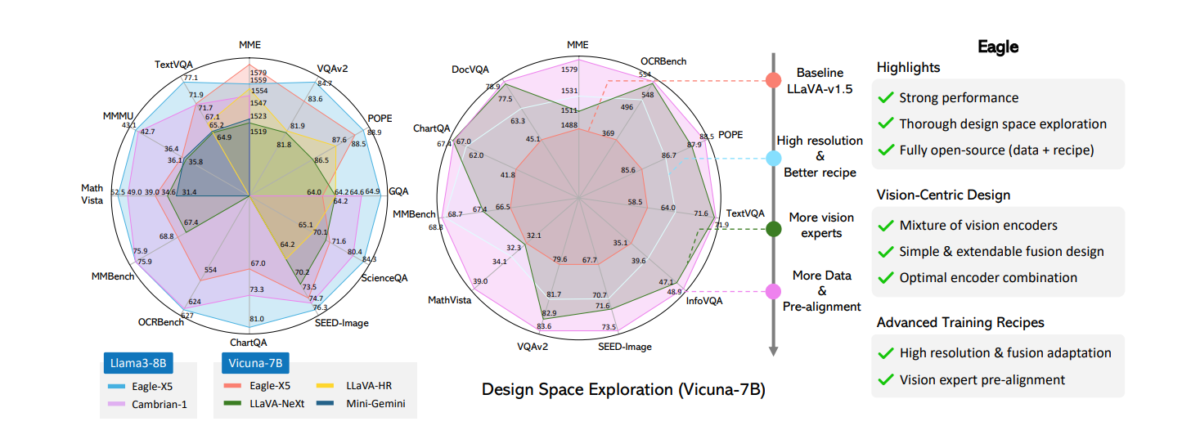
Eagle’s examine covers the efficiency of imaginative and prescient encoders pre-trained on totally different duties and resolutions, resembling vision-language alignment, self-supervised studying, detection, segmentation, and OCR. Utilizing a round-robin method, Eagle begins with the fundamental CLIP encoder and provides one extra knowledgeable at a time, choosing the knowledgeable that gives the very best enchancment in every spherical.
Whereas Eagle’s work will not be the primary to leverage a number of imaginative and prescient encoders in MLLMs, the systematic examine results in a number of key findings underneath this setting:
- Unlocking the imaginative and prescient encoders throughout MLLM coaching issues. That is in distinction to fashions like LLaVA and others that contemplate a number of imaginative and prescient encoders or lecturers, the place freezing the imaginative and prescient encoders has been frequent observe.
- Some lately proposed fusion methods don’t present vital benefits. As a substitute, easy channel concatenation emerges as a easy but aggressive fusion technique, providing the very best effectivity and efficiency.
- Incorporating extra imaginative and prescient specialists results in constant beneficial properties. This makes it a promising path for systematically enhancing MLLM notion, other than scaling up single encoders. The advance is especially pronounced when imaginative and prescient encoders are unlocked.
- Pre-alignment stage is essential. Eagle introduces a pre-alignment stage the place non-text-aligned imaginative and prescient specialists are individually fine-tuned with a frozen LLM earlier than being educated collectively. This stage considerably enhances MLLM efficiency underneath the mixture-of-vision-encoder design.
Eagle: Methodology and Structure
In contrast to earlier strategies that concentrate on new fusion methods or architectures amongst imaginative and prescient encoders, Eagle’s purpose is to establish a minimalistic design to fuse totally different imaginative and prescient encoders, supported by detailed ablations and eradicating any pointless parts. As proven within the following determine, Eagle begins by extending the fundamental CLIP encoder to a set of imaginative and prescient specialists with totally different architectures, pre-training duties, and resolutions. With these specialists, Eagle then compares totally different fusion architectures and strategies and explores how you can optimize pre-training methods with a number of encoders.

Lastly, Eagle combines all of the findings and extends the method to a number of knowledgeable imaginative and prescient encoders with various resolutions and area data. Utilizing the identical pre-training knowledge as LLaVA-1.5, which consists of 595k image-text pairs, Eagle strikes to the supervised fine-tuning stage by amassing knowledge from a sequence of duties and changing them into multimodal conversations, together with LLaVA-1.5, Laion-GPT4V, ShareGPT-4V, DocVQA, synDog-EN, ChartQA, DVQA, and AI2D, leading to 934k samples.
The mannequin is first pre-trained with image-text pairs for one epoch with a batch dimension of 256, the place the whole mannequin is frozen, and solely the projector layer is up to date. Within the second stage, the mannequin is fine-tuned on the supervised fine-tuning knowledge for one epoch with a batch dimension of 128. For this exploration, Eagle employs Vicuna-7B because the underlying language mannequin. The training charges are set to 1e-3 for the primary stage and 2e-5 for the second stage.
Stronger CLIP Encoder
Eagle begins the exploration with the CLIP mannequin, because it has change into the first selection for a lot of MLLMs. Whereas CLIP fashions are recognized to reinforce multimodal duties, their limitations have additionally been well-documented. For instance, many current MLLMs have a tendency to make use of the pre-trained CLIP resolutions (resembling 224 × 224 or 336 × 336) as their enter resolutions. In these instances, the encoders typically battle to seize fine-grained particulars necessary for resolution-sensitive duties like OCR and doc understanding.
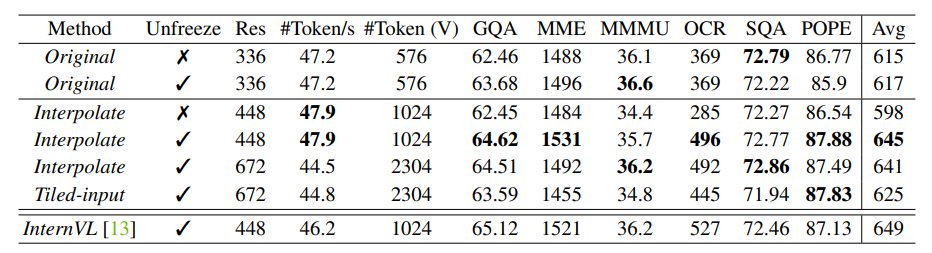
To deal with elevated enter decision, a standard method is tiling, the place enter photos are divided into tiles and encoded individually. One other less complicated methodology is to immediately scale up the enter decision and interpolate the place embeddings of the imaginative and prescient transformer mannequin if vital. Eagle compares these two approaches with frozen and unfrozen imaginative and prescient encoders throughout totally different resolutions, with the outcomes contained within the above desk. The findings may be summarized as follows:
- Unfreezing the CLIP encoder results in vital enchancment when interpolating to the next MLLM enter decision that differs from the CLIP pre-training decision, with out efficiency degradation when resolutions stay the identical.
- Freezing the CLIP encoder and immediately adapting it to the next MLLM enter decision considerably harms efficiency.
- Among the many methods in contrast, immediately interpolating to 448 × 448 with an unfrozen CLIP encoder proves to be each efficient and environment friendly by way of efficiency and price.
- The perfect CLIP encoder achieves efficiency near InternVL, regardless of being a a lot smaller mannequin (300M vs. 6B) with much less pre-training knowledge.
It’s price noting that CLIP-448 permits Eagle to match the setting with LLaVA-HR and InternVL, the place the CLIP encoders are equally tailored to take 448 × 448 enter and output 1024 patch tokens. For additional investigation, Eagle follows this easy technique of scaling up the enter decision and unlocking the imaginative and prescient encoder throughout coaching.

Eagle observes that current in style fusion methods, regardless of their design variations, may be broadly categorized as follows:
- Sequence Append: Instantly appending the visible tokens from totally different backbones as an extended sequence.
- Channel Concatenation: Concatenating the visible tokens alongside the channel dimension with out growing the sequence size.
- LLaVA-HR: Injecting high-resolution options into low-resolution imaginative and prescient encoders utilizing a mixture-of-resolution adapter.
- Mini-Gemini: Utilizing the CLIP tokens as low-resolution queries to cross-attend one other high-resolution imaginative and prescient encoder in co-located native home windows.
- Deformable Consideration: A brand new baseline launched on prime of Mini-Gemini, the place the vanilla window consideration is changed with deformable consideration.
As a substitute of coaching a projector to concurrently align a number of imaginative and prescient specialists as in LLaVA’s authentic pre-training technique, we first align the illustration of every particular person knowledgeable with a smaller language mannequin (Vicuna-7B in observe) utilizing next-token-prediction supervision. As proven within the determine beneath, with pre-alignment, the entire coaching course of consists of three steps: 1) coaching every pre-trained imaginative and prescient knowledgeable with their very own projector on SFT knowledge, whereas conserving the language mannequin frozen; 2) combining all of the imaginative and prescient specialists from step one and coaching solely the projector with image-text pairs knowledge; 3) coaching the entire mannequin on the SFT knowledge.

Eagle: Experiments and Outcomes
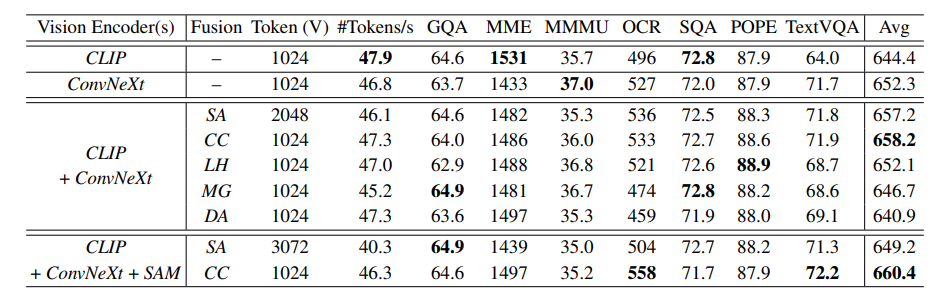
After meticulously growing its methods, Eagle has established the next rules for the mannequin: (1) integrating extra imaginative and prescient specialists with an optimized coaching recipe; (2) combining a number of imaginative and prescient specialists by direct channel concatenation; (3) pre-training the imaginative and prescient specialists individually by way of pre-alignment. On this part, to additional display the benefits of the Eagle fashions, extra coaching knowledge is included, and Eagle is in contrast towards the present state-of-the-art MLLMs throughout varied duties. Eagle makes use of Vicuna-v1.5-7B, Llama3-8B, and Vicuna-v1.5-13B because the language fashions. For the imaginative and prescient encoders, primarily based on the leads to Part 2.6, Eagle fashions are denoted as Eagle-X4, which incorporates 4 imaginative and prescient encoders: CLIP, ConvNeXt, Pix2Struct, and EVA-02, and Eagle-X5, which incorporates a further SAM imaginative and prescient encoder.
Visible Query Answering Duties
Eagle compares the mannequin sequence throughout three Visible Query Answering (VQA) benchmarks, together with GQA, VQAv2, and VizWiz. As proven within the following desk, Eagle-X5 achieves state-of-the-art efficiency on GQA and VQAv2, highlighting the benefits of incorporating extra imaginative and prescient specialists.

OCR and Chart Understanding Duties
To guage the OCR, doc, and chart understanding capabilities of Eagle, the mannequin is benchmarked on OCRBench, TextVQA, and ChartQA. As proven within the above desk, Eagle considerably surpasses opponents on TextVQA, benefiting from its high-resolution structure and integration of various imaginative and prescient encoders. Notably, Eagle maintains a simple design, supporting as much as 1024 tokens with out requiring advanced tile decomposition of photos.
The determine beneath presents examples of OCR and doc understanding instances. With high-resolution adaptation and the inclusion of extra imaginative and prescient specialists, Eagle can establish small textual content inside photos and precisely extract info primarily based on consumer directions.

To raised perceive the advantages of introducing specialists pre-trained on different imaginative and prescient duties, the next determine visualizes outcomes from a mannequin with solely the ConvNeXt and CLIP imaginative and prescient encoders, in comparison with the outcomes of Eagle-X5. With the total set of imaginative and prescient encoders, the mannequin efficiently corrects errors, demonstrating that even when outfitted with high-resolution imaginative and prescient encoders pre-trained on vision-language alignment, Eagle’s capabilities are additional enhanced by integrating extra imaginative and prescient specialists pre-trained on various imaginative and prescient duties.

Multimodal Benchmark Analysis
Eagle is evaluated on seven benchmarks for MLLMs to display its capabilities from totally different views, together with MME, MMBench, SEED, MathVista, MMMU, ScienceQA, and POPE. Particularly, MME, MMBench, and SEED assess the general efficiency on varied real-world duties involving reasoning, recognition, data, and OCR. MMMU focuses on difficult issues from various domains that require college-level data. POPE evaluates the visible hallucinations of MLLMs. The metrics used on this analysis adhere to the default settings of those benchmarks. Eagle experiences the notion rating for MME, the en_dev cut up for MMBench, the picture cut up of SEED, the test-mini cut up of MathVista, the val cut up of MMMU, the F1-score of POPE, and the picture rating for ScienceQA, guaranteeing alignment with the reported scores from different fashions.

Remaining Ideas
On this article, we now have talked about Eagle, an in-depth evaluation of the design area for integrating imaginative and prescient encoders into multimodal giant language fashions. In contrast to earlier works that concentrate on designing novel fusion paradigms, Eagle finds that systematic design decisions matter and discovers a sequence of helpful strategies. Step-by-step, Eagle optimizes the coaching recipe of particular person imaginative and prescient encoders, identifies an extendable and environment friendly fusion methodology, and steadily combines imaginative and prescient encoders with totally different area data. The outcomes spotlight the important significance of primary design area concerns.

