{kind=link}

Machine studying has made vital developments, significantly via deep studying methods. These developments rely closely on optimization algorithms to coach large-scale fashions for varied duties, together with language processing and picture classification. On the core of this course of lies the problem of minimizing advanced, non-convex loss features. Optimization algorithms like Stochastic Gradient Descent (SGD) & its adaptive variants have develop into important to this endeavor. Such strategies purpose to iteratively alter mannequin parameters to attenuate errors throughout coaching, making certain that fashions can generalize nicely on unseen knowledge. Nonetheless, whereas these optimization methods have confirmed helpful, there stays vital room for enchancment in how they deal with long-term gradient info.
A elementary problem in coaching massive neural networks is the efficient use of gradients, which give the mandatory updates for optimizing mannequin parameters. Conventional optimizers like Adam and AdamW rely closely on an Exponential Shifting Common (EMA) of current gradients, emphasizing essentially the most present gradient info whereas discarding older gradients. This strategy works nicely for fashions the place current adjustments maintain extra significance. Nonetheless, this may be problematic for bigger fashions and lengthy coaching cycles, as older gradients usually nonetheless comprise useful info. In consequence, the optimization course of could also be much less environment friendly, requiring longer coaching durations or failing to achieve the very best options.
In present optimization strategies, significantly Adam and AdamW, utilizing a single EMA for previous gradients can restrict the optimizer’s means to seize a full spectrum of gradient historical past. These strategies can adapt shortly to current adjustments however usually want extra useful info from older gradients. Researchers have explored a number of approaches to handle this limitation, but many optimizers nonetheless battle to search out the optimum stability between incorporating current and previous gradients successfully. This shortcoming may end up in suboptimal convergence charges and poorer mannequin efficiency, particularly in large-scale coaching eventualities like language fashions or imaginative and prescient transformers.
Researchers from Apple and EPFL launched a brand new strategy to this drawback with the AdEMAMix optimizer. Their methodology extends the normal Adam optimizer by incorporating a combination of two EMAs, one fast-changing and one slow-changing. This strategy permits the optimizer to stability the necessity to answer current updates whereas retaining useful older gradients usually discarded by current optimizers. This dual-EMA system, distinctive to AdEMAMix, permits extra environment friendly coaching of large-scale fashions, decreasing the whole variety of tokens wanted for coaching whereas reaching comparable or higher outcomes.
The AdEMAMix optimizer introduces a second EMA to seize older gradients with out dropping the reactivity supplied by the unique EMA. Particularly, AdEMAMix maintains a fast-moving EMA that prioritizes current gradients whereas monitoring a slower-moving EMA that retains info a lot earlier within the coaching course of. For instance, when coaching a 1.3 billion-parameter language mannequin on the RedPajama dataset, the researchers discovered that AdEMAMix may match the efficiency of an AdamW mannequin skilled on 197 billion tokens with solely 101 billion tokens, a discount of roughly 95% in token utilization. This effectivity acquire interprets into sooner convergence and sometimes higher minima, permitting fashions to achieve superior efficiency with fewer computational sources.

Efficiency evaluations of AdEMAMix have demonstrated substantial enhancements in velocity and accuracy over current optimizers. In a single key experiment, a 110 million-parameter mannequin skilled with AdEMAMix reached comparable loss values as an AdamW mannequin that required practically twice the variety of coaching iterations. Particularly, the AdEMAMix mannequin, skilled for 256,000 iterations, achieved the identical outcomes as an AdamW mannequin skilled for 500,000 iterations. For even bigger fashions, such because the 1.3 billion-parameter language mannequin, AdEMAMix delivered comparable outcomes to an AdamW mannequin skilled for 1.5 million iterations however with 51% fewer tokens. The optimizer additionally demonstrated a slower price of forgetting, which is a important benefit in sustaining mannequin accuracy over lengthy coaching cycles.
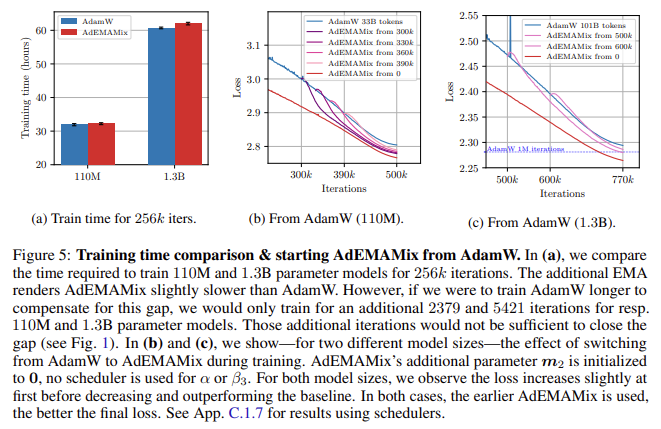
The researchers additionally addressed some widespread challenges optimizers face, corresponding to early coaching instabilities. To beat these, they launched warmup steps for the bigger of the 2 EMAs, progressively rising the worth of the slow-changing EMA all through coaching. This gradual improve helps stabilize the mannequin through the preliminary coaching section, stopping the optimizer from prematurely relying too closely on outdated gradients. By fastidiously scheduling the changes for the 2 EMAs, AdEMAMix ensures that the optimization course of stays secure and environment friendly all through coaching, even for fashions with tens of billions of parameters.

In conclusion, the AdEMAMix optimizer presents a notable development in machine studying optimization. Incorporating two EMAs to leverage each current and older gradients higher addresses a key limitation of conventional optimizers like Adam and AdamW. This dual-EMA strategy permits fashions to realize sooner convergence with fewer tokens, decreasing the computational burden of coaching massive fashions; AdEMAMix persistently outperformed A in trialsdamW, demonstrating its potential to enhance efficiency in language modeling and picture classification duties. The strategy’s means to scale back mannequin forgetting throughout coaching additional underscores its worth for large-scale, long-term ML initiatives, making it a strong device for researchers and business.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and LinkedIn. Be part of our Telegram Channel.
In the event you like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.