{kind=link}

Segmentation tasks are the cornerstone of personalization in video games. Personalization of the participant expertise helps maximize participant engagement, mitigate churn and enhance participant spend. Personalization mechanisms are available many types together with subsequent greatest supply, in-game retailer ordering, issue setting, matchmaking, signposting, advertising and reengagement. Ideally every participant’s expertise could be distinctive however this is not possible. Instead, we group gamers throughout a sequence of information factors after which personalize that group’s expertise.
On this resolution accelerator we first leverage an LLM to assist decide the correct variety of clusters for a given dataset. We then use normal, explainable, machine studying methods, like Ok-means clustering. Explainability is necessary so we are able to construct belief within the clusters, and might perceive why a choice was made for a particular participant. As soon as our clusters are created, we leverage an LLM to explain them enabling events to utilize them.
Heuristics versus ML based mostly segmentation
Primary heuristic based mostly segmentation is easy. Many recreation corporations will do that and name it a day. Payer vs non-payer, logged in inside the final two weeks, PVP vs PVE and the likes are straightforward to calculate, talk and make use of however solely scratch the floor. For personalization tasks to be efficient, deeper perception is required. Understanding a gaggle of participant’s habits, their play model, social engagement and interactions with content material inside the recreation supplies perception wanted to maximise their play expertise.
Non-heuristic segmentation tasks are onerous, gradual and time consuming. Clustering on a set of information factors is not troublesome. Making sense of these clusters, what they inform you and learn how to use them, nevertheless, is a difficult human-in-the-middle downside. We encounter groups spending weeks on a segmentation effort, finally canceling it, or taking 6 months solely to seek out that the clusters are not significant. These outcomes happen as a result of analysts have to find out what makes the generated clusters distinctive. They then have to explain what the cluster means and when to make use of it. To do that successfully the variety of clusters needs to be saved small (3-4) as discovering variations between a bigger set of segments is commonly nuanced. This could result in overfitting, grouping dissimilar folks, inflicting your personalization efforts to fall flat.
Why iteration issues in segmentation tasks
To additional complicate issues your cluster make-up will change over time on account of new recreation content material, new audiences becoming a member of the sport, modifications enacted upon the economic system, your viewers altering its wishes, or the sport reaching a gradual state. Segmentation tasks are a steady effort, one which wants optimization. Maintaining with that change when these tasks require a lot effort is a problem for studios. Studios will due to this fact typically phase as soon as and use the segments longer than they’re acceptable. By benefiting from a contemporary method you may additional construct upon your instinct.
Cluster function analysis
As you take into account which options to make use of in your clustering, you’ll depend on your deep data of your datasets, and gamers, and will leverage instruments like a correlation matrix to reduce extremely correlated options. As with figuring out the variety of clusters to contemplate, you may leverage an LLM to make suggestions on account of these information factors and supply you enter as to which options to maintain, or take away from, your clustering.
Utilizing a correlation matrix to filter options
It is necessary to make sure that the options included aren’t inflicting overfitting, or noise inside your clusters. We accomplish this by consulting a correlation matrix and eliminating options which are extremely correlated to one another. For example, we could say a recreation the place you earn and spend gold with completely different factions to enhance your fame and progress the sport. As a participant progresses inside the recreation, they will accumulate that gold. Gold accumulation due to this fact supplies little extra info than “time performed” and little differentiation between gamers. Together with gold accumulation, as an entire, will trigger your gamers to begin to look extra comparable, and it is the variations you’re in search of. What may be a greater differentiator is with which faction they spent their gold. Should you embody complete gold gathered, complete gold spent and gold spent per faction you may muddy your outcomes. Taken additional, it’s probably extra helpful to contemplate how a lot gold was gathered inside every of your recreation loops. Along with bettering your output, the sort of evaluation can shrink the quantity of processing wanted and information factors thought of in your clusters. By optimizing on this approach you’ll present sooner and extra helpful outcomes.
We will manually have a look at the correlation matrix under and see what we study from it. As this information is generated, the precise correlations do not mirror actuality and could also be nonsense. Placing that apart, for the aim of our clustering effort there’s two items of knowledge we’re in search of: Which information factors are unrelated to one another (closest to zero), which of them are most correlated and will muddy our clusters (closest to 1 or -1). As an apart: Seeing which of them are closest to 1 and -1 can present attention-grabbing perception on your workforce, unrelated to segmentation. Whereas this information is nonsense, think about it weren’t. We might see on this matrix that the extra we offer free premium credit, the much less premium credit a person purchases.
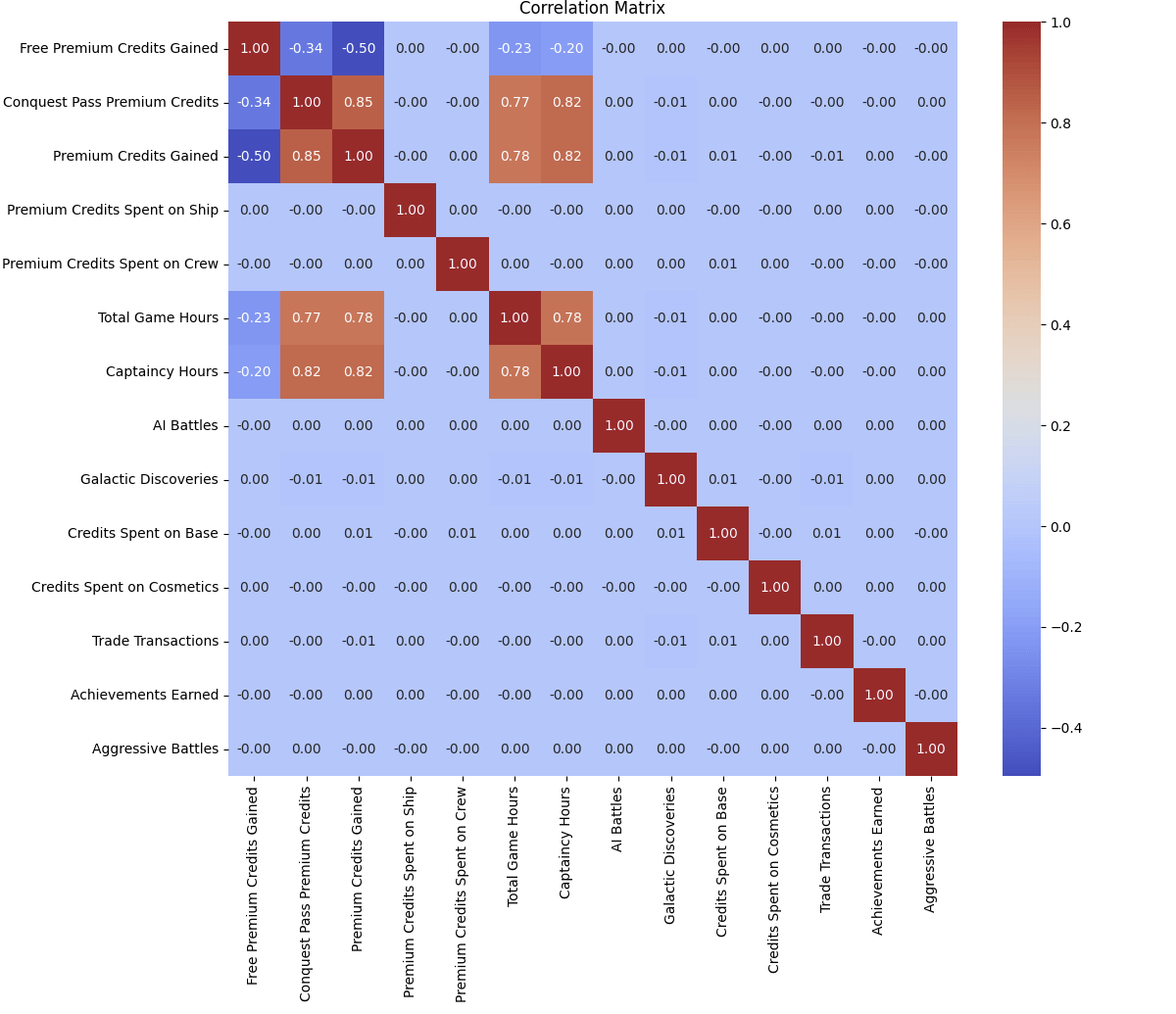
That is one other instance of the place an LLM will help us discover perception. After we ask the LLM to clarify what we’re seeing above it pulls out some attention-grabbing issues that we did not discover when reviewing ourselves. The under picture exhibits the output on this particular case. By studying by way of it we see a number of options the place we should always use one, or the opposite, however not each. The reason additionally means that we leverage Aggressive Battles and Commerce Transactions in our clusters as they aren’t correlated to different options. Lastly we see an instance of why together with values is necessary, because the third extremely correlated function is not actually that correlated!

We’re now able to cluster your dataset. There are numerous clustering fashions on the market, however as a rule Ok-Means is used. No matter mannequin is used, it is very important select one that’s explainable.
Figuring out the correct variety of clusters
As you cluster your gamers based mostly on the options that you simply selected above you’ll want to decide the variety of clusters you need to have. You’ll run your clustering with 2, 3, 4, 5, and so forth. to seek out one of the best quantity on your information. For this we leverage the Silhouette technique, defined additional within the resolution accelerator. As the info we have used is generated information, the Silhouette rating, and elbow, are extremely pronounced. Your output could look fairly completely different. The purpose is to get your Silhouette Rating as near 1 as your information will enable, you might have to iterate on which options you’ve got added, or not added to your clustering effort.
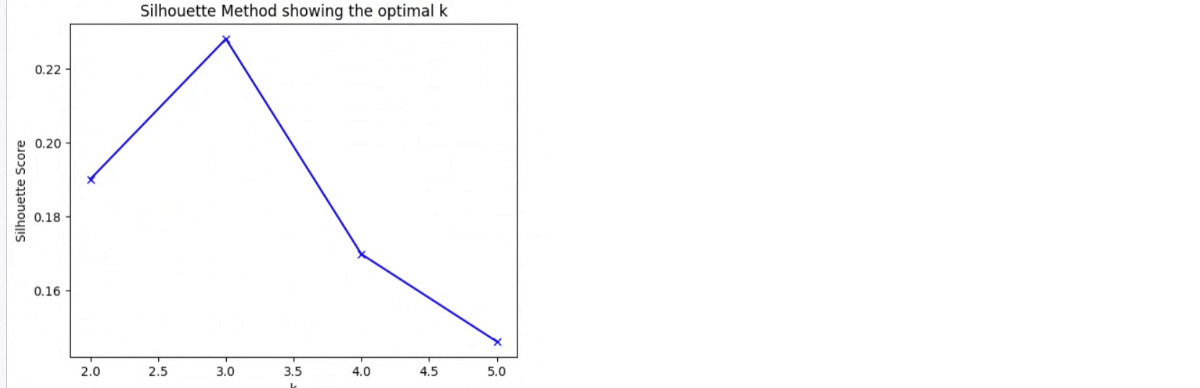
Populations might be advanced and you would be taking a look at 20 or extra figures making an attempt to find out the optimum variety of clusters. Through the use of an LLM to assist with this, you’ve a programmatic and scalable option to make this determination. You’ll be able to all the time override the LLM’s determination you probably have exterior perception so as to add. Think about you wished to cluster gamers who’ve performed for <30 days, 30-120, and 120+ to see how they differ. Whereas we might guess, and put 3 clusters in every group, we might leverage an LLM to help. Doing so we could discover that 4, 2 and three are the correct variety of clusters. As soon as once more the LLM has helped free analysts to concentrate on different duties.
You could discover that your clusters should not coming collectively, maybe as a result of too many unrelated options are being thought of. There are numerous approaches to contemplate and that is the place iteration begins. You could re-evaluate the options included in your mannequin, or take into account creating a number of units of clusters centered on narrower datasets will help. One other factor to guage is whether or not creating (sub)segments inside of a bigger phase would assist. For instance, taking a effectively outlined phase equivalent to Paying Buyer, leaving out non-payers, and segmenting simply your payers.
We’ve got iterated and are comfy with our clusters, it’s time to outline your clusters. To make these clusters helpful we want to have the ability to perceive what the clusters imply, and the way its members had been decided. In our pocket book we output the metrics and metadata output right into a Delta Desk.
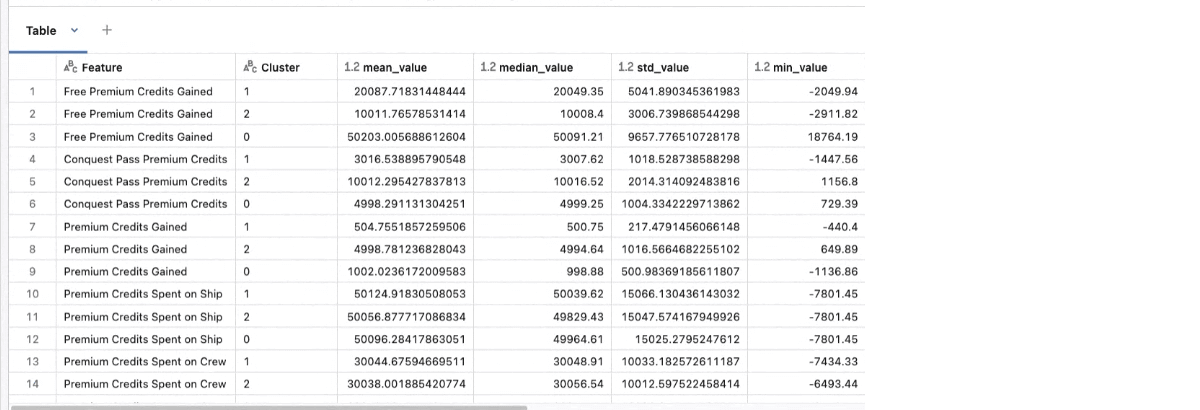
We’d then use field plots wanting on the metrics to seek out patterns in that information. Discovering these patterns throughout 40 field plots might be onerous on the eyes and time consuming. As such, we take an LLM and have it summarize the knowledge discovered within the desk and make our lives simpler.

The introduction of LLMs as a option to streamline human-in-the-middle evaluation is an thrilling improvement for recreation analytics. By automating components of your analytics pipeline with LLMs you’ll be able to increase your information workforce, speed up your time to worth for analytics tasks and supply your workforce extra time to work on further excessive worth tasks. This is only one instance of a use case that may profit from the mix of conventional machine studying and Generative AI. This method might be utilized inside any workflow the place optimization and software of well-known heuristics is beneficial. You could even produce other methods in your workflow that could possibly be automated utilizing the identical method.
We hope this weblog will encourage you to ask: How might GenAI assist us with different tasks? For additional particulars on learn how to make the most of this method, and see how straightforward it’s to enhance your personalization tasks, try our resolution accelerator right here. If you would like to study extra about what we’re doing with recreation corporations to higher serve their gamers, discover this, or one other use case please attain out to your account workforce. We stay up for collaborating with you and serving to carry extra play to the world.
Prepared for extra recreation information + AI use instances?
Obtain our Final Information to Sport Information and AI. This complete eBook supplies an in-depth exploration of the important thing subjects surrounding recreation information and AI, from the enterprise worth it supplies to the core use instances for implementation. Whether or not you are a seasoned information veteran or simply beginning out, our information will equip you with the data you’ll want to take your recreation improvement to the following stage.